Matematyczne podstawy teorii projektowania testów. Charakterystyka testów kontrolnych w wychowaniu fizycznym
Przeczytaj także
Opis prezentacji dla poszczególnych slajdów:
1 slajd
Opis slajdu:
2 slajdy
Opis slajdu:
Zwyczajowo nazywa się cechy fizyczne wrodzonymi (genetycznie dziedziczonymi) cechami morfofunkcjonalnymi, dzięki którym możliwa jest fizyczna (materialnie wyrażona) aktywność człowieka, która w pełni przejawia się w celowej aktywności ruchowej. Główne cechy fizyczne to siła, szybkość, wytrzymałość, elastyczność, zwinność.
3 slajdy
Opis slajdu:
Zdolności motoryczne to indywidualne cechy, które określają poziom zdolności motorycznych danej osoby (V. I. Lyakh, 1996). Podstawą zdolności motorycznych osoby są cechy fizyczne, a formą manifestacji są umiejętności i zdolności motoryczne. Zdolności motoryczne obejmują moc, dużą prędkość, prędkość-moc, zdolności koordynacji ruchowej, ogólną i specyficzną wytrzymałość
4 slajdy
Opis slajdu:
Schemat systematyzacji zdolności fizycznych (motorycznych) Zdolności fizyczne (motoryczne) Kondycjonowanie (energetyczne) Moc Kombinacje zdolności kondycyjnych Wytrzymałość Szybkość Elastyczność Koordynacja (informacyjna) CS związane z oddzielnymi grupami działań motorycznych, specjalne CS Specyficzne CS Kombinacje zdolności koordynacyjnych Kombinacje zdolności kondycyjnych i koordynacyjnych
5 slajdów
Opis slajdu:
UZYSKAJ DOKŁADNE INFORMACJE O POZIOMIE ROZWOJU ZDOLNOŚCI RUCHOWYCH / wysoki, średni, niski / TO MOŻLIWE Z POMOCĄ TESTÓW / lub ćwiczeń kontrolnych /.
6 slajdów
Opis slajdu:
Za pomocą testów kontrolnych (testów) możliwe jest ujawnienie bezwzględnych (jawnych) i względnych (ukrytych, ukrytych) wskaźników tych zdolności. Wskaźniki bezwzględne charakteryzują poziom rozwoju określonych zdolności motorycznych bez uwzględniania ich wzajemnego wpływu. Wskaźniki względne pozwalają ocenić przejawy zdolności motorycznych, biorąc pod uwagę ten wpływ.
7 slajdów
Opis slajdu:
Wyżej wymienione zdolności fizyczne można przedstawić jako istniejące potencjalnie, czyli przed rozpoczęciem wykonywania jakiejkolwiek czynności lub czynności ruchowych (można je nazwać zdolnościami potencjalnymi) oraz jako przejawiające się w rzeczywistości na początku (w tym podczas wykonywania testów ruchowych) oraz w proces wykonywania tych czynności (rzeczywiste zdolności fizyczne).
8 slajdów
Opis slajdu:
Z pewną dozą konwencji możemy mówić o zdolnościach ELEMENTARNYCH i fizycznych KOMPLEKSOWYCH zdolnościach fizycznych
9 slajdów
Opis slajdu:
WYNIKI BADAŃ POZWALAJĄ ZRÓŻNICOWAĆ NASTĘPUJĄCE ZDOLNOŚCI FIZYCZNE SPECJALNE SPECYFICZNE OGÓLNE COP
10 slajdów
Opis slajdu:
Szczególne zdolności fizyczne odnoszą się do jednorodnych grup integralnych czynności ruchowych lub czynności: bieganie, ćwiczenia akrobatyczne i gimnastyczne na przyrządzie, rzuty ruchowe, gry sportowe (koszykówka, siatkówka).
11 slajdów
Opis slajdu:
O określonych przejawach zdolności fizycznych można mówić jako o składnikach tworzących ich wewnętrzną strukturę.
12 slajdów
Opis slajdu:
Zatem głównymi składnikami zdolności koordynacyjnych osoby są: umiejętność orientacji, równowagi, reagowania, różnicowania parametrów ruchów; umiejętność rytmu, reorganizacja czynności ruchowych, stabilność przedsionkowa, dobrowolne rozluźnienie mięśni. Te zdolności są specyficzne.
13 slajdów
Opis slajdu:
Za główne składowe struktury zdolności szybkościowych uważa się szybkość reakcji, szybkość pojedynczego ruchu, częstotliwość ruchów oraz szybkość wyrażaną w integralnych czynnościach motorycznych.
14 slajdów
Opis slajdu:
Przejawami zdolności siłowych są: siła statyczna (izometryczna), siła dynamiczna (izotoniczna) - siła wybuchowa, amortyzująca.
15 slajdów
Opis slajdu:
Struktura wytrzymałości jest bardzo złożona: aerobowa, wymagająca do manifestacji tlenowych źródeł energii; beztlenowe (glikolityczne, źródła energii fosforanu kreatyny – bez udziału tlenu); wytrzymałość różnych grup mięśniowych w pozycjach statycznych - wytrzymałość statyczna; wytrzymałość w ćwiczeniach dynamicznych wykonywanych z prędkością 20-90% maksymalnej.
16 slajdów
Opis slajdu:
Przejawy (formy) elastyczności, w których rozróżnia się elastyczność czynną i bierną, są mniej złożone.
17 slajdów
Opis slajdu:
Ogólne zdolności fizyczne należy rozumieć jako potencjalne i zrealizowane możliwości człowieka, które decydują o jego gotowości do skutecznej realizacji czynności ruchowych, różniących się genezą i znaczeniem. Szczególne zdolności fizyczne to zdolności osoby, które determinują jego gotowość do pomyślnej realizacji działań motorycznych o podobnym pochodzeniu i znaczeniu. Dlatego testy dostarczają informacji przede wszystkim o stopniu wykształcenia specjalnych i specyficznych zdolności fizycznych (szybkości, koordynacji, siły, wytrzymałości, gibkości).
18 slajdów
Opis slajdu:
Szczególne zdolności fizyczne to zdolności osoby, które determinują jego gotowość do pomyślnej realizacji działań motorycznych o podobnym pochodzeniu i znaczeniu. Dlatego testy dostarczają informacji przede wszystkim o stopniu wykształcenia specjalnych i specyficznych zdolności fizycznych (szybkości, koordynacji, siły, wytrzymałości, gibkości).
19 slajdów
Opis slajdu:
Zadaniem badań jest identyfikacja poziomów rozwoju zdolności kondycyjnych i koordynacyjnych, ocena jakości gotowości technicznej i taktycznej. Na podstawie wyników testu możliwe jest: porównanie przygotowania zarówno poszczególnych uczniów, jak i całych grup mieszkających w różnych regionach i krajach; przeprowadzenie selekcji sportowej do uprawiania określonego sportu, do udziału w zawodach; sprawować w dużej mierze obiektywną kontrolę nad edukacją (treningiem) uczniów i młodych sportowców; zidentyfikować zalety i wady stosowanych narzędzi, metody nauczania i formy organizacji zajęć; wreszcie uzasadnienie norm (wiek, osobnika) sprawności fizycznej dzieci i młodzieży.
20 slajdów
Opis slajdu:
Wraz z powyższymi zadaniami w praktyce różnych krajów zadania testowania sprowadzają się do następujących: nauczenie samych uczniów określania poziomu ich sprawności fizycznej i planowania niezbędnych kompleksów ćwiczeń fizycznych; stymulować uczniów do dalszej poprawy kondycji fizycznej (formy); znać nie tyle początkowy poziom rozwoju zdolności motorycznych, ile jego zmianę w określonym czasie; stymulować uczniów, którzy osiągnęli wysokie wyniki, ale nie tyle na wysoki poziom, ile na planowany wzrost wyników osobistych.
21 slajdów
Opis slajdu:
Test to pomiar lub test przeprowadzany w celu określenia zdolności lub stanu danej osoby.
22 slajd
Opis slajdu:
Tylko te testy (próbki), które spełniają specjalne wymagania, mogą być użyte jako testy: należy określić cel zastosowania dowolnego testu (lub testów); należy opracować znormalizowaną metodę pomiaru testowego i procedurę testową; konieczne jest określenie rzetelności i zawartości informacyjnej testów; wyniki testów można zgłaszać w odpowiednim systemie oceniania
23 slajd
Opis slajdu:
Test. Testowanie. Wynik testu System używania testów zgodnie z postawionym zadaniem, organizowania warunków, wykonywania testów przez podmioty, oceniania i analizowania wyników nazywamy testowaniem. Wynikiem badania (testu) jest wartość liczbowa uzyskana w trakcie pomiarów.
24 slajdy
Opis slajdu:
Testy stosowane w kulturze fizycznej opierają się na czynnościach ruchowych (ćwiczenia fizyczne, zadania ruchowe). Testy te nazywane są testami motorycznymi lub motorycznymi.
25 slajdów
Opis slajdu:
Znana jest klasyfikacja testów według ich struktury, a według ich dominujących wskazań rozróżnia się testy pojedyncze i złożone. Pojedynczy test służy do pomiaru i oceny jednego atrybutu (zdolność koordynacji lub kondycji).
26 slajdów
Opis slajdu:
27 slajdów
Opis slajdu:
Za pomocą złożonego testu ocenia się kilka cech lub elementów o różnych lub tych samych umiejętnościach. np. wyskok z miejsca (z machnięciem ramion, bez machania ramion, na daną wysokość).
28 slajdów
Opis slajdu:
29 slajdów
Opis slajdu:
TESTY mogą być testami kondycjonowania w celu oceny zdolności wytrzymałościowych do oceny wytrzymałości; ocenić zdolności szybkościowe; ocena gibkości, testy koordynacyjne w celu oceny zdolności koordynacyjnych związanych z wyodrębnionymi niezależnymi grupami czynności ruchowych, które mierzą specjalne zdolności koordynacyjne; ocena specyficznych zdolności koordynacyjnych – umiejętność równowagi, orientacji w przestrzeni, reakcji, różnicowania parametrów ruchu, rytmu, restrukturyzowania czynności ruchowych, koordynacji (komunikacji), stabilności przedsionkowej, dobrowolnego rozluźnienia mięśni).
30 slajdów
Opis slajdu:
Każda klasyfikacja jest rodzajem wytycznych dotyczących wyboru (lub tworzenia) rodzaju testów, które są bardziej odpowiednie do celów testowania.
31 slajdów
Opis slajdu:
TESTY SILNIKOWE KRYTERIA RODZAJU Pojęcie „testu motorycznego” spełnia swoje zadanie, gdy test spełnia odpowiednie kryteria podstawowe: rzetelność, stabilność, równoważność, obiektywność, zawartość informacji (ważność), a także kryteria dodatkowe: standaryzację, porównywalność i ekonomiczność. Testy spełniające wymagania rzetelności i zawartości informacyjnej nazywane są dobrymi lub autentycznymi (rzetelnymi).
32 slajdy
Opis slajdu:
Rzetelność testu rozumiana jest jako stopień dokładności, z jakim ocenia określoną zdolność motoryczną, niezależnie od wymagań oceniającego. Niezawodność przejawia się w stopniu zbieżności wyników podczas ponownego testowania tych samych osób w tych samych warunkach; jest to stabilność lub spójność wyników testu danej osoby, gdy ćwiczenie kontrolne jest powtarzane. Innymi słowy, dziecko w grupie badanych według wyników powtarzanych testów (np. wskaźniki skoków, czas biegu, zasięg rzutu) stale utrzymuje swoje miejsce w rankingu. Wiarygodność testu jest określana za pomocą analizy korelacji statystycznej poprzez obliczenie współczynnika wiarygodności. Jednocześnie stosuje się różne metody, na podstawie których ocenia się wiarygodność testu.
33 slajd
Opis slajdu:
Stabilność testu opiera się na relacji między pierwszą a drugą próbą, powtórzoną po pewnym czasie w tych samych warunkach przez tego samego eksperymentatora. Sposób ponownego testowania w celu określenia niezawodności nazywa się retestem. Stabilność testu zależy od rodzaju testu, wieku i płci badanych, odstępu czasu między testem a powtórnym testem. Na przykład wskaźniki testów warunkowania lub cech morfologicznych w krótkich odstępach czasu są bardziej stabilne niż wyniki testów koordynacyjnych; dla starszych dzieci wyniki są bardziej stabilne niż dla młodszych dzieci. Ponowny test jest zwykle przeprowadzany nie później niż tydzień później. W dłuższych odstępach czasu (np. po miesiącu) stabilność równych testów, takich jak bieganie na 1000 metrów czy skok w dal z miejsca, staje się zauważalnie niższa.
34 slajd
Opis slajdu:
Równoważność testu Równoważność testu to korelacja wyniku testu z wynikami innych testów tego samego typu. Na przykład, gdy trzeba wybrać, który test lepiej odzwierciedla zdolności szybkościowe: bieganie na 30, 50, 60 lub 100 m. Stosunek do testów równoważnych (jednorodnych) zależy od wielu powodów. Jeśli konieczne jest zwiększenie wiarygodności szacunków lub wniosków z badania, zaleca się zastosowanie dwóch lub więcej równoważnych testów. A jeśli celem jest stworzenie baterii zawierającej minimum testów, należy użyć tylko jednego z równoważnych testów. Taka bateria, jak zauważono, jest niejednorodna, ponieważ zawarte w niej testy mierzą różne zdolności motoryczne. Przykładami niejednorodnej baterii testów są 30m biegu, podciąganie drążkiem, skłon do przodu, 1000m biegu.
35 slajdów
Opis slajdu:
Rzetelność testów określa się również poprzez porównanie średnich wyników parzystych i nieparzystych prób zawartych w teście. Na przykład średnie rzuty na cel z 1, 3, 5, 7 i 9 prób są porównywane ze średnimi rzutami na cel z 2, 4, 6, 8 i 10 prób. Ta metoda oceny niezawodności nazywana jest metodą podwajania lub dzielenia. Stosowany jest głównie przy ocenie zdolności koordynacyjnych oraz w przypadku, gdy liczba prób składających się na wynik testu jest nie mniejsza niż sześć.
36 slajdów
Opis slajdu:
Obiektywność (spójność) testu Obiektywizm (spójność) testu rozumiana jest jako stopień zgodności wyników uzyskanych na tych samych tematach przez różnych eksperymentatorów (nauczycieli, sędziów, ekspertów). Aby zwiększyć obiektywność badań, konieczne jest przestrzeganie standardowych warunków badania: czas badania, miejsce, warunki pogodowe; ujednolicone wsparcie materiałowe i sprzętowe; czynniki psychofizjologiczne (objętość i intensywność obciążenia, motywacja); prezentacja informacji (precyzyjne sformułowanie słowne problemu testowego, wyjaśnienie i demonstracja). To jest tak zwana obiektywność testu. Mówi się również o obiektywności interpretacyjnej, odnoszącej się do stopnia niezależności interpretacji wyników badań przez różnych eksperymentatorów.
37 slajdów
Opis slajdu:
Ogólnie rzecz biorąc, jak zauważają eksperci, wiarygodność testów można poprawić na różne sposoby: przez ściślejszą standaryzację testów, wzrost liczby prób, lepszą motywację badanych, wzrost liczby oceniających (sędziów, ekspertów), wzrost spójności ich opinii, wzrost liczby równoważnych testów. Nie ma stałych wartości dla wskaźników wiarygodności testu. W większości przypadków stosują następujące zalecenia: 0,95 - 0,99 - doskonała niezawodność; 0,90 - 0,94 - dobry; 0,80 - 0,89 - dopuszczalne; 0,70 - 0,79 - zły; 0,60 - 0,69 - wątpliwe dla ocen indywidualnych, test nadaje się tylko do scharakteryzowania grupy badanych.
38 slajdów
Opis slajdu:
Informacyjność testu to stopień dokładności, z jakim mierzy on ocenianą zdolność lub umiejętność motoryczną. W literaturze zagranicznej (i krajowej) zamiast słowa „informacyjność” używa się terminu „ważność” (z angielskiego. Ważność-ważność, ważność, legalność). W istocie mówiąc o zawartości informacji, badacz odpowiada na dwa pytania: co mierzy ten konkretny test (bateria testów) i jaki jest stopień dokładności pomiaru. Istnieje kilka typów trafności: logiczna (istotna), empiryczna (oparta na danych eksperymentalnych) i predykcyjna.
39 slajdów
Opis slajdu:
Jak już wspomniano, ważnymi dodatkowymi kryteriami testów są standaryzacja, porównywalność i efektywność kosztowa. Istotą normalizacji jest to, że na podstawie wyników badań możliwe jest tworzenie norm o szczególnym znaczeniu dla praktyki. Porównywalność testów to zdolność do porównywania wyników uzyskanych z jednej lub więcej form równoległych (jednorodnych) testów. W praktyce zastosowanie porównywalnych testów motorycznych zmniejsza prawdopodobieństwo, że w wyniku regularnego stosowania tego samego testu oceniany jest nie tylko poziom umiejętności, ale stopień umiejętności. Równocześnie porównywane wyniki badań zwiększają wiarygodność wniosków. Istotą ekonomii jako kryterium słuszności testu jest to, że test nie wymaga długiego czasu, dużych kosztów materiałowych i udziału wielu asystentów.
40 slajdów
Opis slajdu:
ORGANIZACJA BADANIA PRZYGOTOWANIA DZIECI W WIEKU SZKOLNYM Drugim ważnym problemem badania zdolności motorycznych (przypomnijmy, że pierwszym jest dobór testów informacyjnych, to organizacja ich stosowania. do obowiązkowego dwukrotnego sprawdzania sprawności fizycznej uczniów.
41 slajdów
Opis slajdu:
Znajomość rocznych zmian w rozwoju zdolności motorycznych dzieci pozwala nauczycielowi na odpowiednie dostosowanie procesu kultury fizycznej na kolejny rok akademicki. Jednak nauczyciel musi i może przeprowadzać częstsze sprawdziany, przeprowadzać tzw. kontrolę operacyjną. Jest to przydatne do określenia, na przykład, zmian w szybkości, sile i wytrzymałości, na które wpływ miały lekcje lekkoatletyki podczas pierwszej kwarty. W tym celu nauczyciel może wykorzystać testy do oceny zdolności koordynacyjnych dzieci na początku i na końcu opanowania materiału programu, na przykład w grach sportowych, w celu zidentyfikowania zmian we wskaźnikach rozwoju tych umiejętności .
42 slajd
Opis slajdu:
Należy pamiętać, że różnorodność problemów pedagogicznych do rozwiązania nie pozwala na zapewnienie nauczycielowi jednolitej metodyki sprawdzianów, jednakowych zasad przeprowadzania sprawdzianów i oceny wyników sprawdzianów. Wymaga to od eksperymentatorów (nauczycieli) samodzielności w rozwiązywaniu teoretycznych, metodologicznych i organizacyjnych problemów testowania. Testowanie w lekcji musi być powiązane z jej treścią. Innymi słowy, zastosowany test lub testy, z zastrzeżeniem odpowiednich wymagań (co do metody badawczej), powinny być organicznie włączone do planowanego wysiłku fizycznego. Jeśli na przykład u dzieci wymagane jest określenie poziomu rozwoju zdolności szybkościowych lub wytrzymałości, niezbędne testy należy zaplanować w tej części lekcji, w której zostaną rozwiązane zadania rozwoju odpowiednich zdolności fizycznych.
43 slajd
Opis slajdu:
Częstotliwość testów w dużej mierze zależy od tempa rozwoju określonych zdolności fizycznych, wieku i płci oraz indywidualnych cech ich rozwoju. Na przykład, aby osiągnąć znaczny wzrost szybkości, wytrzymałości czy siły, potrzeba kilku miesięcy regularnych ćwiczeń (treningów). Jednocześnie, aby uzyskać pewny wzrost gibkości czy indywidualnych zdolności koordynacyjnych, wystarczy 4-12 treningów. Możliwe jest osiągnięcie poprawy jakości fizycznej, jeśli zaczniesz od zera w krótszym czasie. Aby poprawić tę samą jakość, gdy jest to dziecko na wysokim poziomie, zajmuje to więcej czasu. W związku z tym nauczyciel powinien głębiej przestudiować cechy rozwoju i poprawy różnych zdolności motorycznych u dzieci w różnym wieku i okresie płci.
44 slajd
Opis slajdu:
Oceniając ogólną sprawność fizyczną dzieci, można użyć szerokiej gamy baterii testowych, których wybór zależy od konkretnych zadań testowych i dostępności niezbędnych warunków. Jednak z uwagi na fakt, że uzyskane wyniki testów można oceniać jedynie przez porównanie, warto wybrać testy, które są szeroko reprezentowane w teorii i praktyce wychowania fizycznego dzieci. Na przykład polegaj na tych zalecanych w programie FC. Aby porównać ogólny poziom sprawności fizycznej ucznia lub grupy uczniów za pomocą zestawu testów, uciekają się do przełożenia wyników testu na punkty lub punkty. Zmiana sumy punktów podczas powtarzanych testów pozwala ocenić postępy zarówno pojedynczego dziecka, jak i grupy dzieci.
49 slajdów
Opis slajdu:
Ważnym aspektem testowania jest problem wyboru testu do oceny określonej sprawności fizycznej i ogólnej sprawności fizycznej.
50 slajdów
Opis slajdu:
Praktyczne porady i porady. WAŻNE: Określ (wybierz) baterię (lub zestaw) niezbędnych testów ze szczegółowym opisem wszystkich szczegółów ich przeprowadzenia; Ustaw czas testowania (lepiej - 2-3 tygodnie września - pierwsze testowanie, 2-3 tygodnie maja - drugie testowanie); Zgodnie z zaleceniem dokładnie określ wiek dzieci w dniu badania oraz ich płeć; Opracowanie jednolitych protokołów rejestracji danych (ewentualnie opartych na wykorzystaniu ICT); Określ krąg asystentów i przeprowadź samą procedurę testowania; Natychmiast przeprowadzić matematyczną obróbkę danych testowych - obliczenie głównych parametrów statystycznych (średnia arytmetyczna, błąd średniej arytmetycznej, odchylenie standardowe, współczynnik zmienności i ocena wiarygodności różnic między wskaźnikami średniej arytmetycznej, na przykład równoległymi klasami takich samych i różnych szkoły dla dzieci w tym samym wieku i tej samej płci ); Jednym z istotnych etapów pracy może być przełożenie wyników testu na punkty lub punkty. Dzięki regularnym testom (2 razy w roku, przez kilka lat), pozwoli to nauczycielowi mieć wyobrażenie o postępach w wynikach.
51 slajdów
Opis slajdu:
Moskwa „Oświecenie” 2007 Książka zawiera najpopularniejsze testy motoryczne do oceny zdolności kondycyjnych i koordynacyjnych uczniów. Podręcznik przewiduje indywidualne podejście nauczyciela wychowania fizycznego do każdego konkretnego ucznia, biorąc pod uwagę jego wiek i budowę ciała.
Podstawowe pojęcia teorii testów.
Pomiar lub test przeprowadzany w celu określenia stanu lub zdolności sportowca nazywa się testem. Każdy test obejmuje pomiar. Ale nie każda zmiana jest testem. Procedura pomiarowa lub testowa nazywana jest testowaniem.
Test oparty na zadaniach motorycznych nazywa się testem motorycznym. Istnieją trzy grupy testów ruchowych:
- 1. Ćwiczenia kontrolne, których wykonanie zawodnik otrzymuje zadanie pokazania maksymalnego wyniku.
- 2. Standardowe testy funkcjonalne, podczas których zadanie, które jest jednakowe dla wszystkich, jest dawkowane albo ilością wykonanej pracy, albo ilością przesunięć fizjologicznych.
- 3. Maksymalne testy funkcjonalne, podczas których zawodnik musi pokazać maksymalny wynik.
Testowanie wysokiej jakości wymaga znajomości teorii pomiarów.
Podstawowe pojęcia teorii pomiaru.
Pomiar to identyfikacja związku między badanym zjawiskiem z jednej strony a liczbami z drugiej.
Podstawą teorii pomiaru są trzy pojęcia: skale pomiarowe, jednostki miary i dokładność pomiaru.
Wagi pomiarowe.
Skala pomiaru to prawo, zgodnie z którym wartość liczbowa jest przypisywana do mierzonego wyniku w miarę jego wzrostu lub spadku. Rozważmy niektóre skale używane w sporcie.
Skala nazw (skala nominalna).
To najprostsza ze wszystkich skal. W nim liczby działają jak etykiety i służą do wykrywania i rozróżniania badanych obiektów (na przykład numeracja graczy w drużynie piłkarskiej). Liczby tworzące skalę nazewnictwa można zmieniać za pomocą metas. Na tej skali nie ma relacji więcej-mniej, więc niektórzy uważają, że skala nazewnictwa nie powinna być traktowana jako miara. Korzystając ze skali nazewnictwa, można wykonać tylko niektóre operacje matematyczne. Na przykład jego liczb nie można dodawać ani odejmować, ale można policzyć, ile razy (jak często) występuje dana liczba.
Skala zamówień.
Są sporty, w których wynik sportowca zależy tylko od miejsca zajmowanego w zawodach (na przykład sztuki walki). Po takich zawodach widać, który z zawodników jest silniejszy, a który słabszy. Ale o ile silniejszy lub słabszy, nie można powiedzieć. Jeśli trzej zawodnicy zajęli odpowiednio pierwsze, drugie i trzecie miejsce, to jakie są różnice w ich sportowej rywalizacji, pozostaje niejasne: drugi zawodnik może być prawie równy pierwszemu lub może być słabszy od niego i być prawie taki sam z trzecim. Miejsca zajmowane w skali porządku nazywane są rangami, a sama skala to rangą lub niemetryczną. W takiej skali jej liczby składowe są uporządkowane według rang (tj. zajmowanych miejsc), ale odstępy między nimi nie mogą być dokładnie zmierzone. W przeciwieństwie do skali nazw, skala porządku pozwala nie tylko na ustalenie faktu równości lub nierówności mierzonych obiektów, ale także na określenie charakteru nierówności w postaci sądów: „więcej – mniej”, „lepiej”. - gorzej” itp.
Za pomocą skal zamówień możesz mierzyć wskaźniki jakościowe, które nie mają ścisłej miary ilościowej. Skale te są szczególnie szeroko stosowane w naukach humanistycznych: pedagogice, psychologii, socjologii.
Na szeregach skali porządkowej można zastosować więcej operacji matematycznych niż na liczbach na skali nominałów.
Skala interwałowa.
Jest to skala, w której liczby są nie tylko uporządkowane według rangi, ale także oddzielone określonymi przedziałami. Cechą odróżniającą go od opisanej poniżej skali relacji jest arbitralny wybór punktu zerowego. Przykładami są czas kalendarzowy (początek chronologii w różnych kalendarzach został ustalony z przyczyn losowych), kąt stawowy (kąt w stawie łokciowym przy pełnym wyprostowaniu przedramienia można przyjąć równy zero lub 180 °), temperaturę, energię potencjalną podnoszonego ładunku, potencjału pola elektrycznego itp. dr.
Wyniki pomiarów na skali przedziałów mogą być przetwarzane wszystkimi metodami matematycznymi, z wyjątkiem obliczeń ilorazowych. Te skale interwałowe dają odpowiedź na pytanie: „o ile więcej”, ale nie pozwalają na stwierdzenie, że jedna wartość mierzonej wartości jest tyle razy większa lub mniejsza od innej. Na przykład, jeśli temperatura wzrosła z 10 do 20 C, to nie można powiedzieć, że zrobiło się dwa razy cieplej.
Skala relacji.
Skala ta różni się od skali interwałowej tylko tym, że ściśle określa położenie punktu zerowego. Dzięki temu skala wskaźników nie nakłada żadnych ograniczeń na aparat matematyczny wykorzystywany do przetwarzania wyników obserwacji.
W sporcie skala relacji mierzy dystans, siłę, prędkość i dziesiątki innych zmiennych. Skala relacji mierzy również te wartości, które powstają jako różnica między liczbami liczonymi na skali interwałów. Tak więc czas kalendarzowy jest liczony w skali interwałów, a interwały czasowe - w skali relacji. Korzystając ze skali stosunków (i tylko w tym przypadku!) Pomiar dowolnej wielkości sprowadza się do eksperymentalnego określenia stosunku tej wielkości do innej podobnej wielkości, przyjmowanej jako jednostka. Mierząc długość skoku, dowiadujemy się, ile razy ta długość jest większa niż długość innego ciała, przyjmowana jako jednostka długości (w konkretnym przypadku linijka metryczna); ważąc sztangę ustalamy stosunek jej masy do masy innego ciała – jednostkowa masa „kilogram” itp. Jeśli ograniczymy się tylko do używania skal relacji, możemy podać inną (węższą, konkretną) definicję miary: zmierzyć jakąkolwiek wielkość oznacza empirycznie znaleźć jej związek z odpowiednią jednostką miary.
Jednostki miary.
Aby wyniki różnych pomiarów były ze sobą porównywane, muszą być wyrażone w tych samych jednostkach. W 1960 r. na Międzynarodowej Konferencji Generalnej Miar i Wag przyjęto Międzynarodowy Układ Jednostek Miar, który otrzymał skróconą nazwę SI (od pierwszych liter słowa System International). Obecnie preferowane zastosowanie tego systemu zostało ustalone we wszystkich dziedzinach nauki i techniki, w gospodarce narodowej, a także w nauczaniu.
SI obejmuje obecnie siedem niezależnych jednostek podstawowych (patrz tabela 2.1.)
Tabela 1.1.
Jednostki innych wielkości fizycznych są wyprowadzane z tych jednostek podstawowych jako pochodne. Jednostki pochodne określane są na podstawie wzorów łączących wielkości fizyczne. Na przykład jednostka długości (metr) i jednostka czasu (sekunda) są jednostkami podstawowymi, a jednostka prędkości (metr na sekundę) jest pochodną.
Oprócz głównych w SI wyróżnione są dwie dodatkowe jednostki: radian - jednostka kąta płaskiego i steradian - jednostka kąta bryłowego (kąt w przestrzeni).
Dokładność pomiarów.
Żaden pomiar nie może być wykonany z absolutną precyzją. Wynik pomiaru nieuchronnie zawiera błąd, którego wielkość jest mniejsza, im dokładniejsza jest metoda pomiaru i urządzenie pomiarowe. Na przykład, używając zwykłej linijki z podziałką milimetrową, nie można mierzyć długości z dokładnością do 0,01 mm.
Błąd podstawowy i dodatkowy.
Błąd podstawowy to błąd metody pomiarowej lub przyrządu pomiarowego, który występuje w normalnych warunkach użytkowania.
Błąd dodatkowy to błąd urządzenia pomiarowego spowodowany odchyleniem jego warunków pracy od normalnych. Oczywiste jest, że urządzenia zaprojektowane do pracy w temperaturze pokojowej podadzą niedokładne odczyty, jeśli będą używane latem na stadionie w palącym słońcu lub zimą na mrozie. Błędy pomiaru mogą wystąpić, gdy napięcie sieci lub zasilania bateryjnego jest poniżej normy lub nie ma stałej wartości.
Błędy bezwzględne i względne.
Wartość E = A - Ao, równa różnicy między odczytem urządzenia pomiarowego (A) a rzeczywistą wartością mierzonej wielkości (Ao), nazywana jest bezwzględnym błędem pomiaru. Jest mierzona w tych samych jednostkach, co sama zmierzona wartość.
W praktyce często wygodnie jest użyć błędu nie bezwzględnego, ale względnego. Względny błąd pomiaru jest dwojakiego rodzaju - rzeczywisty i zredukowany. Rzeczywisty błąd względny to stosunek błędu bezwzględnego do rzeczywistej wartości mierzonej wielkości:
A D = --------- * 100%
Zmniejszony błąd względny to stosunek błędu bezwzględnego do maksymalnej możliwej wartości mierzonej wielkości:
Ap = ---------- * 100%
Błędy systematyczne i losowe.
Systematyczny jest błędem, którego wartość nie zmienia się od pomiaru do pomiaru. Ze względu na tę specyfikę błąd systematyczny można często przewidzieć z wyprzedzeniem lub, w skrajnych przypadkach, wykryć i wyeliminować na końcu procesu pomiarowego.
Sposób wyeliminowania błędu systematycznego zależy przede wszystkim od jego charakteru. Błędy systematyczne pomiaru można podzielić na trzy grupy:
błędy o znanym pochodzeniu i znanej wartości;
błędy o znanym pochodzeniu, ale o nieznanej wielkości;
błędy niewiadomego pochodzenia i nieznanej wartości. Najbardziej nieszkodliwe są błędy pierwszej grupy. Są łatwo eliminowane
wprowadzając odpowiednie poprawki do wyniku pomiaru.
Druga grupa to przede wszystkim błędy związane z niedoskonałością metody pomiarowej i aparatury pomiarowej. Na przykład błąd pomiaru sprawności fizycznej za pomocą maski do wdychania wydychanego powietrza: maska utrudnia oddychanie, a sportowiec w naturalny sposób wykazuje wydolność fizyczną, która jest niedoszacowana w porównaniu z prawdziwą mierzoną bez maski. Wielkości tego błędu nie można z góry przewidzieć: zależy to od indywidualnych zdolności sportowca i jego stanu zdrowia w czasie badania.
Innym przykładem błędu systematycznego tej grupy jest błąd związany z niedoskonałością sprzętu, gdy urządzenie pomiarowe celowo zawyża lub zaniża prawdziwą wartość wartości mierzonej, ale wielkość błędu jest nieznana.
Najgroźniejsze są błędy z trzeciej grupy, ich pojawienie się wiąże się zarówno z niedoskonałością metody pomiaru, jak iz charakterystyką przedmiotu pomiaru - sportowca.
Błędy losowe powstają pod wpływem różnych czynników, których nie można z góry przewidzieć lub dokładnie uwzględnić. Przypadkowych błędów zasadniczo nie da się wyeliminować. Jednak stosując metody statystyki matematycznej można oszacować wielkość błędu losowego i uwzględnić go przy interpretacji wyników pomiarów. Wyniki pomiarów nie mogą być uważane za wiarygodne bez przetwarzania statystycznego.
Co to jest testowanie
Zgodnie z normą IEEE 829-1983 Testowanie to proces analizy oprogramowania, którego celem jest zidentyfikowanie różnic między jego faktycznie istniejącymi a wymaganymi właściwościami (wada) oraz ocena właściwości oprogramowania.
Zgodnie z GOST R ISO IEC 12207-99 w cyklu życia oprogramowania identyfikowane są m.in. pomocnicze procesy weryfikacji, certyfikacji, wspólnej analizy i audytu. Proces weryfikacji to proces ustalania, czy oprogramowanie działa w pełnej zgodności z wymaganiami lub warunkami zaimplementowanymi we wcześniejszej pracy. Proces ten może obejmować analizę, weryfikację i testowanie (testowanie). Proces atestacji to proces określania kompletności zgodności założonych wymagań, tworzonego systemu lub oprogramowania z ich przeznaczeniem funkcjonalnym. Proces wspólnego przeglądu to proces oceny stanów i, jeśli to konieczne, wyników pracy (produktów) nad projektem. Proces audytu to proces ustalania zgodności z wymaganiami, planami i warunkami umowy. Te procesy składają się na to, co powszechnie nazywa się testowaniem.
Testowanie opiera się na procedurach testowych z określonymi danymi wejściowymi, warunkami początkowymi i oczekiwanymi wynikami zaprojektowanymi w określonym celu, takim jak testowanie pojedynczego programu lub weryfikacja zgodności z określonym wymaganiem. Procedury testowe mogą testować różne aspekty działania programu, od prawidłowego działania pojedynczej funkcji po odpowiednie spełnienie wymagań biznesowych.
Realizując projekt należy wziąć pod uwagę, według jakich norm i wymagań produkt będzie testowany. Jakie narzędzia (jeśli w ogóle) zostaną użyte do znalezienia i udokumentowania wykrytych wad. Jeśli pamiętasz o testowaniu od samego początku projektu, testowanie tworzonego produktu nie przyniesie żadnych przykrych niespodzianek. Oznacza to, że jakość produktu będzie prawdopodobnie dość wysoka.
Cykl życia produktu i testowanie
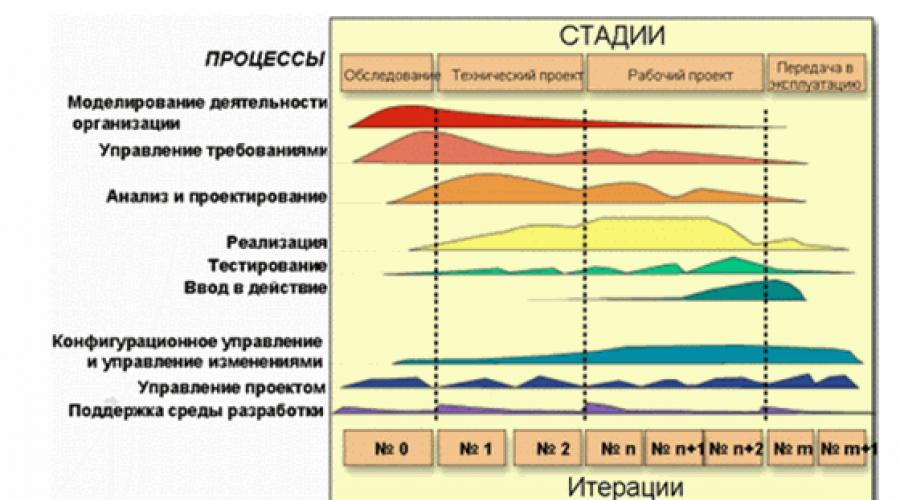
Coraz częściej w naszych czasach stosuje się iteracyjne procesy wytwarzania oprogramowania, w szczególności technologii RUP - racjonalny ujednolicony proces(rys. 1). Przy takim podejściu testowanie przestaje być procesem out-of-the-box, który rozpoczyna się po napisaniu przez programistów całego niezbędnego kodu. Praca nad testami rozpoczyna się już na początkowym etapie identyfikacji wymagań dla przyszłego produktu i jest ściśle zintegrowana z bieżącymi zadaniami. A to stawia przed testerami nowe wymagania. Ich rola nie ogranicza się tylko do jak najpełniejszego i jak najwcześniejszego identyfikowania błędów. Powinni uczestniczyć w całościowym procesie identyfikacji i eliminacji najistotniejszych ryzyk projektowych. Aby to zrobić, dla każdej iteracji określany jest cel testu i metody jego osiągnięcia. A na końcu każdej iteracji ustala się, w jakim stopniu ten cel został osiągnięty, czy potrzebne są dodatkowe testy, czy należy zmienić zasady i narzędzia do przeprowadzania testów. Z kolei każda wykryta defekt musi przejść przez swój własny cykl życia.
Ryż. 1. Cykl życia produktu zgodnie z RUP
Testowanie odbywa się zwykle w cyklach, z których każdy ma określoną listę zadań i celów. Cykl testowy może pokrywać się z iteracją lub odpowiadać określonej jego części. Zazwyczaj cykl testowania jest przeprowadzany dla konkretnej kompilacji systemu.
Cykl życia oprogramowania składa się z serii stosunkowo krótkich iteracji (rys. 2). Iteracja to pełny cykl rozwojowy prowadzący do wydania produktu końcowego lub jego zredukowanej wersji, która rozwija się od iteracji do iteracji, aby ostatecznie stać się kompletnym systemem.
Każda iteracja obejmuje co do zasady zadania planowania pracy, analizy, projektowania, wdrażania, testowania i oceny uzyskanych wyników. Jednak relacje między tymi zadaniami mogą się znacznie różnić. Zgodnie ze stosunkiem różnych zadań w iteracji są one pogrupowane w fazy. Pierwsza faza – Incepcja – skupia się na zadaniach analitycznych. Iteracje drugiej fazy - Development - skupiają się na projektowaniu i testowaniu kluczowych rozwiązań projektowych. Trzecia faza - Build - ma największy udział w zadaniach programistycznych i testowych. A w ostatniej fazie - Transfer - zadania testowania i przekazania systemu Klientowi są rozwiązywane w największym stopniu.

Ryż. 2. Iteracje cyklu życia oprogramowania
Każda faza ma swoje własne cele w cyklu życia produktu i jest uważana za zakończoną, gdy cele te zostaną osiągnięte. Wszystkie iteracje, z wyjątkiem, być może, iteracji fazy Incepcji, kończą się stworzeniem działającej wersji opracowywanego systemu.
Testowanie kategorii
Testy znacznie różnią się zadaniami rozwiązywanymi za ich pomocą oraz stosowaną techniką.
| Testowanie kategorii | Opis kategorii | Rodzaje testów |
|---|---|---|
| Bieżące testy | Zestaw testów, które są wykonywane w celu określenia kondycji dodanych nowych funkcji systemu. |
|
| Testy regresji | Celem testów regresji jest sprawdzenie, czy dodatki do systemu nie zmniejszyły jego możliwości, tj. testowanie odbywa się zgodnie z wymaganiami, które zostały już spełnione przed dodaniem nowych funkcji. |
|
Testowanie podkategorii
| Testowanie podkategorii | Opis rodzaju badania | Testowanie podtypów |
|---|---|---|
| Test naprężeń | Służy do testowania wszystkich funkcji aplikacji bez wyjątku. W tym przypadku kolejność funkcji testowania nie ma znaczenia. |
|
| Testowanie cyklu biznesowego | Służy do testowania funkcji aplikacji w kolejności ich wywoływania przez użytkownika. Na przykład imitacja wszystkich działań księgowego przez 1 kwartał. |
|
| Test naprężeń |
Używany do testowania Wydajność aplikacji. Celem tego testu jest określenie ram dla stabilnego działania aplikacji. Podczas tego testu wywoływane są wszystkie dostępne funkcje. |
|
Rodzaje testów
Testów jednostkowych (testy jednostkowe) - ten typ polega na testowaniu poszczególnych modułów aplikacji. Aby uzyskać maksymalny wynik, testowanie odbywa się jednocześnie z rozwojem modułów.
Testy funkcjonalności - Celem tego testowania jest upewnienie się, że element testu działa prawidłowo. Sprawdzana jest poprawność nawigacji po obiekcie, wprowadzanie, przetwarzanie i wyprowadzanie danych.
Testowanie baz danych - sprawdzanie działania bazy danych podczas normalnej pracy aplikacji, w momentach przeciążenia oraz w trybie wielu użytkowników.
Testów jednostkowych
W przypadku programowania obiektowego zwykłą organizacją testów jednostkowych jest testowanie metod każdej klasy, następnie klasy każdego pakietu i tak dalej. Stopniowo przechodzimy do testowania całego projektu, a poprzednie testy to testy regresji.
Dokumentacja wyjściowa tych testów obejmuje procedury testowe, dane wejściowe, kod wykonujący test oraz dane wyjściowe. Poniżej znajduje się widok dokumentacji wyjściowej.
Testy funkcjonalności
Testowanie funkcjonalne obiektu testowego jest planowane i przeprowadzane w oparciu o wymagania testowe określone na etapie definiowania wymagań. Wymaganiami są reguły biznesowe, diagramy przypadków użycia, funkcje biznesowe oraz, jeśli są dostępne, diagramy aktywności. Celem testów funkcjonalnych jest sprawdzenie, czy opracowane komponenty graficzne spełniają określone wymagania.
Ten rodzaj testowania nie może być w pełni zautomatyzowany. W związku z tym dzieli się na:
- Testowanie automatyczne (do wykorzystania w przypadku, gdy dane wyjściowe mogą być zweryfikowane).
Cel: testowanie wprowadzania, przetwarzania i wyprowadzania danych;
- Testowanie ręczne (w innych przypadkach).
Cel: Testowana jest poprawność spełnienia wymagań użytkownika.
Konieczne jest wykonanie (odtworzenie) każdego z przypadków użycia, używając zarówno wartości prawidłowych, jak i celowo błędnych, aby potwierdzić prawidłowe działanie, zgodnie z następującymi kryteriami:
- produkt odpowiednio reaguje na wszystkie dane wejściowe (oczekiwane wyniki są wyświetlane w odpowiedzi na poprawnie wprowadzone dane);
- produkt odpowiednio reaguje na błędnie wprowadzone dane (pojawiają się odpowiednie komunikaty o błędach).
Testowanie baz danych
Celem tego testu jest upewnienie się, że metody dostępu do bazy danych są niezawodne, poprawnie wykonywane, bez naruszania integralności danych.
Należy konsekwentnie używać jak największej liczby wywołań bazy danych. Stosowane jest podejście, w którym test jest skomponowany w taki sposób, aby „obciążyć” bazę sekwencją zarówno wartości prawidłowych, jak i celowo błędnych. Określana jest reakcja bazy danych na wprowadzanie danych oraz szacowane są przedziały czasowe ich przetwarzania.
Pomiar lub test przeprowadzany w celu określenia stanu lub zdolności sportowca nazywa się ciasto... Nie wszystkie pomiary mogą być wykorzystane jako testy, a jedynie te, które spełniają specjalne wymagania: standard, dostępność systemu ocen, wiarygodność, zawartość informacji, obiektywność. Testy spełniające wymagania rzetelności, zawartości informacji i obiektywności nazywane są solidny.
Proces testowania nazywa się testowanie, a uzyskane w wyniku pomiaru wartości liczbowe to wynik testu.
Testy oparte na zadaniach ruchowych nazywają się silnik lub silnik... Wyróżnia się trzy grupy testów motorycznych w zależności od zadania, przed którym stoi badany.
Odmiany testów motorycznych
|
Nazwa testu |
Przypisanie do sportowca |
Wynik testu | |
|
Ćwiczenie kontrolne |
Osiągnięcia motoryczne |
Biegnij 1500m, czas biegu |
|
|
Funkcjonalne testy standardowe |
Jednakowe dla wszystkich, dozowane: 1) według ilości wykonanej pracy; 2) o wielkość przesunięć fizjologicznych |
Wskaźniki fizjologiczne lub biochemiczne przy standardowej pracy Wskaźniki motoryczne przy standardowej wielkości przesunięć fizjologicznych |
Rejestrowanie tętna przy pracy standardowej 1000 kgm/min Prędkość biegu z tętnem 160 uderzeń/min |
|
Maksymalne testy funkcjonalne |
Pokaż maksymalny wynik |
Parametry fizjologiczne lub biochemiczne |
Określenie maksymalnego długu tlenowego lub maksymalnego zużycia tlenu |
Czasami nie jeden, ale kilka testów jest używanych w jednym ostatecznym celu. Ta grupa testów nazywa się bateria testów.
Wiadomo, że nawet przy najbardziej rygorystycznej standaryzacji i precyzyjnym sprzęcie wyniki testów zawsze nieco się różnią. Dlatego jednym z ważnych warunków wyboru dobrych testów jest ich wiarygodność.
Wiarygodność testu to stopień zbieżności wyników, gdy te same osoby są ponownie testowane w tych samych warunkach. Istnieją cztery główne powody zmienności wyników badań w obrębie poszczególnych osób lub grup:
zmiany stanu badanych (zmęczenie, zmiana motywacji itp.); niekontrolowane zmiany warunków zewnętrznych i wyposażenia;
zmiana stanu osoby przeprowadzającej lub oceniającej badanie (dobre samopoczucie, zmiana eksperymentatora itp.);
niedoskonałość testu (np. celowo niedoskonałe i niewiarygodne testy – rzuty wolne do kosza przed pierwszym chybieniem itp.).
Kryterium wiarygodności testu może być: współczynnik niezawodności, obliczany jako stosunek prawdziwej wariancji do wariancji zarejestrowanej w eksperymencie: r = prawda s 2 / zarejestrowana s 2, gdzie przez wartość prawdziwą rozumie się wariancję uzyskaną przy nieskończonej liczbie obserwacji w tych samych warunkach; zarejestrowana wariancja pochodzi z badań eksperymentalnych. Innymi słowy, współczynnik rzetelności jest po prostu ułamkiem prawdziwej zmienności w zmienności zarejestrowanej w doświadczeniu.
Oprócz tego współczynnika używają również wskaźnik niezawodności, który jest uważany za teoretyczny współczynnik korelacji lub związek między zarejestrowanymi a rzeczywistymi wartościami tego samego testu. Metoda ta jest najczęściej stosowana jako kryterium oceny jakości (wiarygodności) testu.
Jedną z cech wiarygodności testu jest jego równorzędność, który odzwierciedla stopień zbieżności wyników testów o tej samej jakości (na przykład fizycznych) w różnych testach. Stosunek do badania równoważności zależy od konkretnego zadania. Z jednej strony, jeśli dwa lub więcej testów jest równoważnych, ich połączone zastosowanie zwiększa wiarygodność szacunków; z drugiej strony wydaje się możliwe zastosowanie tylko jednego równoważnego testu, co uprości testowanie.
Jeśli wszystkie testy w dowolnej baterii testowej są wysoce równoważne, nazywa się je jednorodny(na przykład, aby ocenić jakość skoków, należy założyć, że skok w dal, w górę, potrójne skoki będą jednorodne). Wręcz przeciwnie, jeśli w kompleksie nie ma równoważnych testów (na przykład do oceny ogólnej sprawności fizycznej), to wszystkie testy w nim zawarte mierzą różne właściwości, tj. zasadniczo kompleks jest heterogeniczny.
Wiarygodność testów można w pewnym stopniu poprawić poprzez:
bardziej rygorystyczna standaryzacja badań;
zwiększenie liczby prób;
zwiększenie liczby ewaluatorów i zwiększenie spójności ich opinii;
zwiększenie liczby testów równoważnych;
lepsza motywacja badanych.
Obiektywność testu istnieje szczególny przypadek niezawodności, tj. niezależność wyników testu od osoby przeprowadzającej test.
Informatywność testu Jest to stopień dokładności, z jakim mierzy właściwość (jakość sportowca), do której jest używany. W różnych przypadkach te same testy mogą mieć różną zawartość informacyjną. Kwestia informacyjności testu dzieli się na dwa szczegółowe pytania:
Co zmienia ten test? Jak dokładnie to mierzy?
Na przykład, czy można ocenić sprawność biegaczy długodystansowych za pomocą takiego wskaźnika, jak IPC, a jeśli tak, to z jaką dokładnością? Czy ten test można wykorzystać w procesie monitorowania?
Jeśli test służy do określenia stanu sportowca w czasie badania, to mówią o diagnostyczny informacyjność testu. Jeśli na podstawie wyników badań chcą wyciągnąć wnioski na temat możliwej przyszłej wydajności sportowca, mówią o proroczy informacyjność. Test może być diagnostycznie informacyjny, ale nie prognostyczny i na odwrót.
Stopień zawartości informacji można scharakteryzować ilościowo – na podstawie danych eksperymentalnych (tzw empiryczny informacyjność) i jakościowo - na podstawie miarodajnej analizy sytuacji ( logiczny informacyjność). Chociaż w pracy praktycznej analiza logiczna lub sensowna powinna zawsze poprzedzać analizę matematyczną. Wskaźnikiem informacyjności testu jest współczynnik korelacji obliczony dla zależności kryterium od wyniku w teście i odwrotnie (wskaźnik jest traktowany jako kryterium, oczywiście odzwierciedla właściwość, która będzie mierzona za pomocą test).
W przypadku niewystarczającej zawartości informacji w jakimkolwiek teście, uciekają się do korzystania z baterii testów. Jednak ta ostatnia, nawet przy wysokich odrębnych kryteriach zawartości informacji (sądząc po współczynnikach korelacji), nie pozwala na uzyskanie jednej liczby. Tutaj na ratunek może przyjść bardziej złożona metoda statystyki matematycznej - Analiza czynników. Co pozwala określić, ile i które testy współpracują ze sobą w danym czynniku i jaki jest stopień ich wkładu w każdy czynnik. A potem już łatwo jest wybrać testy (lub ich kombinacje), które najdokładniej oceniają poszczególne czynniki.
|
1 Co nazywa się testem? | |
|
2 Co to jest testowanie? |
Ocena ilościowa jakości lub stanu sportowca Pomiar lub badanie w celu określenia stanu lub stanu sportowca Proces badania, który określa jakość lub stan sportowca Nie jest wymagana definicja |
|
3 Co nazywa się wynikiem testu? |
Ocena ilościowa jakości lub stanu sportowca Pomiar lub badanie w celu określenia stanu lub stanu sportowca Proces badania, który określa jakość lub stan sportowca Nie jest wymagana definicja |
|
4 Jaki rodzaj testów robi bieganie 100 metrów? | |
|
5 Jaki rodzaj testów robi dynamometria ręczna? |
Ćwiczenie kontrolne Test funkcjonalny Maksymalny test funkcjonalny |
|
6 Do jakiego rodzaju testów należy próbka? IPC? |
Ćwiczenie kontrolne Test funkcjonalny Maksymalny test funkcjonalny |
|
7 Jaki rodzaj testów robi trzyminutowy bieg pod metronomem? |
Ćwiczenie kontrolne Test funkcjonalny Maksymalny test funkcjonalny |
|
8 Jaki rodzaj testów robi maksymalna ilość podciągnięć na drążku? |
Ćwiczenie kontrolne Test funkcjonalny Maksymalny test funkcjonalny |
|
9 W jakim przypadku test jest uważany za informacyjny? | |
|
10 Kiedy test jest uważany za wiarygodny? |
Zdolność testu do odtworzenia wyników podczas ponownego badania Zdolność testu do pomiaru jakości sportowca będącego przedmiotem zainteresowania Niezależność wyników testu od osoby przeprowadzającej test |
|
11 Kiedy test jest uważany za obiektywny? |
Zdolność testu do odtworzenia wyników podczas ponownego badania Zdolność testu do pomiaru jakości sportowca będącego przedmiotem zainteresowania Niezależność wyników testu od osoby przeprowadzającej test |
|
12 Jakie kryterium jest konieczne przy ocenie testu pod kątem zawartości informacji? | |
|
13 Jakie kryterium jest potrzebne przy ocenie testu rzetelności? |
Kryterium t-Studenta F-Kryterium Fishera Współczynnik korelacji Współczynnik determinacji Wariancja |
|
14 Jakie kryterium jest potrzebne przy ocenie testu pod kątem obiektywności? |
Kryterium t-Studenta F-Kryterium Fishera Współczynnik korelacji Współczynnik determinacji Wariancja |
|
15 Jak nazywa się informacyjność testu, jeśli służy do oceny stopnia wytrenowania sportowca? | |
|
16 Jaką informacyjnością ćwiczeń kontrolnych kieruje się trener przy doborze dzieci do swojej sekcji sportowej? |
Logiczna empiryczna diagnostyka predykcyjna |
|
17 Czy do oceny informacyjności testów konieczna jest analiza korelacji? | |
|
18 Czy analiza czynnikowa jest konieczna do oceny informatywności testów? | |
|
19 Czy można ocenić wiarygodność testu za pomocą analizy korelacji? | |
|
20 Czy można ocenić obiektywność testu za pomocą analizy korelacji? | |
|
21 Czy testy mające na celu ocenę ogólnej sprawności fizycznej będą równoważne? | |
|
22 Podczas pomiaru tej samej jakości za pomocą różnych testów stosuje się testy ... |
Zaprojektowane do pomiaru tej samej jakości Posiadanie wysokiej korelacji między sobą Posiadanie niskiej korelacji między sobą |
PODSTAWY TEORII OCENY
Do oceny wyników sportowych często stosuje się specjalne tabele wyników. Celem takich tabel jest zamiana pokazanego wyniku sportowego (wyrażonego w miarach obiektywnych) na punkty warunkowe. Prawo przeliczania wyników sportowych na punkty nazywa się Skala ocen... Skalę można określić jako wyrażenie matematyczne, tabelę lub wykres. Istnieją 4 główne rodzaje wag stosowanych w sporcie i wychowaniu fizycznym.
Skale proporcjonalne
Skale regresji
Skale progresywne.
Skale proporcjonalne implikują naliczenie tej samej liczby punktów za równy wzrost wyników (np. za każde 0,1 s poprawy wyniku w biegu na 100 m przyznaje się 20 punktów). Takie wagi są używane w nowoczesnym pięcioboju, łyżwiarstwie szybkim, narciarstwie, kombinacji norweskiej, biathlonie i innych sportach.
Skale regresji implikują naliczenie, za taki sam wzrost wyniku, jak wzrost osiągnięć sportowych, coraz mniejszą liczbę punktów (np. za poprawę wyniku biegu na 100 m z 15, 0 do 14,9 s dodaje się 20 punktów, oraz za 0,1 s w zakresie 10,0-9,9 s - tylko 15 punktów).
Skale progresywne. Tutaj im wyższy wynik sportowy, tym więcej punktów rośnie jego poprawa (np. 10 punktów dodaje się za poprawę czasu biegu z 15,0 do 14,9 s, a 100 punktów z 10,0 do 9,9 s). Wagi progresywne są używane w pływaniu, niektórych rodzajach lekkoatletyki i podnoszeniu ciężarów.
Łuski sigmoidalne są rzadko stosowane w sporcie, ale są powszechnie stosowane w ocenie sprawności fizycznej (tak np. wygląda skala standardów sprawności fizycznej populacji USA). W tych skalach oszczędnie zachęca się do poprawy wydajności w strefach bardzo niskiej i bardzo wysokiej wydajności; najwięcej punktów zdobywa wzrost wyników w strefie średnich osiągnięć.
Główne cele oceny to:
porównać różne osiągnięcia w tym samym zadaniu;
porównać osiągnięcia w różnych zadaniach;
określić normy.
Norma w metrologii sportowej wywoływana jest wartość graniczna wyniku, która służy jako podstawa do przypisania sportowca do jednej z grup klasyfikacyjnych. Istnieją trzy rodzaje norm: porównawcze, indywidualne i należne.
Normy porównawcze opierają się na porównaniu osób należących do tej samej populacji. Na przykład podział osób na podgrupy według stopnia odporności (wysoki, średni, niski) lub reaktywności (hiperreaktywny, normoreaktywny, hiporeaktywny) na hipoksję.
Różne stopnie ocen i norm
|
Procent badanych |
Normy w wagach |
||||||||
|
Werbalny |
w punktach |
Percentyl |
|||||||
|
Bardzo niski |
Poniżej M - 2 | ||||||||
|
Od M - 2 do M - 1 | |||||||||
|
Poniżej średniej |
Od M-1 do M-0,5 | ||||||||
|
Od M – 0,5 do M + 0,5 | |||||||||
|
Powyżej średniej |
Od M + 0,5 do M + 1 | ||||||||
|
Od M + 1 do M + 2 | |||||||||
|
Bardzo wysoko |
Powyżej M + 2 | ||||||||
Normy te charakteryzują jedynie sukces komparatywny badanych w danej populacji, ale nie mówią nic o populacji jako całości (lub średniej). Dlatego też wskaźniki porównawcze należy porównywać z danymi z innych populacji i stosować w połączeniu z indywidualnymi i właściwymi wskaźnikami.
Normy indywidualne na podstawie porównania wyników tego samego sportowca w różnych stanach. Na przykład w wielu dyscyplinach sportowych nie ma związku między masą ciała a wynikami sportowymi. Każdy sportowiec ma indywidualnie optymalną wagę odpowiadającą stanowi formy sportowej. Tempo to można kontrolować na różnych etapach treningu sportowego.
Stosowne normy opiera się na analizie tego, co dana osoba powinna umieć skutecznie radzić sobie z zadaniami, jakie stawia przed nim życie. Przykładem mogą być standardy poszczególnych kompleksów do treningu fizycznego, właściwe wartości VC, podstawowe tempo przemiany materii, masa i wzrost ciała itp.
|
1 Czy można bezpośrednio zmierzyć jakość wytrzymałości? | |
|
2 Czy można bezpośrednio zmierzyć jakość prędkości? | |
|
3 Czy można bezpośrednio zmierzyć jakość zręczności? | |
|
4 Czy można bezpośrednio zmierzyć jakość elastyczności? | |
|
5 Czy można bezpośrednio zmierzyć siłę poszczególnych mięśni? | |
|
6 Czy ocenę można wyrazić w postaci cechy jakościowej (dobra, zadowalająca, zła, kredytowa itp.)? | |
|
7 Czy istnieje różnica między skalą pomiarową a skalą ocen? | |
|
8 Co to jest skala ocen? |
System pomiaru wyników sportowych Prawo przeliczania wyników sportowych na punkty System oceny norm |
|
9 Skala zakłada naliczenie tej samej liczby punktów za równy wzrost wyników. Ono … | |
|
10 Za taki sam wzrost wyniku przyznawana jest mniejsza liczba punktów wraz ze wzrostem osiągnięć sportowych. Ono … |
Skala progresywna Skala regresyjna Skala proporcjonalna Skala sigmoidalna |
|
11 Im wyższy wynik sportowy, tym więcej punktów szacuje się za jego poprawę. Ono … |
Skala progresywna Skala regresyjna Skala proporcjonalna Skala sigmoidalna |
|
12 Oszczędnie zachęca się do poprawy wydajności na obszarach o bardzo niskiej i bardzo wysokiej wydajności; najwięcej punktów zdobywa wzrost wyników w strefie średnich osiągnięć. Ono … |
Skala progresywna Skala regresyjna Skala proporcjonalna Skala sigmoidalna |
|
13 Normy oparte na porównaniu osób należących do tej samej populacji nazywane są ... | |
|
14 Normy oparte na porównaniu wyników tego samego sportowca w różnych stanach nazywają się ... |
Standardy indywidualne Odpowiednie standardy Standardy porównawcze |
|
15 Normy oparte na analizie tego, co dana osoba powinna umieć zrobić, aby poradzić sobie z powierzonymi jej zadaniami, nazywają się… |
Standardy indywidualne Odpowiednie standardy Standardy porównawcze |
PODSTAWOWE POJĘCIA JAKOŚCI
Jakość(łac. qualitas – jakość, metron – miara) bada i opracowuje ilościowe metody oceny cech jakościowych.
Qualimetria opiera się na kilku założeniach:
Każda jakość może być zmierzona;
Jakość zależy od wielu właściwości, które tworzą „drzewo jakości” (na przykład drzewo jakości wykonania ćwiczeń w łyżwiarstwie figurowym składa się z trzech poziomów - wyższego, średniego, niższego);
Każda właściwość jest zdefiniowana przez dwie liczby: indeks względny i wagę; suma wag właściwości na każdym poziomie jest równa jeden (lub 100%).
Techniki metodologiczne jakościowe dzielą się na dwie grupy:
Heurystyczna (intuicyjna) oparta na ocenach ekspertów i kwestionariuszach;
Instrumentalny.
Ekspert nazywa się oszacowaniem uzyskanym po zasięgnięciu opinii specjalistów. Typowe przykłady kompetencji: sędziowanie w gimnastyce i łyżwiarstwie figurowym, konkurs na najlepszą pracę naukową itp.
Badanie obejmuje następujące główne etapy: sformułowanie celu, dobór ekspertów, wybór metodologii, badanie i przetwarzanie otrzymanych informacji, w tym ocenę spójności poszczególnych ocen eksperckich. Podczas badania duże znaczenie ma stopień zgodności opinii ekspertów, oceniany wartością współczynnik korelacji rang(w przypadku kilku ekspertów). Należy zauważyć, że korelacja rang leży u podstaw rozwiązania wielu problemów jakościowych, ponieważ umożliwia obliczenia matematyczne o cechach jakościowych.
W praktyce wskaźnikiem kwalifikacji eksperta jest często odchylenie jego ocen od średnich ocen grupy ekspertów.
Pytający nazywana jest metodą zbierania opinii poprzez wypełnianie ankiet. Kwestionariusz wraz z wywiadem i rozmową nawiązuje do metod badania ankietowego. W przeciwieństwie do wywiadów i rozmów, badanie ankietowe zakłada pisemne odpowiedzi osoby wypełniającej ankietę - respondenta - na system ustandaryzowanych pytań. Pozwala na badanie motywów zachowań, intencji, opinii itp.
Za pomocą ankiet można rozwiązać wiele praktycznych problemów w sporcie: ocena stanu psychicznego sportowca; jego stosunek do charakteru i przedmiotu szkoleń; relacje interpersonalne w zespole; własna ocena gotowości technicznej i taktycznej; ocena diety i wiele innych.
|
1 Co bada kalimetria? |
Badanie jakości testów Badanie jakościowych właściwości cechy Badanie i opracowywanie ilościowych metod oceny jakości |
|
2 Metody matematyczne stosowane w kalimetrii? |
Korelacja parami Korelacja rang Analiza wariancji |
|
3 Jakie metody są stosowane do oceny poziomu wydajności? | |
|
4 Jakie metody stosuje się do oceny różnorodności elementów technicznych? |
Metoda ankietowa Metoda ocen eksperckich Metoda nieokreślona |
|
5 Jakie metody stosuje się do oceny złożoności elementów technicznych? |
Metoda ankietowa Metoda ocen eksperckich Metoda nieokreślona |
|
6 Jakie metody stosuje się do oceny stanu psychicznego sportowca? |
Metoda ankietowa Metoda ocen eksperckich Metoda nieokreślona |
Pierwszy komponent, teoria testów, zawiera opis modeli statystycznych do przetwarzania danych diagnostycznych. Zawiera modele do analizy odpowiedzi w pozycjach testowych oraz modele do obliczania łącznych wyników testów. Mellenberg (1980, 1990) nazwał to „psychometrią”. Klasyczna teoria testów, nowoczesna teoria testów (lub model analizy odpowiedzi na pozycje testowe - IRT) i model
przykładowe pozycje stanowią trzy najważniejsze typy modeli teorii testów. Przedmiotem psychodiagnostyki są dwa pierwsze modele.
Klasyczna teoria testów. Większość testów inteligencji i osobowości została opracowana na podstawie tej teorii. Centralnym pojęciem tej teorii jest pojęcie „niezawodności”. Niezawodność odnosi się do spójności wyników po ponownej ocenie. W podręcznikach pojęcie to jest zwykle przedstawiane bardzo krótko, a następnie podaje się szczegółowy opis aparatu statystyki matematycznej. W tym wstępnym rozdziale przedstawiamy zwięzły opis głównego znaczenia wspomnianego pojęcia. W klasycznej teorii testów rzetelność rozumiana jest jako powtarzalność wyników kilku procedur pomiarowych (głównie pomiarów z wykorzystaniem testów). Niezawodność polega na obliczeniu błędu pomiaru. Wyniki uzyskane podczas procesu testowania można przedstawić jako sumę wyniku prawdziwego i błędu pomiaru:
Xi = Ti+ j
gdzie Xi jest oceną otrzymanych wyników, Ti jest wynikiem rzeczywistym, a j- błąd pomiaru.
Ocena uzyskanych wyników to z reguły liczba poprawnych odpowiedzi na zadania testowe. Prawdziwy wynik można postrzegać jako prawdziwe oszacowanie w sensie platońskim (Gulliksen, 1950). Pojęcie oczekiwanych rezultatów jest szeroko rozpowszechnione, tj. pomysły na temat punktów, które można uzyskać w wyniku dużej liczby powtórzeń procedur pomiarowych (Pan & Novich, 1968). Nie jest jednak możliwe przeprowadzenie tej samej procedury oceny z jedną osobą. Dlatego konieczne jest poszukiwanie innych rozwiązań problemu (Witlman, 1988).
W ramach tej koncepcji przyjmuje się pewne założenia dotyczące prawdziwych wyników i błędów pomiarowych. Te ostatnie są traktowane jako czynnik niezależny, co oczywiście jest zasadnym założeniem, ponieważ losowe wahania wyników nie dają kowariancji: r EE = 0.
Zakłada się, że nie ma korelacji między wynikami rzeczywistymi a błędami pomiaru: r EE = 0.
Całkowity błąd wynosi 0, ponieważ średnia arytmetyczna jest traktowana jako prawdziwe oszacowanie:
Założenia te prowadzą w końcu do dobrze znanej definicji rzetelności jako stosunku wyniku prawdziwego do całkowitej wariancji lub wyrażenia: 1 minus stosunek, którego licznikiem jest błąd pomiaru, a w mianowniku - całkowita wariancja :
 , LUB
, LUB 
Z tego wzoru na określenie niezawodności otrzymujemy, że wariancja błędu S2 (E) jest równa całkowitej wariancji liczby przypadków (1 - r XX "), a zatem błąd standardowy pomiaru określa wzór:
![]()
Po teoretycznym uzasadnieniu rzetelności i jej pochodnych konieczne jest wyznaczenie wskaźnika rzetelności danego testu. Istnieją praktyczne procedury oceny wiarygodności testów, takie jak stosowanie wymiennych form (testy równoległe), dzielenie pozycji na dwie części, ponowne testowanie i mierzenie spójności wewnętrznej. Każda referencja zawiera indeksy stałości wyników badań:
r XX ’= r (x 1, x 2)
gdzie r XX ’ jest współczynnikiem stabilności, a x 1 oraz x 2 - wyniki dwóch pomiarów.
Koncepcja niezawodności wymiennych form została wprowadzona i rozwinięta przez Gulliksena (1950). Ta procedura jest dość pracochłonna, ponieważ wiąże się z koniecznością stworzenia równoległej serii zadań.
r XX ’= r (x 1, x 2)
gdzie r XX ’ jest współczynnikiem równoważności, a x 1 oraz x 2 - dwa równoległe testy.
Kolejna procedura – podział głównego testu na dwie części A i B – jest łatwiejsza w użyciu. Uzyskane wskaźniki dla obu części testu są skorelowane. Za pomocą wzoru Spearmana-Browna ocenia się wiarygodność testu jako całości:
gdzie A i B to dwie równoległe części testu.
Kolejną metodą jest określenie wewnętrznej spójności pozycji testowych. Metoda ta opiera się na określeniu kowariancji poszczególnych pozycji. Sg to wariancja losowo wybranej pozycji, a Sgh to kowariancja dwóch losowo wybranych pozycji. Najczęściej stosowanym współczynnikiem do określania spójności wewnętrznej jest „współczynnik alfa” Cronbacha. Formuła jest również używana KP20 i λ-2(lambda-2).
W klasycznej koncepcji niezawodności wyznaczane są błędy pomiaru występujące zarówno podczas testowania, jak i podczas obserwacji. Źródła tych błędów są różne: mogą to być cechy osobowe, specyfika warunków testowych oraz same zadania testowe. Istnieją określone metody obliczania błędów. Wiemy, że nasze obserwacje mogą okazać się błędne, nasze narzędzia metodologiczne są niedoskonałe, tak jak niedoskonali są sami ludzie. (Jak nie pamiętać Szekspira: „Jesteś niewiarygodny, którego imię to człowiek”). Fakt, że w klasycznej teorii testów wyjaśnia się i wyjaśnia błędy pomiarowe, jest ważnym pozytywnym punktem.
Klasyczna teoria testów ma szereg istotnych cech, które można uznać za jej wady. Niektóre z tych cech są odnotowywane w leksykonach, ale ich znaczenie (z codziennego punktu widzenia) jest rzadko podkreślane, podobnie jak nie zauważa się, że z teoretycznego czy metodologicznego punktu widzenia należy je uznać za wady.
Najpierw. Klasyczna teoria testów i koncepcja niezawodności skupiają się na obliczeniu całkowitych wskaźników testowych, które są wynikiem zsumowania szacunków uzyskanych w osobnych zadaniach. Tak więc podczas pracy
Druga. Współczynnik rzetelności zakłada oszacowanie wielkości rozrzutu mierzonych wskaźników. Wynika z tego, że współczynnik rzetelności będzie niższy, jeśli (przy równości innych wskaźników) próba będzie bardziej jednorodna. Nie ma jednego współczynnika spójności wewnętrznej pozycji testowych, współczynnik ten jest zawsze „kontekstowy”. Na przykład Crocker i Aljina (1986) proponują specjalną formułę „jednorodnej korekty próbki” przeznaczoną dla najwyższych i najniższych wyników uzyskanych przez osoby poddawane testom. Diagnosta powinien znać charakterystykę zmienności w próbie, w przeciwnym razie nie będzie mógł wykorzystać do tego testu współczynników zgodności wewnętrznej określonych w instrukcji.
Trzeci. Zjawisko redukcji do średniej arytmetycznej jest logiczną konsekwencją klasycznej koncepcji niezawodności. Jeśli wynik testu się zmienia (tj. nie jest wystarczająco wiarygodny), to jest całkiem możliwe, że gdy procedura zostanie powtórzona, osoby z niskimi wynikami otrzymają wyższe wyniki i odwrotnie, osoby z wysokimi wynikami otrzymają niskie wyniki. Tego artefaktu procedury pomiarowej nie można pomylić z prawdziwą zmianą lub przejawem procesów rozwojowych. Ale jednocześnie nie jest łatwo je odróżnić, tk. nigdy nie można wykluczyć możliwości zmian w toku rozwoju. Dla pełnego zaufania konieczne jest „porównanie z grupą kontrolną.
Czwartą cechą testów zaprojektowanych zgodnie z zasadami teorii klasycznej jest dostępność danych normatywnych. Znajomość norm testowych pozwala badaczowi na odpowiednią interpretację wyników testowanego. Poza normą wyniki testów są bez znaczenia. Opracowanie norm testowych jest dość kosztownym przedsięwzięciem, ponieważ psycholog musi uzyskać wyniki testów na reprezentatywnej próbie.
2 Ya ter Laak
Jeśli mówimy o wadach klasycznego pojęcia niezawodności, to należy przytoczyć stwierdzenie Si-tsmy (1992, s. 123-125). Zauważa, że pierwszym i najważniejszym założeniem klasycznej teorii testów jest to, że wyniki testów są zgodne z zasadą przedziału. Nie ma jednak badań potwierdzających to założenie. W istocie jest to „pomiar według arbitralnie ustalonej reguły”. Cecha ta stawia klasyczną teorię testów w mniej korzystnej pozycji w porównaniu ze skalami pomiaru postaw i oczywiście w porównaniu z nowoczesną teorią testów. Wiele metod analizy danych (analiza wariancji, analiza regresji, analiza korelacji i analiza czynnikowa) opiera się na założeniu istnienia skali przedziałowej. Nie ma jednak solidnych podstaw. Można jedynie założyć, że skala prawdziwych wyników jest skalą wartości cech psychologicznych (na przykład zdolności arytmetycznych, inteligencji, neurotyzmu).
Druga uwaga dotyczy tego, że wyniki testu nie są bezwzględnymi wskaźnikami tej lub innej cechy psychologicznej badanej osoby, należy je traktować jedynie jako wyniki wykonania tego lub innego testu. Dwa testy mogą twierdzić, że badają te same cechy psychologiczne (na przykład inteligencja, zdolności werbalne, ekstrawersja), ale nie oznacza to, że oba testy są równoważne i mają takie same możliwości. Porównywanie wydajności dwóch badanych osób z różnymi testami jest błędne. To samo dotyczy zdania dwóch różnych testów z tego samego przedmiotu. Trzecia uwaga odnosi się do założenia, że błąd standardowy pomiaru jest taki sam dla każdego poziomu mierzalnej zdolności jednostki. Nie ma jednak testu empirycznego dla tego założenia. Na przykład nie ma gwarancji, że zdający z dobrymi zdolnościami matematycznymi uzyska wysokie wyniki podczas pracy ze stosunkowo prostym testem arytmetycznym. W takim przypadku osoba o niskich lub przeciętnych zdolnościach z większym prawdopodobieństwem otrzyma wysoką ocenę.
W ramach nowoczesnej teorii testów lub teorii analizy odpowiedzi pozycje testowe zawierają opis dużej
liczba modeli możliwych odpowiedzi respondentów. Modele te różnią się podstawowymi założeniami, a także wymaganiami w stosunku do uzyskanych danych. Model Rush jest często postrzegany jako synonim teorii analizy odpowiedzi na pytania w teście (1RT). W rzeczywistości to tylko jeden z modeli. Przedstawiony w nim wzór opisujący krzywą charakterystyczną dla ustawienia g jest następujący:

gdzie g- oddzielne zadanie testowe; do potęgi- funkcja wykładnicza (zależność nieliniowa); δ („Delta”) - poziom trudności testu.
Inne przedmioty testowe, takie jak h, również uzyskać własne charakterystyczne krzywe. Spełnienie warunku δ h> δ g (g oznacza, że h- trudniejsze zadanie. Dlatego dla dowolnej wartości wskaźnika Θ ("Theta" - utajone właściwości zdolności zdających) prawdopodobieństwo pomyślnego wykonania zadania h mniejszy. Model ten nazywany jest ścisłym, ponieważ oczywiste jest, że przy niskim stopniu ekspresji cechy prawdopodobieństwo wykonania zadania jest bliskie zeru. W tym modelu nie ma miejsca na zgadywanie lub zgadywanie. W przypadku zadań z opcjami nie ma potrzeby zakładania prawdopodobieństwa sukcesu. Ponadto model ten jest ścisły w tym sensie, że wszystkie pozycje testowe muszą mieć taką samą zdolność dyskryminacyjną (wysoka dyskryminacja znajduje odzwierciedlenie w nachyleniu krzywej; tutaj można skonstruować skalę Guttmanna, zgodnie z którą w każdym punkcie krzywa charakterystyczna prawdopodobieństwo wykonania zadania waha się od 0 do 1). Z tego powodu nie wszystkie przypisania można uwzględnić w testach opartych na modelu Rush.
Istnieje kilka wariantów tego modelu (np. Birnbaura, 1968, See Lord & Novik). Pozwala na istnienie zadań o różnej rozróżnialności
umiejętność.
Holenderski badacz Mokken (1971) opracował dwa modele analizy odpowiedzi w pozycjach testowych, których wymagania nie są tak rygorystyczne jak w modelu Rush, a zatem być może bardziej realistyczne. Jako główny warunek
Viya Mokken wysuwa stanowisko, że krzywa charakterystyczna zadania powinna podążać monotonnie, bez przerw. Jednocześnie wszystkie zadania testowe mają na celu zbadanie tych samych cech psychologicznych, które należy zmierzyć v. Każda forma tej zależności jest dozwolona, o ile nie zostanie przerwana. Dlatego o kształcie krzywej charakterystycznej nie decyduje żadna konkretna funkcja. Ta „swoboda” pozwala na użycie większej liczby pozycji na teście, a poziom oceny nie jest wyższy niż zwykły.
Metodologia modeli odpowiedzi dla pozycji testowych (IRT) różni się od metodologii większości badań eksperymentalnych i korelacyjnych. Model matematyczny przeznaczony jest do badania cech behawioralnych, poznawczych, emocjonalnych, a także zjawisk rozwojowych. Te rozważane zjawiska są często ograniczone do odpowiedzi na zadania, co skłoniło Mellenberga (1990) do określenia IRT jako „mini-teorii mini-zachowania”. Wyniki badań można w pewnym stopniu przedstawić jako krzywe zgodności, zwłaszcza w przypadkach, gdy brak jest teoretycznego zrozumienia badanych cech. Do tej pory dysponujemy jedynie kilkoma testami inteligencji, zdolności i osobowości, stworzonymi na podstawie licznych modeli teorii IRT. Warianty modelu Rusha są częściej stosowane w projektowaniu testów osiągnięć (Verhelst, 1993), podczas gdy modele Mockena są bardziej dostosowane do zjawisk rozwojowych (patrz także Rozdział 6).
Podstawową jednostką modeli IRT jest odpowiedź osoby badanej na pozycje testowe. Rodzaj odpowiedzi zależy od nasilenia badanej cechy u osoby. Taką cechą może być na przykład zdolność arytmetyczna lub przestrzenna. W większości przypadków jest to taki lub inny aspekt inteligencji, cechy osiągnięć lub cechy osobowości. Zakłada się, że istnieje nieliniowa zależność między pozycją tej konkretnej osoby w pewnym zakresie badanej cechy a prawdopodobieństwem pomyślnego wykonania określonego zadania. Nieliniowość tej relacji jest w pewnym sensie intuicyjna. Znane zwroty „Każdy początek jest trudny” (powoli
liniowy start) oraz „Zostać świętym nie jest takie łatwe” oznaczają, że dalsza poprawa po osiągnięciu pewnego poziomu jest trudna. Krzywa powoli się zbliża, ale prawie nigdy nie osiąga 100% skuteczności.
Niektóre modele z większym prawdopodobieństwem zaprzeczają naszemu intuicyjnemu rozumieniu. Weźmy ten przykład. Osoba ze wskaźnikiem nasilenia arbitralnej cechy równym 1,5 ma 60-procentowe prawdopodobieństwo powodzenia zadania. Przeczy to naszemu intuicyjnemu pojmowaniu takiej sytuacji, ponieważ albo można z powodzeniem poradzić sobie z zadaniem, albo w ogóle sobie z nim nie poradzić. Weźmy ten przykład: 100 razy osoba próbuje osiągnąć wysokość 1 m 50 cm, sukces towarzyszy mu 60 razy, tj. ma 60-procentowy wskaźnik sukcesu.
Aby ocenić powagę cechy, wymagane są co najmniej dwa zadania. Model Rush zakłada określenie nasilenia cech, niezależnie od stopnia trudności zadania. To również przeczy naszemu intuicyjnemu rozumieniu: załóżmy, że dana osoba ma 80 procentowe prawdopodobieństwo skoku powyżej 1,30 m. Jeśli tak, to zgodnie z krzywą charakterystyczną zadań ma 60 procentowe prawdopodobieństwo skoku powyżej 1,50 m i 40 procentowe. prawdopodobieństwo skoku powyżej 1,70 m. Dlatego niezależnie od wartości zmiennej niezależnej (wysokość) można ocenić zdolność osoby do skoku na wysokość.
Istnieje około 50 modeli IRT (Goldstein i Wood, 1989) Istnieje wiele funkcji nieliniowych, które opisują (wyjaśniają) prawdopodobieństwo powodzenia zadania lub grupy zadań. Wymagania i ograniczenia tych modeli są różne, a różnice te można znaleźć porównując model Rush i skalę Mockena. Wymagania tych modeli obejmują:
1) konieczność określenia badanych cech i oceny pozycji osoby w zakresie tej cechy;
2) ocena kolejności zadań;
3) weryfikacja konkretnych modeli. W psychometrii opracowano wiele procedur testowania modelu.
W niektórych książkach referencyjnych teoria IRT jest uważana za formę analizy elementów testowych (zob. na przykład
Croker i Algina, J 986). Można jednak argumentować, że teoria IRT jest „mini-teorią mini-zachowania”. Zwolennicy teorii IRT zauważają, że jeśli koncepcje (modele) średniego poziomu są niedoskonałe, to co z bardziej złożonymi konstrukcjami w psychologii?
Klasyczna i współczesna teoria testów. Ludzie nie mogą nie porównywać rzeczy, które wyglądają prawie tak samo. (Być może codzienny odpowiednik psychometrii polega głównie na porównywaniu ludzi według istotnych cech i wybieraniu między nimi). Każda z przedstawionych teorii – zarówno teoria pomiaru błędów estymacji, jak i matematyczny model odpowiedzi na pozycje testowe – ma swoich zwolenników (Goldstein i Wood, 1986).
Modelom IRT nie zarzuca się, że są „oparte na regułach”, w przeciwieństwie do klasycznej teorii testów. Model IRT koncentruje się na analizie ocenianych cech. Cechy osobowości i cechy zadaniowe są oceniane za pomocą skal (porządkowych lub interwałowych). Ponadto możliwe jest porównanie wskaźników wydajności różnych testów mających na celu zbadanie podobnych cech. Wreszcie wiarygodność nie jest taka sama dla każdej wartości na skali, a średnie są ogólnie bardziej wiarygodne niż te na początku i na końcu skali. W związku z tym modele IRT wydają się być bardziej zaawansowane teoretycznie. Istnieją również różnice w praktycznym wykorzystaniu nowoczesnej teorii testów i teorii klasycznej (Sijstma, 1992, s. 127-130). Współczesna teoria testów jest bardziej złożona niż klasyczna teoria testów, dlatego jest rzadziej używana przez niespecjalistów. Ponadto IRT ma specjalne wymagania dotyczące zadań. Oznacza to, że przedmioty powinny być wykluczone z testu, jeśli nie spełniają wymagań modelu. Zasada ta dotyczy również tych zadań, które były częścią szeroko stosowanych testów, zbudowanych zgodnie z zasadami teorii klasycznej. Test staje się krótszy, a przez to mniej wiarygodny.
IRT oferuje modele matematyczne do badania zjawisk w świecie rzeczywistym. Modele powinny pomóc nam zrozumieć kluczowe aspekty tych zjawisk. Jest tu jednak podstawowe pytanie teoretyczne. Modele mogą być brane pod uwagę
jako podejście do badania złożonej rzeczywistości, w której żyjemy. Ale model i rzeczywistość to nie to samo. Według pesymistycznego poglądu można modelować tylko pojedyncze (i co więcej nie najciekawsze) typy zachowań. Można też znaleźć stwierdzenie, że rzeczywistość w ogóle nie podlega modelowaniu, ponieważ przestrzega nie tylko praw przyczyny i skutku. W najlepszym razie możliwe jest modelowanie indywidualnych (idealnych) zjawisk behawioralnych. Istnieje inny, bardziej optymistyczny pogląd na możliwości modelowania. Powyższe stanowisko blokuje możliwość dogłębnego zrozumienia natury zjawisk ludzkiego zachowania. Zastosowanie tego czy innego modelu rodzi pewne ogólne, fundamentalne pytania. Naszym zdaniem nie ulega wątpliwości, że IRT jest pojęciem teoretycznie i technicznie przewyższającym klasyczną teorię testów.
Praktycznym celem testów, niezależnie od podstawy teoretycznej, na jakiej zostały stworzone, jest zdefiniowanie istotnych kryteriów i ustalenie na ich podstawie cech pewnych konstruktów psychologicznych. Czy model IRT ma również zalety pod tym względem? Możliwe, że testy oparte na tym modelu nie dają dokładniejszej prognozy niż testy oparte na teorii klasycznej i możliwe, że ich wkład w rozwój konstruktów psychologicznych nie jest ważniejszy. Diagnostycy preferują kryteria, które są bezpośrednio związane z jednostką, instytucją lub społecznością. Bardziej zaawansowany naukowo model „ipso facto” * nie definiuje bardziej odpowiedniego kryterium i jest nieco ograniczony w wyjaśnianiu konstruktów naukowych. Oczywiste jest, że rozwój testów opartych na teorii klasycznej będzie kontynuowany, ale jednocześnie powstaną nowe modele IRT, rozszerzające się na badanie większej liczby zjawisk psychologicznych.
W klasycznej teorii testów rozróżnia się pojęcia „niezawodności” i „ważności”. Wyniki badań powinny być wiarygodne, tj. wyniki badania wstępnego i ponownego powinny być spójne. Oprócz,
* tym samym(lakier) - sam (tłum. ok.).
wyniki powinny być wolne (w miarę możliwości) od błędów oszacowań. Obecność ważności jest jednym z wymagań dla uzyskanych wyników. W tym przypadku wiarygodność jest uważana za konieczny, ale jeszcze nie wystarczający warunek ważności testu.
Trafność zakłada, że uzyskane wyniki są związane z czymś o znaczeniu praktycznym lub teoretycznym. Wnioski wyciągnięte z wyników testu muszą być aktualne. Najczęściej mówią o dwóch typach trafności: predykcyjnej (kryterialnej) i konstrukcyjnej. Istnieją również inne rodzaje ważności (zob. rozdział 3). Ponadto zasadność można określić w przypadku quasi-eksperymentów (Cook i Campbell, 1976, Cook & Shadish, 1994). Jednak nadal głównym typem trafności jest trafność predykcyjna, rozumiana jako zdolność do przewidzenia na podstawie wyniku testu czegoś istotnego na temat zachowania w przyszłości, a także możliwość głębszego zrozumienia określonej właściwości lub jakości psychologicznej.
Przedstawione rodzaje trafności są omówione w każdym podręczniku i towarzyszy im opis metod analizy trafności testu. Analiza czynnikowa jest bardziej odpowiednia do określenia walidacji konstruktu, a równania regresji liniowej są używane do analizy trafności predykcyjnej. Te lub inne cechy (wyniki w nauce, skuteczność terapii) można przewidzieć na podstawie jednego lub więcej wskaźników uzyskanych podczas pracy z testami intelektualnymi lub osobowościowymi. Techniki przetwarzania danych, takie jak korelacja, regresja, analiza wariancji, analiza korelacji cząstkowych i wariancji są wykorzystywane do określenia trafności predykcyjnej testu.
Często opisuje się również ważność treści. Zakłada się, że wszystkie zadania i zadania testu powinny należeć do określonego obszaru (właściwości psychiczne, zachowanie itp.). Pojęcie trafności znaczącej charakteryzuje zgodność każdego zadania testowego z mierzonym obszarem. Trafność treści jest czasami postrzegana jako część solidności lub „uogólniania” (Cronbach, Gleser, Nanda & Rajaratnam, 1972). Jednak z
Wybierając pozycje do testów osiągnięć z określonego obszaru tematycznego, należy również zwrócić uwagę na zasady uwzględniania pozycji w teście.
W klasycznej teorii testów rzetelność i trafność są uważane za stosunkowo niezależne od siebie. Ale jest też inne rozumienie związku między tymi pojęciami. Współczesna teoria testów opiera się na zastosowaniu modeli. Parametry są oceniane w ramach określonego modelu. Jeżeli zadanie nie spełnia wymagań modelu, to w ramach tego modelu jest uznawane za nieważne. Walidacja konstrukcji jest częścią walidacji samego modelu. Walidacja ta odnosi się głównie do weryfikacji istnienia badanej jednowymiarowej cechy utajonej o znanych cechach skali. Wyniki skal można oczywiście wykorzystać do określenia odpowiednich kryteriów, a ich korelacja ze wskaźnikami innych konstruktów umożliwia zebranie informacji o trafności zbieżnej i rozbieżnej konstruktu.
Psychodiagnostyka jest analogiczna do języka, określanego jako jedność czterech komponentów, reprezentowanych na trzech poziomach. Pierwszy składnik, teoria testów, jest analogiczny do składni, gramatyki języka. Gramatyka generatywna (generatywna) jest z jednej strony genialnym modelem, z drugiej systemem, który podlega regułom. Za pomocą tych zasad zdania złożone są budowane na podstawie prostych zdań twierdzących. Jednocześnie jednak model ten pomija opis, w jaki sposób zorganizowany jest proces komunikacji (co jest przekazywane, a co postrzegane) oraz w jakim celu jest on realizowany. Aby to zrozumieć, wymagana jest dodatkowa wiedza. To samo można powiedzieć o teorii testów: jest w psychodiagnostyce niezbędna, ale nie jest w stanie wyjaśnić, czym zajmuje się psychodiagnosta i jakie są jego cele.
1.3.2. Teorie psychologiczne i konstrukty psychologiczne
Psychodiagnostyka to zawsze diagnoza czegoś konkretnego: cech osobowości, zachowania, myślenia, emocji. Testy mają na celu pomiar różnic indywidualnych. Istnieje kilka koncepcji
indywidualne różnice, z których każda ma swoje własne charakterystyczne cechy. Jeśli uznamy, że psychodiagnostyka nie ogranicza się tylko do oceny różnic indywidualnych, to inne teorie również nabierają istotnego znaczenia dla psychodiagnostyki. Przykładem jest ocena różnic w procesach rozwoju psychicznego oraz różnic w środowisku społecznym. Choć ocena różnic indywidualnych nie jest nieodzownym atrybutem psychodiagnostyki, istnieją jednak pewne tradycje badawcze w tym zakresie. Psychodiagnostyka rozpoczęła się od oceny różnic w inteligencji. Głównym zadaniem testów było „określenie odziedziczonego przekazu geniuszu” (Gallon) lub dobór dzieci do treningu (Binet, Simon). Pomiar ilorazu inteligencji otrzymał teoretyczne zrozumienie i praktyczny rozwój w pracach Spearmana (Wielka Brytania) i Thurstone (USA). Raymond B. Kettel zrobił podobną rzecz, aby ocenić cechy osobowości. Psychodiagnostyka staje się nierozerwalnie związana z teoriami i wyobrażeniami na temat indywidualnych różnic w osiągnięciach (ocena skrajnych możliwości) i formach zachowania (poziom typowego funkcjonowania). Tradycja ta obowiązuje do dziś. W podręcznikach z zakresu psychodiagnostyki różnice w środowisku społecznym są znacznie rzadziej oceniane w porównaniu z uwzględnianiem cech samych procesów rozwojowych. Nie ma na to rozsądnego wytłumaczenia. Z jednej strony diagnostyka nie ogranicza się do konkretnych teorii i koncepcji. Z drugiej strony potrzebuje teorii, ponieważ to w nich określa się diagnozowaną treść (czyli „co” jest diagnozowane). Na przykład inteligencję można uznać zarówno za ogólną cechę, jak i za podstawę wielu niezależnych zdolności. Jeśli psychodiagnostyka próbuje „uciec” od tej lub innej teorii, to zdroworozsądkowe idee stają się podstawą procesu psychodiagnostycznego. W badaniach wykorzystywane są różne metody analizy danych, a ogólna logika badań determinuje wybór konkretnego modelu matematycznego i determinuje strukturę stosowanych pojęć psychologicznych. Takie metody statystyki matematycznej
ki, jako analiza wariancji, analiza regresji, analiza czynnikowa, obliczanie korelacji zakładają istnienie zależności liniowych. W przypadku nieprawidłowego zastosowania tych metod „wprowadzają” one swoją strukturę do otrzymanych danych i użytych konstruktów.
Wyobrażenia o różnicach w środowisku społecznym io rozwoju osobowości nie miały prawie żadnego wpływu na psychodiagnostykę. Podręczniki (patrz np. Murphy i Davidshofer, 1988) uwzględniają klasyczną teorię testów i omawiają odpowiednie metody przetwarzania statystycznego, opisują znane testy, rozważają zastosowanie psychodiagnostyki w praktyce: w psychologii zarządzania, w doborze personelu, w ocenie psychologicznych cech osoby ...
Teorie różnic indywidualnych (a także wyobrażenia o różnicach między środowiskiem społecznym a rozwojem umysłowym) są podobne do badań semantyki języka. Jest to studium istoty, treści i znaczenia. Znaczenia są skonstruowane w określony sposób (jak konstrukty psychologiczne), na przykład przez podobieństwo lub kontrast (analogia, zbieżność, rozbieżność).
1.3.3. Testy psychologiczne i inne narzędzia metodologiczne
Trzecim elementem proponowanego schematu są testy, procedury i narzędzia metodologiczne, za pomocą których gromadzone są informacje o cechach osobowości. Draene i Siitsma (1990, s. 31) podają następu- wybrane lub teoretycznie uzasadnione cechy konkretnej strony ludzkiego zachowania (w ramach sytuacji testowej). Jednocześnie rozważana jest odpowiedź respondentów na pewną liczbę starannie dobranych bodźców, a otrzymane odpowiedzi są porównywane z normami testowymi ”.
Diagnostyka wymaga testów i technik gromadzenia wiarygodnych, dokładnych i ważnych informacji o funkcjach
oraz cechy osobowości, myślenie, emocje i zachowanie osoby. Oprócz opracowania procedur testowych, komponent ten zawiera również następujące pytania: jak tworzy się testy, jak formułuje się i wybiera zadania, jak przebiega proces testowania, jakie są wymagania dotyczące warunków testowych, w jaki sposób uwzględniane są błędy pomiarowe, w jaki sposób wyniki badań są obliczane i interpretowane.
W procesie projektowania testów wyróżnia się strategie racjonalne i empiryczne. Stosowanie strategii racjonalnej rozpoczyna się od zdefiniowania podstawowych pojęć (na przykład pojęć inteligencji, ekstrawersji) i zgodnie z tymi pomysłami formułowane są zadania testowe. Przykładem takiej strategii jest koncepcja teorii aspektu Guttmana (1957, 1968, 1978). Najpierw określane są różne aspekty konstruktów podstawowych, następnie zadania i zadania dobierane są w taki sposób, aby każdy z tych aspektów był uwzględniony. Druga strategia polega na tym, że zadania są wybierane na podstawie empirycznej. Na przykład, jeśli badacz próbuje stworzyć test zainteresowań zawodowych, który odróżniałby lekarzy od inżynierów, to procedura powinna wyglądać tak. Obie grupy respondentów muszą odpowiedzieć na wszystkie pozycje testowe, a te pozycje w odpowiedziach, w których stwierdzono statystycznie istotne różnice, są uwzględniane w ostatecznej wersji testu. Jeśli na przykład istnieją różnice między grupami w odpowiedziach na stwierdzenie „Uwielbiam łowienie ryb”, to stwierdzenie to staje się elementem testu. Głównym punktem tej książki jest to, że test jest powiązany z teorią pojęciową lub taksonomiczną, która definiuje te cechy.
Cel testu jest zwykle określony w instrukcji użytkowania. Test musi być ustandaryzowany, aby mógł mierzyć różnice między ludźmi, a nie między warunkami testowymi. Istnieją jednak odstępstwa od standaryzacji w procedurach zwanych testowaniem limitów i testami potencjału uczenia się. W tych warunkach respondent jest wspomagany w procesie
testowanie, a następnie ocena wpływu takiej procedury na wynik. Punktacja za odpowiedzi na zadania jest obiektywna, tj. przeprowadzone zgodnie ze standardową procedurą. Interpretacja uzyskanych wyników jest również ściśle określona i prowadzona w oparciu o normy testowe.
Trzeci składnik psychodiagnostyki – testy psychologiczne, narzędzia, procedury – zawiera pewne zadania, które są najmniejszymi jednostkami psychodiagnostyki iw tym sensie zadania są zbliżone do fonemów języka. Liczba możliwych kombinacji fonemów jest ograniczona. Tylko niektóre struktury fonemiczne mogą tworzyć słowa i zdania, które dostarczają informacji słuchaczowi. Także oraz zadania testowe: tylko w określonej kombinacji ze sobą mogą stać się skutecznym środkiem oceny odpowiedniego konstruktu.