Basic testing provisions. The main provisions of the classical theory of tests
What is testing
In accordance with IEEE STD 829-1983 Testing - This is a process for analyzing the software aimed at identifying differences between its actually existing and required properties (defect) and to evaluate the properties of software.
According to the GOST R ISO IEC 12207-99 in the life cycle of software, among other auxiliary processes of verification, certification, joint analysis and audit are determined. The verification process is the process of determining that software products operate in full compliance with the requirements or conditions implemented in previous works. This process may include analysis, verification and testing (testing). The certification process is the process of determining the completeness of the compliance of the established requirements created by the system or software product to be their functional intended. The process of joint analysis is the process of assessing states and, if necessary, the results of work (products) on the project. The audit process is the process of determining compliance with the requirements, plans and conditions of the contract. In the amount of these processes and make up what is commonly called testing.
Testing is based on test procedures with specific input data, initial conditions and expected result developed for a specific purpose, such as checking a separate program or verifying compliance to a certain requirement. Test procedures can check the various aspects of the program functioning - from the proper operation of a separate function before adequate implementation of business requirements.
When executing a project, it is necessary to take into account, in accordance with what standards and the requirements will be tested by the product. What tools will be (if there are) are used to search and document found defects. If you remember testing from the very beginning of the project, the testing of the product being developed will not deliver unpleasant surprises. So, the quality of the product is likely to be quite high.
Product Life Cycle and Testing
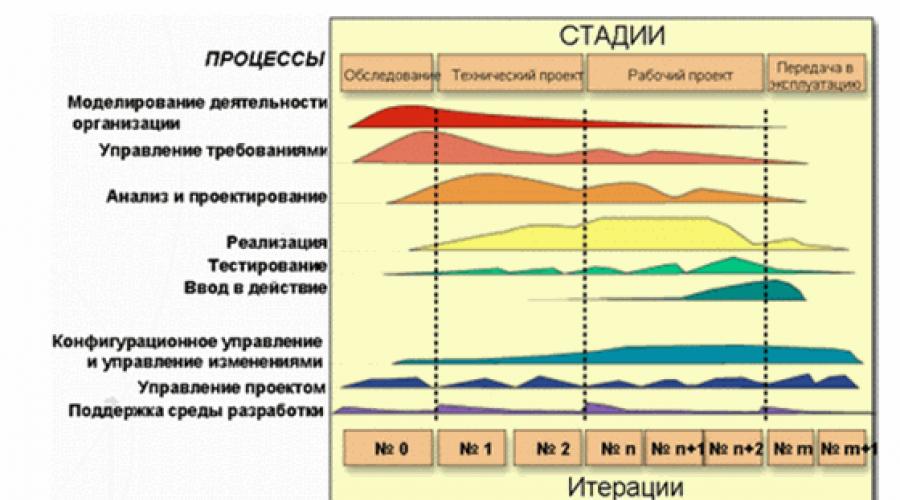
In our time, it is used by iterative processes of software development, in particular, technology RUP - Rational Unified Process(Fig. 1). When using this approach, testing ceases to be the "on the sewn" process, which runs after the programmers wrote all the necessary code. Working on tests begins with the very initial stage of identifying the requirements for the future product and closely integrates with the current tasks. And it makes new requirements for testers. Their role is not just reduced to identifying errors as fully as possible and as early as possible. They should participate in the overall process of identifying and eliminating the most significant risks of the project. For this purpose, the purpose of testing and methods for its achievement is determined for each iteration. And at the end of each iteration is determined how much this goal is achieved if additional tests are needed, and whether it is not necessary to change the principles and test tools. In turn, each detected defect must pass through its own life cycle.
Fig. 1. Product Life Cycle on RUP
Testing is usually carried out by cycles, each of which has a specific list of tasks and purposes. The test cycle may coincide with iteration or correspond to its specific part. Typically, the test cycle is carried out for a specific system assembly.
The life cycle of the software product consists of a series of relatively short iterations (Fig. 2). Iteration is a complete development cycle that leads to the release of the final product or some of its abbreviated version, which expands from iteration to iteration so that, in the end, becoming a finished system.
Each iteration includes, as a rule, tasks of work planning, analysis, design, implementation, testing and evaluation of the results achieved. However, the ratios of these tasks can change significantly. In accordance with the ratio of various tasks in iterations, they are grouped into phases. In the first phase - the beginning - the main attention is paid to the tasks of analysis. In the iterations of the second phase - development - the focus is on the design and testing of key project decisions. In the third phase - the construction is the most large share of development and testing tasks. And in the last phase - transmission - are resolved to the highest tasks of testing and transferring the system to the customer.

Fig. 2. Iterations of the life cycle of the software product
Each phase has its own specific goals in the product life cycle and is considered to be made when these goals are achieved. All iterations, except may be, the iterations of the phase start are completed by creating the functioning version of the system being developed.
Test categories
Tests differ significantly in tasks that are solved with their help, and according to the technique used.
| Test categories | Description Categories | Types of testing |
|---|---|---|
| Current testing | A set of tests performed to determine the performance of the added new features of the system. |
|
| Regression testing | The purpose of regression testing is to verify that the addition to the system has not reduced its capabilities, i.e. Testing is carried out according to the requirements that have already been completed before adding new features. |
|
Subcategory Testing
| Subcategory Testing | Description of the type of testing | Subspecies testing |
|---|---|---|
| Stress Testing | It is used to test everyone without exception of the application functions. In this case, the function testing sequence does not matter. |
|
| Testing business cycles | It is used to test the application functions in the sequence of their call by the user. For example, the imitation of all accountant actions for the 1st quarter. |
|
| Stress testing |
Used for testing Application performance. The purpose of this test is to determine the framework of the stable operation of the application. With this testing, all available functions are called. |
|
Types of testing
Unit testing (Modular Testing) - This species implies testing of individual application modules. To obtain the maximum result, testing is carried out simultaneously with the development of modules.
Functional testing - The purpose of this test is to ensure the proper functioning of the test object. It is tested correctly navigating an object, as well as input, processing and output of data.
Testing database - Check the performance of the database with the normal operation of the application, at the moments of overload and multiplayer mode.
Unit testing
For OOP, the usual organization of modular testing is to test the methods of each class, then the class of each package I.T.D. Gradually, we turn to testing the entire project, and previous tests are the type of regression.
In the output duties, the test data includes test procedures, input data, code executing test, output. The following is a type of output documentation.
Functional testing
Functional testing of the test object is planned and is carried out on the basis of testing requirements specified in the definition stage. The requirements are the business rules, USE-Case charts, business functions, as well as if there are activity charts. The purpose of the functional tests is to check the compliance of the developed graphic components established requirements.
This type of testing cannot be fully automated. Consequently, it is divided into:
- Automated Testing (will be used in the case where you can check output information).
Purpose: Test input, processing and output of data;
- Manual testing (in other cases).
Purpose: Tests the correctness of the execution of user requirements.
It is necessary to execute (play) each of the USE-CASE, using both faithful values \u200b\u200band obviously erroneous, to confirm the correct functioning, according to the following criteria:
- the product responds adequately to all entered data (the expected results are displayed in response to the correctly entered data);
- the product adequately responds to incorrectly entered data (appropriate error messages appear).
Testing database
The purpose of this testing is to make sure that the methods of accessing databases are reliable, in their proper execution, without disrupting the integrity of the data.
You must consistently use the maximum possible number of appeals to the database. A approach is used, in which the test is compiled in such a way as to "load" the base with a sequence, both faithful values \u200b\u200band obviously erroneous. The database response on data entry is determined, the time intervals of their processing are estimated.
Chapter 3. Statistical Processing Test Results
Statistical processing of test results allows on the one hand, objectively define the results of the subjects, on the other - to evaluate the quality of the test itself, test tasks, in particular to evaluate its reliability. The problem of reliability is paid a lot of attention in the classical theory of tests. This theory has not lost its relevance and now. Despite the appearance, more modern theories, the classical theory continues to maintain its position.
3.1. The main provisions of the classical theory of tests
3.2. Matrix test results
3.3. Graphic Presentation of Test Points
3.4. Central tendency measures
3.5. NORMAL DISTRIBUTION
3.6. Dispersion test points test
3.7. Correlation Matrix
3.8. Test reliability
3.9. Test validity
LITERATURE
The main provisions of the classical theory of tests
The creator of the classical theory of tests (Classical Theory of Mental Tests) is a well-known British psychologist, the author of factor analysis, Challes Edward Spearman (1863-1945) 1. He was born on September 10, 1863, and a quarter of his life was served in the British army. For this reason, he received the degree of doctor of philosophy only at the age of 41 2. The dissertation study of Partspirman was performed in the Leipzig Laboratory of Experimental Psychology under the guidance of Wilhelm Wundt (Wilhelm Wundt). In that period, Francis Galton (Francis Galton) was a strong influence on Ch.Pirman (Francis Galton) for testing human intelligence. Pupils Partspirman were R.Cattell and D.Wechsler. Among his followers, A.anastasi, J. P. Guilford, P.Vernon, C.Burt, A.Jensen can be called.
A great contribution to the development of the classical theory of tests made Louis Guttman, 1916-1987) 3.
Comprehensively and full of classical theory of tests for the first time is set forth in the fundamental work of Harold Gullixen (Gulliksen H., 1950) 4. Since then, the theory has somewhat modified, in particular the mathematical apparatus was improved. The classical test theory in modern presentation is given in the book Crocker L., Aligna J. (1986) 5. From domestic researchers, for the first time, the description of this theory was given V.Avanesis (1989) 6. In the work of the Chelyowkova M.B. (2002) 7 provides information on the statistical substantiation of the quality of the test.
Classical test theory is based on the following five main positions.
1. The empirically obtained measurement result (X) is the sum of the true measurement result (T) and measurement errors (E) 8:
X \u003d T + E (3.1.1)
The values \u200b\u200bT and E are usually unknown.
2. The true measurement result can be expressed as a mathematical expectation E (x):
3. The correlation of true and erroneous components according to a set of subjects is zero, that is, ρ te \u003d 0.
4. The erroneous components of two any tests do not correlate:
5. The erroneous components of one test do not correlate with the true components of any other test:
In addition, the basis of the classical theory of tests is two definitions - parallel and equivalent tests.
Parallel tests must comply with the requirements (1-5), the true components of one test (T 1) must be equal to the true components of another test (T 2) in each sample of the tests that respond to both tests. It is assumed that T 1 \u003d T 2 and, in addition, are equal to the dispersion S 1 2 \u003d S 2 2.
Equivalent tests must comply with the entire requirement of parallel tests with the exception of one: the true components of one test do not have to be equal to the true components of another parallel test, but they should differ on the same constant. from.
The equivalence condition of two tests is recorded in the following form:
where C 12 is the constant of the differences in the results of the first and second tests.
Based on the above provisions, the theory of test reliability is 9.10.
that is, the dispersion of the obtained test points is equal to the sum of the dispersions of the true and erroneous components.
I rewrite this expression as follows:
 (3.1.3)
(3.1.3)
The right side of this equality is the reliability of the test ( r.). Thus, the reliability of the test can be written in the form:
Based on this formula, there were subsequent expressions for finding the test reliability factor. The reliability of the test is its crucial characteristic. If reliability is unknown, the test results cannot be interpreted. The reliability of the test characterizes its accuracy as a measuring instrument. High reliability means high repeatability of test results in the same conditions.
In the classic test theory, the most important problem is to determine the true test point of the subject (T). The empirical test point (X) depends on many conditions - the level of difficulty of tasks, the level of preparedness of the subjects, the number of tasks, the conditions for conducting testing, etc. In the group of strong, well-trained subjects, test results will be usually better. than in the group weakly prepared subjects. In this regard, the issue of the magnitude of the difficulty of tasks on the general population of the subjects remains an open. The problem lies in the fact that real empirical data is obtained on not at all random samples of the subjects. As a rule, these are educational groups, which are many students of quite strongly interacting among themselves in the process of teachings and students in conditions that are often not repeated for other groups.
Find s E. From equation (3.1.4)
![]()
Here explicitly shows the dependence of the measurement accuracy from the standard deviation value. s X. and from the reliability of the test r..
Application areas, objectives and tasks of testing are varied, so testing is estimated and explained in different ways. Sometimes the testers themselves it is difficult to explain what testing on "AS IS". There is a confusion.
To unravel this confusion, Alexey Barancers (Practice, coach and consultant in software testing; a leaving from the Institute of System Programming of the Russian Academy of Sciences) predicts its training on testing the introductory video about the main tests of testing.
It seems to me that in this report, the lecturer could most adequately and weigly explain "what is testing" from the point of view of the scientist and programmer. It is strange that this text has not yet appeared on Habré.
I cite here a compressed retelling of this report. At the end of the text there are links on the full version, as well as the mentioned video.
The main positions of testing
Dear Colleagues,First, let's try to understand what testing is not.
Testing Not Development,
Even if the testers are able to program, including tests (automation testing \u003d Programming), can develop some auxiliary programs (for themselves).
However, testing is not software development activities.
Testing is not analysis,
And not to collect and analyze the requirements.
Although, in the testing process, sometimes you have to clarify the requirements, and sometimes you have to analyze them. But this activity is not the main, rather, it is necessary to do just if necessary.
Testing Not management,
Despite the fact that in many organizations there is such a role as the "test manager". Of course, testers need to be managed. But in itself testing is not controlled.
Testing is not technical involvement,
However, testers have to document their tests and their work.
Testing cannot be considered any of these activities simply because in the process of developing (or analyzing the requirements, or writing documentation for its tests) the testers are doing all this work for yourself, not for someone else.
Activities meaning only when it is in demand, that is, test holders should produce something "for export". What do they do "for export"?
Defects, defect descriptions, or testing reports? Partially it is true.
But this is not the whole truth.
Main activity Testizers
It is that they provide project participants to develop software negative feedback on the quality of the software product."Negative feedback" does not carry some negative tint, and does not mean that test holders do something bad, or that they do something bad. It is just a technical term that means a fairly simple thing.
But this thing is very significant, and probably the only most significant component of the activities of testers.
There is a science - "system theory". It defines such a concept as "Feedback".
"Feedback" is some data that is released back to the input, or some part of the data, which from exit fall back to the input. This feedback can be positive and negative.
And the one, and the other varieties of feedback are equally important.
In the development of software systems with positive feedback, of course, is some information that we receive from end users. These are requests for some new functionality, this increase in sales (if we produce a quality product).
Negative feedback can also come from end users in the form of some negative reviews. Either she can come from testers.
The earlier negative feedback is provided, the less energy is necessary for the modification of this signal. That is why you need to begin to begin as soon as possible, in the earliest stages of the project, and provide this feedback and at the design stage, and also, maybe earlier, at the stage of collecting and analyzing the requirements.
By the way, hence the understanding that testers are not responsible for quality. They help those who are responsible for him.
Synonyms of term "Testing"
From the point of view of the fact that testing is the provision of negative feedback, the world-famous QA abbreviation (English. Quality Assurance - quality assurance) synonym for the term "testing" is not exactly definitely.It is impossible to consider quality assurance simple provision of negative feedback, because the provision is some positive measures. It is understood that in this case we are providing quality, in a timely manner we take some measures so that the quality of development of software has increased.
But "quality control" - Quality Control, can be considered in a broad sense by synonym for the term "testing", because quality control is this and there is a provision of feedback in a wide variety of its varieties, at various stages of the program project.

Sometimes testing is meant as some separate form of quality control.
The confusion comes from the history of testing. At different times, the term "testing" was meant to various actions that can be divided into 2 large classes: external and internal.
External definitions
Definitions that at different times were given Myers, Beyser, Kaner, describe testing just from the point of view of its external significance. That is, from their point of view, testing is an activity that is intended for something, and does not consist of something. All three of these definitions can be generalized as a negative feedback.Internal definitions
These are the definitions that are given in the standard of terminology used in software engineering, for example, in the de facto standard called SWEBOK.Such definitions are constructively explained, which is testing activities, but do not give any idea that it is necessary to test for which all the results of the verification of compliance between the actual behavior of the program and its expected behavior will be used.
testing is
- check the compliance of the program requirements
- carried out by observing its work
- in special, artificially created situations chosen in a certain way.

Total testing scheme approximately as follows:
- The input tester receives a program and / or requirements.
- He does something with them, watches the work of the program in certain, sophisticated situations created by him.
- At the output, it receives information about the correspondences and inconsistencies.
- Next, this information is used to improve the already existing program. Either in order to change the requirements for another program being developed.
What is a test
- This is a special, artificially created situation chosen in a certain way,
- and a description of what observations of the program need to do
- to verify its compliance with some requirement.
The test developer is engaged in the fact that it is from a huge potentially infinite test of tests choose some limited set.
Well, so we can conclude that the tester does two things in the process of testing.
1. First, he manages the execution of the program and creates these the most artificial situations in which we are going to check the behavior of the program.
2.I, secondly, he is watching the behavior of the program and compares what he sees with what is expected.
If the tester automates the tests, he does not themselves watches the behavior of the program - it delegates this task to a special tool or a special program he himself wrote. It is she who observes, it compares the observed behavior with the expected, and the tester gives only some end result - whether the observed behavior coincides with the expected, or does not coincide.
Any program is a mechanism for processing information. The entry comes into the entry in some one form, the output information in some other form. At the same time, the program inputs and outputs can be a lot, they can be different, that is, a program can have several different interfaces, and these interfaces may have different types:
- User Interface (UI)
- Software Interface (API)
- Network Protocol
- File system
- Condition of the environment
- Events
- custom
- graphic,
- text
- cantilevered,
- and speech.
- somehow creates artificial situations,
- and checks in these situations as a program behaves.
This is testing.
Other classifications of testing types
Most often used to split three levels, it- modular testing
- integration testing
- system Testing.
Under system testing is meant testing at the user interface level.
Sometimes some other terms are also used, such as "component testing", but I prefer to allocate these three, due to the fact that the technological separation of modular and systemic testing does not make much sense. At different levels, the same tools, the same techniques can be used. Separation conditionally.
Practice shows that the tools that are positioned by the manufacturer as modular testing tools can be applied with equal success and at the test level of the entire application as a whole.
And the tools that test the entire application as a whole at the User Interface level sometimes want to look, for example, to the database or cause some separate stored procedure there.
That is, the division into systemic and modular testing is generally purely conditional, if we speak from a technical point of view.
The same tools are used, and this is normal, the same techniques are used, at each level you can talk about testing various types.
Combine:

That is, you can talk about modular testing of functionality.
You can talk about systemic functionality testing.
You can talk about modular testing, for example, efficiency.
You can talk about systemic testing of efficiency.
Or we consider the effectiveness of some separate algorithm, or we consider the effectiveness of the entire system as a whole. That is, the technological separation for modular and systemic testing does not make much sense. Because at different levels, the same tools, the same techniques can be used.
Finally, with integration testing, we check if, as part of a system, the modules interact with each other correctly. That is, we actually perform the same tests as in system testing, only further pay attention to how the modules interact with each other. Perform some additional checks. This is the only difference.
Let's try again try to understand the difference between systemic and modular testing. Since this separation is found quite often, this difference must be.
And this difference is manifested when we do not perform a technological classification, but a classification by targets Testing.
Classification for the purposes is convenient to perform using the "magic square", which was originally invented by Brian Marik and then improved Erie Tannen.

In this magic square, all types of testing are located on four quadrants, depending on what the attention is more focused in these tests.
Vertically - the higher the type of testing is, the more attention is paid to some external manifestations of the behavior of the program, the lower it is, the more we pay attention to its internal technological device of the program.
Horizontally - the left our tests are located, the more attention we pay them to programming, the more right they are, the more attention we pay for manual testing and research of the program by a person.
In particular, in this square you can easily enter such terms as acceptance testing, Acceptance testing, modular testing precisely in that understanding in which it is most often used in the literature. This is low-level testing with large, with an overwhelming share of programming. That is, these are all tests are programmed, fully automatically executed and attention is paid primarily to the internal device of the program, it is its technological features.
In the upper right corner, we will have hand tests aimed at the external behavior of the program, in particular, testing ease of use, and in the lower right corner, we most likely have been inspected by different non-functional properties: performance, security, and so on.
So, based on the classification by targets, we turn out to be modular testing in the uppermost quadrant, and all other quadrants are system testing.
Thanks for attention.
basics of test theory
Basic concepts of test theory
Measurement or testing carried out in order to determine the status or abilities of an athlete is called dough .
Not all measurements can be used as tests, but only those that meet the special requirements. These include:
1. Standardization (procedure and testing conditions should be the same in all cases of applying test);
2. Reliability;
3. Informative;
4. The presence of the rating system.
Tests that meet the requirements of reliability and informativeness are called sobota or authentic (Greek. authentic - reliable way).
The test process is called testing ; The numerical value obtained as a result - test results (or the result of the test). For example, running 100 m is a test, the procedure for carrying out the occasion and timing - testing, the time of the race is the result of the test.
Tests based on motor tasks are called motor or motor . The results of them can be either motor achievements (the time of passage of the distance, the number of repetitions passed through the distance, etc.), or physiological and biochemical indicators.
It is sometimes used not one, but several tests that have a single end target (for example, an assessment of the state of an athlete in the competitive period of training). Such a group of tests is called complex or test battery .
The same test applied to the same study should be given in the same conditions the coinciding results (unless they changed the studied themselves). However, with the most strict standardization and accurate equipment, test results are always somewhat vary. For example, the resulting dynamometry that has just shown the result of 215 kg in the dynamometry test, with repeated execution shows only 190 kg.
2. Reliability of tests and ways to determine
Reliability The test is called the degree of coincidence of results when re-testing the same people (or other objects) under the same conditions.
The variation of the results when re-testing is called inside individual, or inside group, or intrasklass.
Four main reasons cause this variation:
1. Changing the state of the studied (fatigue, work, learning, change of motivation, concentration of attention, etc.).
2. uncontrolled changes in external conditions and equipment (temperature, wind, humidity, voltage in the power grid, the presence of unauthorized persons, etc.), i.e. All that combines the term "random measurement error".
3. Changing the state of a person conducting or evaluating test (and, of course, replacing one experimenter or judge to others).
4. Dough's imperfection (there are such tests that are knowingly inconvenient. For example, if the tests perform free throws into a basketball basket, then even a basketball player having a high percentage of hits may accidentally be mistaken at the first throwing).
The main difference in the theory of test reliability on the theory of measurement errors is that in the error theory, the measured value is considered unchanged, and in the theory of reliability tests it is assumed that it changes from measurement to the measurement. For example, if you need to measure the result of an attempt done in lengths in length from a runway, it cannot change significantly and over time. Of course, due to random causes (for example, unequal tension of the roulette), it is impossible to measure this result with an ideal accuracy (say up to 0.0001 mm). However, using a more accurate measuring instrument (for example, a laser meter), you can increase their accuracy to the required level. At the same time, if the task is to determine the preparedness of the jumper at certain stages of the annual training cycle, the most accurate measurement of the results shown by them little will help: after all, they will change from trying to try.
To deal with the idea of \u200b\u200bmethods used to judge the reliability of tests, consider a simplified example. Suppose that you need to compare the results of jumps in length from a place in two athletes on two completed attempts. Suppose that the results of each of the athletes vary within ± 10 cm from the average value and are equal, respectively, 230 ± 10 cm (ie 220 and 240 cm) and 280 ± 10 cm (ie 270 and 290 cm). In this case, the conclusion, of course, will be completely unequivocal: the second athlete exceeds the first (the differences between the average in 50 cm is clearly higher than random oscillations of ± 10 cm). If, with the same intragroup variation (± 10 cm), the difference between the average values \u200b\u200bof the studied (intergroup variation) will be small, then it will be much more difficult to make the output. Suppose that the average values \u200b\u200bwill be about equal to 220 cm (in one attempt - 210, in the other - 230 cm) and 222 cm (212 and 232 cm). At the same time, the first studied in the first attempt jumps at 230 cm, and the second is only at 212 cm; And it seems that the first is essentially stronger than the second. From this example, it can be seen that the main value is not the in itself intra-market variability, but its ratio with interclace differences. The same intraclassic variability gives different reliability with equal differences between classes (in the particular case between the studied, Fig. 14).
Fig. 14. The ratio of inter-and intra-class variation with high (top) and low (lower) reliability:
short vertical strokes - data of individual attempts;
The average results of the three studied.
The theory of test reliability proceeds from the fact that the result of any measurement conducted on person is the sum of two values:
where: - the so-called true result that they want to fix;
An error caused by uncontrollable changes in the state of the test and random measurement errors.
Under the true result, the average value of x with an infinitely large number of observations in the same conditions is (for this, at x they put a sign).
If the errors are random (their sum is zero, and in equal attempts they do not depend on each other), then from mathematical statistics it follows:
those. Registered in the experiment of the results dispersion is equal to the amount of dispersions of the true results and errors.
Reliability coefficient The ratio of the true dispersion to the dispersion is registered in the experiment:

In addition to the reliability coefficient, still use reliability index:
which is considered as a theoretical correlation coefficient of registered test values \u200b\u200bwith true.
The concept of the true result of the test is abstraction (in experience it is impossible). Therefore, you have to use indirect methods. Most preferred for assessing reliability dispersion analysis, followed by the calculation of intracelate correlation coefficients. Dispersion analysis allows you to decompose the variation of the test results into the components due to the influence of individual factors. For example, if you register the results in the studied results in any test, repeating this test in different days, and every day to do several attempts, periodically changing experimenters, then there will be variations:
a) from the subject to the subject;
b) from day to day;
c) from the experimenter to the experimentator;
d) from trying to try.
Dispersion analysis makes it possible to allocate and evaluate these variations.
Thus, it is necessary to estimate the practically reliability of the test, first, to perform a dispersion analysis, secondly, calculate the intralass correlation coefficient (reliability ratio).
With two attempts, the value of the intra-class correlation coefficient practically coincides with the values \u200b\u200bof the usual correlation coefficient between the results of the first and second attempts. Therefore, in such situations, a conventional correlation coefficient can be used to assess reliability (it estimates the reliability of one, not two attempts).
Speaking about the reliability of tests, it is necessary to distinguish their stability (reproducibility), consistency, equivalence.
Under stability Tests understand the reproducibility of the results when it is repeated after a certain time in the same conditions. Repeated testing is usually called retest.
Consistency The test is characterized by the independence of test results from personal qualities of a person conducting or an evaluating test.
When choosing a test from a certain number of same type tests (for example, a sprint run by 30, 60 and 100 m) by parallel forms, the degree of coincidence of the results is estimated. Calculated between the results correlation coefficient call equivalence ratio.
If all tests included in any type of tests are highly equivalent, it is called homogenic. This entire complex measures one of the property of human motility (for example, a complex consisting of jumping from place in length, up and triple; the level of development of high-speed-security qualities is estimated). If there are no equivalent tests in the complex, that is, the tests included in it are measured different properties, then it is called heterogeneous (for example, a complex consisting of becoming dynamometry, jump up acalac, running per 100 m).
Test reliability can be increased to a certain extent by:
a) more strict standardization of testing;
b) increase the number of attempts;
c) increase the number of appraisers (judges, experiments) and improving the coherence of their opinions;
d) increase the number of equivalent tests;
e) the best motivation of the studied.
Example 10.1.
Determine the reliability of the results of a triple jump from the place in the assessment of the speed and power capabilities of sprint athletes, if these samples are as follows:
Decision:
1. Apply test results to the work table: 
2. We substitute the results obtained in the calculation formula of the rank coefficient of correlation:

3. We define the number of degrees of freedom by the formula:
Output: The resulting settlement value is therefore, with confidence in 99% we can say that the triple jump test is reliable.
The first component, the theory of tests, contains a description of statistical diagnostic data processing models. Here are the answers analysis models in test tasks and the calculation model of the total test results. Mellenberg (1980, 1990) called it "psychometry". Classical test theory, modern test theory (or model analysis of answers to test tasks - IRT) and model
task samples make up the three most important types of models of test theory. The subject of psychodiagnostics is the first two models.
Classical test theory. Based on this theory, most intellectual and personal tests have been developed. The central concept of this theory is the concept of "reliability". Under reliability it is understood as the coherence of results during re-evaluation. In reference manuals, this concept is usually very brief, and then a detailed description of the apparatus of mathematical statistics is given. In this, introductory, chapter we will present a compressed description of the main value of the noted concept. In the classic test theory, reliable is the repetition of the results of several measurement procedures (mainly measurements with tests). The concept of reliability involves calculating the measurement error. The results obtained during the testing process can be represented as the sum of the true result and measurement error:
Xi \u003d Ti.+ EJ.
where XI- evaluation of the results obtained, Ti is a true result, and EJ.- Measurement error.
Evaluation of the results obtained is, as a rule, the number of correct answers to the tasks of the test. The true result can be viewed as a true assessment in Platonic sense (Gulliksen, 1950). The concept of expected results is widespread, i.e. Representations of points that can be obtained as a result of a large number of repetitions of measurement procedures (Lord & Novich, 1968). But the implementation of the same assessment procedure with one person is not possible. Therefore, you need to search for other solutions to the problem (Witlman, 1988).
Within the framework of this concept, some assumptions are made relative to the true results and measurement errors. The latter are accepted as an independent factor, which, of course, is a well-founded assumption, since random fluctuations in the results do not give covariants: r it \u003d 0.
It is assumed that the correlation between true scores and measurement errors does not exist: r ee \u003d 0.
The total error is 0, because As a true estimate, the arithmetic meaning is taken:
These assumptions lead us as a result of a certain definition of reliability as a ratio of the true result to a common dispersion or expression: 1 minus the relation, in which the measurement error number, and in the denominator - the overall dispersion:
 , OR
, OR 
From this formula definition of reliability, we obtain that dispersion error S 2 (E)it is equal to the total dispersion among cases (1 - R xx "); thus, the standard measurement error is determined by the formula:
![]()
After theoretical substantiation of reliability and its derivatives, it is necessary to determine the reliability index of a test. There are practical procedures for assessing test reliability, such as using interchangeable forms (parallel tests), splitting tasks into two parts, re-testing and measuring internal consistency. Each directory contains the constancy indices of test results:
r xx '\u003d R (x 1, x 2)
where r xx ' - stability coefficient, and x 1 and x 2 - The results of the two dimensions.
The concept of reliability of interchangeable forms was introduced and developed by Gullixen (1950). This procedure is quite laborious, because it is related to the need to create a parallel series of tasks.
r xx '\u003d R (x 1, x 2)
where r xx ' - equivalence coefficient, and x 1 and x 2 - Two parallel tests.
The following procedure is the splitting of the main test into two parts A and B is more simple to use. Indicators obtained on both parts of the test are correlated. With the help of the Spearman-Brown formula, the reliability of the test as a whole is estimated:
where and B - two parallel parts of the test.
The following method is the definition of internal consistency of test tasks. This method is based on the definition of covariants of individual tasks. SG - dispersion of an arbitrarily selected job, and SGH - covariance of two arbitrarily selected tasks. The most frequently used coefficient to define internal consistency is the "alpha coefficient" of Kronbach. The formula is also used Kr20 and λ-2(Lambda-2).
In the classic concept of reliability, measurement errors arising both in the testing process and in the process of observations are determined. Sources of these errors are different: these may also be personal features, and features of testing conditions, and the test tasks themselves. There are specific methods for calculating errors. We know that our observations may be erroneous, our methodical instruments are imperfect in the same way as the people themselves are imperfect. (How not to remember Shakespeare: "You are unreliable, whose name is a person"). The fact that in the classical measure of measurement error tests is explicable and explained is an important positive point.
The classic test theory has a number of essential features that can be considered as its disadvantages. Some of these characteristics are noted in reference books, but their meaning (from everyday point of view) is emphasized infrequently, as not and the fact that they should be considered shortcomings from the theoretical or methodological point of view.
First. The classical test theory and the concept of reliability are focused on calculating the total test indicators, which are the result of the addition of estimates obtained in separate tasks. So, when working
Second. The reliability factor implies an assessment of the variance of the measured indicators. It follows that the reliability factor will be lower if (with equality of other indicators) sample is more homogeneous. There is no single coefficient of internal coherence of test tasks, this coefficient is always "contextual". Crocker and Aldjina (1986), for example, offer a special formula "Correction for homogeneous sample" intended for the highest and lowest results obtained by testing. For the diagnost, it is important to know the characteristics of the variations in the sample set, otherwise it will not be able to use the coefficients of the internal consistency specified in the manual for this test.
Third. The phenomenon of information on the average arithmetic indicator is a logical consequence of the classical concept of reliability. If the valuation in the test fluctuates (i.e., it is not reliable enough), it is quite possible that when repetition of the procedure, subjects having low indicators will receive higher points, and vice versa, subjects with high indicators are low. This artifact of measurement procedures cannot be mistaken for a true change or manifestation of development processes. But at the same time delimit them is not easy, because You can never eliminate the possibility of change during development. For complete confidence it is necessary "Comparison with the control group.
The fourth characteristic of tests developed in accordance with the principles of the classical theory is the presence of regulatory data. Knowledge of test rules allows the researcher to adequately interpret the results of the test. Outside the norm, test estimates are deprived of meaning. The development of test norms is a fairly expensive enterprise, since the psychologist should receive test results on a representative sample.
2 J. Ter Laak
If we talk about the shortcomings of the classical concept of reliability, then the statement of Siy TSMA is appropriate here (1992, r. 123-125). He notes that the first and most important assumption of the classical theory of tests is that test results are subject to the interval principle. However, no research confirming this assumption is not. In fact, it is "Measurement on an arbitrarily established rule." This feature puts the classical theory of tests in a less favorable position compared to the measurement scales and, of course, compared with modern test theory. Many methods of data analysis (dispersion analysis. Regression analysis, correlation and factor analysis) are based on the existence of the interval scale. However, it does not have a firm justification. Consider the scale of true results as a scale of values \u200b\u200bof psychological characteristics (for example, arithmetic abilities, intelligence, neurotism) can only be presumably.
The second remark concerns the test results of the test - these are not absolute indicators of one or another psychological characteristics of the tested, they must be considered only as the results of the implementation of a test. Two tests may apply for the study of the same psychological characteristics (for example, intelligence, verbal abilities, extroversion), but this does not mean that these two tests are equivalent and possess the same capabilities. Comparison of the indicators of two people who have been tested by different tests, incorrectly. The same applies to the filling of two different tests with one subject. Third note refers to the assumption that the standard measurement error is the same in relation to any level of the measured individual abilities. However, there is no empirical verification of this assumption. So, for example, there is no guarantee that tested with good mathematical abilities when working with a relatively simple arithmetic test will receive high points. In this case, a person with low or medium abilities will be highly appreciated.
Within the framework of the current test theory or theory of responses analysis in the test tasks, a description is described in a large
the number of models of possible responses of respondents. These models differ in their foundation assumptions, as well as the requirements for the data obtained. The Rasha model is often considered as a synonym for the theories of response analysis in test tasks (1RT). In fact, this is just one of the models. The formula represented in it to describe the characteristic task curve G is as follows:

where g.- a separate task of the test; eJR- the function of exponentials (nonlinear dependence); δ (Delta) - the level of dough's difficulty.
Other tasks of the test, for example h,also get their own characteristic curves. Terms of condition Δ H\u003e Δ g (Gmeans that h.- more difficult task. Consequently, for any value of the indicator Θ ("Theta" - the latent properties of the abilities of the test) probability of successful task h.less. This model is called strict because it is obvious that with a low degree of severity, the likelihood of task is close to zero. In this model there is no place for guessing and assumptions. For tasks with options, there is no need to make assumptions about the probability of success. In addition, this model is strict in the sense that all tasks of the test must have the same discriminatory ability (high discriminatory reflection in the steepness of the curve; here it is possible to build the GUT-TMAN scale, according to which at each characteristic curve, the probability of the task is changing from up to 1). Because of this, the conditions are not all tasks can be included in the tests created on the basis of the Rasha model.
There are several options for this model (for example, Birnbaura, 1968, see Lord & Novik). It makes the existence of tasks with different discriminatory
ability.
Dutch explorer Mokken (1971) developed two models for analyzing responses in the tasks of the test, the requirements of which are not so strict as in the model of the Rush, and therefore may be more realistic. As the main condition
viya Mokken puts forward the position that the characteristic curve of the task must follow monotonously, without breaks. All tasks of the test at the same time are aimed at studying the same psychological characteristics, which should be measured in.Any form of this dependence is allowed until it interrupted. Consequently, the shape of the characteristic curve is not determined by any specific function. Such "freedom" allows you to use more test tasks, and the level of estimation is not higher than the usual one.
The methodology of models of responses to the tasks of the test (IRT) differs from the methodology of most experimental and correlation studies. The mathematical model is designed to study behavioral, cognitive, emotional characteristics, as well as development phenomena. These phenomena under consideration are often limited to responses to the tasks, which allowed Mel-Lenberg (1990) to call the theory of IRT "mini-theory about mini-behavior." The results of the study may be presented to a certain extent as curves of consistency, especially in cases where theoretical ideas about the studied characteristics are absent. Until now, our disposal has only units of intelligence tests, abilities and personal tests created on the basis of numerous IRT theory models. The variants of the Rasha model are more often used in the development of achievement tests (Verhelst, 1993), and the model of the mockene is more suitable for development phenomena (see also ch. 6).
The answer is tested on the task of the test is the main unit of IRT models. The type of response is determined by the degree of severity in humans studied characteristics. Such a characteristic may be, for example, arithmetic or spatial abilities. In most cases, this is one or another aspect of intelligence, characteristics of achievements or personal features. It is assumed that between the position of this particular person in a certain range of the characteristic and the likelihood of a successful implementation of one or another task, there is a non-linear dependence. The nonlinearity of this dependence in a certain sense is intuitive. Famous phrases "Any beginning is difficult" (slow
the linear start) and "becoming sacred is not so simple," mean that further improvement after the achievement of a certain level is difficult. The curve slowly approaches, but almost never reaches 100% of the level of success.
Some models rather contradict our intuitive understanding. Take such an example. A person with an arbitrary characteristic index of 1.5 has a 60 percent probability of success when performing a task. This contradicts our intuitive understanding of such a situation, because it can be either successfully cope with the task, or not to cope with it at all. Take this example: 100 times a person is trying to take a height of 1m 50 cm. Success accompanies him 60 times, i.e. It has a 60 percent probability of success.
To assess the degree of severity, the characteristics must at least two tasks. The Rasha model assumes the definition of the severity of the characteristics, regardless of the difficulty of the task. It also contradicts our intuitive understanding: Suppose that a person has a 80 percent probability to jump above 1.30 m. If so, then in accordance with the characteristic task curve, it has a 60 percent probability to jump above 1.50 m and 40 percent The probability jump above is 1.70 m. Consequently, regardless of the value of an independent variable (height), you can estimate the ability of a person to jump in height.
There are about 50 models IRT (Goldstein & Wood, 1989). There are many nonlinear functions describing (explaining) the likelihood of success in performing a task or a group of tasks. The requirements and limitations of these models are different, and these differences can be detected when comparing the model of the rush and the scale of the moccaen. The requirements of these models include:
1) the need to determine the studied characteristics and assessment of the person's position in the range of this feature;
2) assessment of the setting of tasks;
3) check specific models. In psychometry, many procedures have been developed to verify the model.
In some reference manuals, the IRT theory is considered as a form of analysis of test tasks (see, for example,
Croker & Algina, J 986). It is possible, however, to defend the point of view that the theory of IRT is a "mini-behavior mini-theory." Supporters of IRT theory notice that if imperfect concepts (models) of the mid-level, then what can be said about more complex constructs in psychology?
Classical and modern test theory. People cannot not compare things that look almost the same. (Perhaps everyday equivalent of psychometry and consists mainly in comparing people for meaningful characteristics and choices between them). Each of the presented theories - and the theory of measuring evaluation errors, and the mathematical model of responses to the tasks of the test - has its own supporters (Goldstein & Wood, 1986).
IRT models do not cause reproaches in the fact that it is "evaluation according to the rules", unlike the classical theory of tests. The IRT model is focused on the analysis of the evaluated characteristics. Characteristics of the individual and characteristics of tasks are estimated by the scales (ordinal or interval). Moreover, it is possible to compare the performance of different tests aimed at learning similar characteristics. Finally, the reliability of unequal for each value on the scale, and the average indicators are usually more reliable than the indicators located at the beginning and at the end of the scale. Thus, IRT models in theoretical relations are preemptable. There is also differences in the practical use of modern theory of tests and classical theory (Sijstma, 1992, p. 127-130). The modern theory of tests is more complicated compared to classical, so it is less commonly used by non-specialists. Moreover, IRT places special requirements for tasks. This means that tasks must be excluded from the test if they do not meet the requirements of the model. This rule further applies to those assignments that were part of widely used tests built on the principles of classical theory. The test becomes shorter, and therefore reliability is reduced.
IRT offers mathematical models to study real phenomena. Models should help us understand the key aspects of these phenomena. However, the main theoretical question lies here. Models can be considered
watikak approach to the study of the complex reality in which we live. But the model and reality is not the same thing. According to a pessimistic look, it is possible to simulate only a single (and moreant not the most interesting) types of behavior. You can also meet the statement that the reality is not subject to modeling at all, because It obeys not one causal law. At best, it is possible to simulate individual (ideal) behavioral phenomena. There is another, more optimistic, look at the possibility of modeling. The above position blocks the possibility of deep comprehension of the nature of the phenomena of human behavior. The use of a particular model raises some of the most fundamental questions. In our opinion, it is not doubtful that IRT is the concept of theoretically and technically superior to the classical theory of tests.
The practical purpose of tests, for whatever theoretical basis, they are not created, is to identify significant criteria and the establishment of the characteristics of certain psychological constructs on them. Does the IRT model have advantages and in this regard? It is possible that tests created on the basis of this model do not give a more accurate forecast compared to tests created on the basis of classical theory, and it is possible that their contribution to the development of psychological constructs is not more significant. The diagnoses prefer such criteria that directly relate to a separate person, the institute or community. A model, more perfect in scientific relation, "IPSO FACTO" * does not define a more suitable criterion and is a certain extent limited in explaining scientific constructs. Obviously, the development of tests based on classical theory will continue, but at the same time new IRT models will be created, extending to the study of a larger number of psychological phenomena.
In the classic test theory, the concepts of "reliability" and "validity" are distinguished. Teszeshai results must be reliable, i.e. The results of the initial and re-testing should be coordinated. Moreover,
* iPSO FACTO.(varnish) - by itself (approx. Trans.).
the results must be free (as far as possible) from evaluation errors. The presence of validity is one of the requirements for the results obtained. In this case, reliability is considered as necessary, but not yet a sufficient condition for the validity of the test.
The concept of validity assumes that the results obtained belong to anything important in practical or theoretical relations. Conclusions made on the basis of test estimates should be valid. Most often talk about two types of validity: prognostic (criteria) and structural. There are also other types of validity (see ch. 3). In addition, validity can be defined in the case of quasi-experiment (Campbell, 1976, Cook & Shadish, 1994). However, the main type of validity is still the prognostic validity, under which it is understood as the ability to predict something significant about behavior in the future, as well as the possibility of a deeper understanding of one or another psychological properties or quality.
The presented validity types are discussed in each directory and are accompanied by a description of the test validity analysis methods. Factor analysis is more suitable for determining the structural validation, and the linear regression equations are used to analyze prognostic validity. Those or other characteristics (performance, therapy efficiency) can be predicted on the basis of one or more indicators, half-scientists when working with intellectual or personal tests. Such data processing techniques, as a correlation, regression, dispersion analysis, analysis of partial correlations and dispersions, serve to determine the prognostic validity of the test.
Also describes meaningful validity. It is assumed that all tasks and tasks of the test should belong to the specific area (mental properties, behavior, etc.). The concept of substantive validity characterizes the correspondence of each test task of the measured area. Substantive validity is sometimes considered as part of reliability or "generalized" (Cronbach, Gleser, Nanda & Rajaratnam, 1972). However
the choice of tasks for achievements tests in a particular subject area is also important to pay attention to the rules for the task in the test.
In the classic test theory, reliability and validity are considered relatively independent of each other. But there is another understanding of the ratio of these concepts. Modern test theory is based on the use of models. Parameters are estimated inside a certain model. If the task does not meet the requirements of the model, then within the framework of this model, it is recognized as invalid. The structural validization is part of the model check itself. This validization refers mainly to check the existence of a one-dimensional latent line under study with known scales characteristics. The scatches will undoubtedly be used to determine the corresponding criteria, and their correlation is possible with the indicators of other constructs to collect information about the convergent and divergent validity of the construct.
Psychodiagnosis is similar to the language described as the unity of four components presented at three levels. The first component, the theory of tests, similar to syntax, grammar of the language. Generating (generative) grammar is, on the one hand, a witty model, on the other, the system subordinating the rules. Using these rules, complicated are built on the basis of simple affective proposals. At the same time, however, this model leaves aside a description of how the communication process is organized (which is transmitted and what is perceived), and with what kind of objectives it is carried out. For understanding this requires additional knowledge. The same can be said about the theory of tests: it is necessary in psychodiagnostics, but it is not able to explain that psychodiagnoste does and what is his goal.
1.3.2. Psychological theories and psychological constructs
Psychodiagnostics is always a diagnosis of something specific: personal characteristics, behavior, thinking, emotions. Tests are intended to evaluate individual differences. There are several concepts
individual differences, each of which has its own distinctive features. If it is recognized that psychodiagnostics is not limited to an assessment of individual differences, then other theories are essential for psychodiagnostics. An example is to assess the differences in mental development processes and differences in the social environment. Although the assessment of individual differences is not an indispensable attribute of psychodiagnostics, nevertheless there are certain traditions of research in this area. Psychodiagnostics began with an assessment of intelligence differences. The main task of the tests was "determining the hereditary transmission of genius" (Gallon) or the selection of children for training (BINET, SIMON). Measuring the intellectivity coefficient received theoretical understanding and practical development in the works of Spirmend (United Kingdom) and Terestone (USA). Raymond B.Qottel made this similar to assessing personal characteristics. Psychodiagnostics becomes inextricably linked with theories and ideas about individual differences in achievements (assessment of limitations) and forms of behavior (level of typical functioning). This tradition continues to remain effective today. In teaching benefits on psychodiagnostics, differences in the social environment are much less rated compared with the consideration of the peculiarities of the development processes themselves. For this, there are no reasonable explanations. On the one hand, the diagnosis is not limited to certain theories and concepts. On the other hand, it needs theories, since it is precisely in them a diagnostic content (i.e. "that" is diagnosed). For example, intelligence can also be considered as a general characteristic, and as a base for a variety of independent abilities. If psychodiagnostics tries to "leave" from one or another theory, then the basis of a psychodiagnostic process becomes the ideas of common sense. The studies use various ways to analyze data, and the general logic of research determines the choice of a mathematical model and determines the structure of the psychological concepts used. Such methods of mathematical statistics
kI, as a dispersion analysis, regression analysis, factor analysis, the counting of correlations involve the existence of linear dependencies. In case of incorrect use of these methods, they "bring" the structure to the data obtained and the constructs used.
The ideas about the differences in the social environment and the development of personality almost did not affect psychodiagnostics. In the textbooks (see, for example, Murphy & Davidshofer, 1988), the classical test theory is considered and the relevant methods of statistical processing are discussed, well-known tests are described, the use of psychodiagnostics in practice are described: in the psychology of management, in the selection of personnel, in assessing the psychological characteristics of the person .
Theories of individual differences (as well as ideas about the differences between the social environment and mental development) are similar to the study of semantics of the language. This is the study and entity, and content, and values. Values \u200b\u200bare structured in a certain way (like psychological constructs), for example, in similarity or contrast (analogy, convergence, divergence).
1.3.3. Psychological tests and other methodological means
The third component of the proposed circuit - tests, procedures and methodological means by which information is collected about the characteristics of the personality. Draza and Seitsma (1990, p. 31) give the following definition tests: "The psychological test is considered as a classification according to a certain system or as a measurement procedure that allows you to make a certain judgment about one or more empirically dedicated or theoretically reasonable characteristics of a particular person of human behavior (for Frames of a test situation). At the same time, the reaction of respondents is considered on a certain number of carefully selected incentives, and the responses received are compared with test standards. "
Diagnostics requires tests and techniques for collecting reliable, accurate and validal information about features.
and characteristic features of the person, thinking, emotions and human behavior. In addition to the development of test procedures, this component also includes the following questions: how the tests are created, how to formulate and tasks are selected, as the testing process proceeds, what are the requirements for testing conditions, as the measurement errors are taken into account, test results are counted and interpreted.
In the process of developing tests, rational and empirical strategies differ. The application of a rational strategy begins with the definition of basic concepts (for example, the concept of intelligence, extroversion), and in accordance with these ideas, the tasks of the test are formulated. An example of such a strategy can be the concept of aspect analysis (The Facet Theory) Guttman (1957, 1968, 1978). First, various aspects of the main construct are determined, then tasks and tasks are selected in such a way that each of these aspects is taken into account. The second strategy is that the tasks are selected on an empirical basis. For example, if a researcher tries to create a test of professional interests, which would allow the differentiation of doctors from engineers, then the procedure should be like this. Both groups of respondents must respond to all the tasks of the test, and those items, in responses to which statistically significant differences are detected, are included in the final version of the test. If, for example, there are differences between groups in responses to approval "I love to catch fish", then this statement becomes an element of the test. The main position of this book is that the test is associated with a conceptual or taxonomic theory that defines these characteristics.
The test assignment is usually defined in the instructions for its use. The test must be standardized in order to make it possible to estimate the differences between people, and not between testing conditions. There are, however, deviations from standardization in procedures called "testing of the boundaries of possibilities" (Testing the limits) and "Testing Potential Tests" tests "(Learning Potential Tests). Under these conditions, the respondent is assistance in the process.
testing and then the influence of such a procedure for the result is estimated. Counting points for answers to tasks is objective, i.e. It is carried out in accordance with the standard procedure. The interpretation of the results obtained is also strictly defined and is carried out on the basis of test norms.
The third component of psychodiagnostics is psychological tests, tools, procedures - contains certain tasks, which are the lowest units of psychodiagnostics and in this sense of the task are similar to the languages. The number of possible combinations of the phone game is limited. Only certain phonderatic structures can form words and proposals to ensure information to the listener. Also andtest tasks: Only in a certain combination with each other, they can become an effective means of assessing the corresponding construct.