Mathematical foundations of the theory of test design. Characteristics of control testing in physical education
Description of the presentation for individual slides:
1 slide
Slide Description:
2 slide
Slide Description:
It is customary to call physical qualities innate (genetically inherited) morphological and functional qualities, due to which physical (materially expressed) human activity is possible, which receives its full manifestation in purposeful motor activity. The main physical qualities include strength, speed, endurance, flexibility, agility.
3 slide
Slide Description:
Motor abilities are individual characteristics that determine the level of a person's motor abilities (V. I. Lyakh, 1996). The basis of a person's motor abilities is made up of physical qualities, and the form of manifestation is motor skills and abilities. Motor abilities include power, high-speed, speed-power, motor-coordination abilities, general and specific endurance
4 slide
Slide Description:
Scheme of systematization of physical (motor) abilities Physical (motor) abilities Conditioning (energetic) Power Combinations of conditioning abilities Endurance Speed Flexibility Coordination (informational) CS related to separate groups of motor actions, special CS Specific CS Combinations of coordinating abilities Combinations of conditioning and coordination abilities
5 slide
Slide Description:
GET ACCURATE INFORMATION ABOUT THE LEVEL OF MOTOR ABILITY DEVELOPMENT / high, medium, low / IT IS POSSIBLE WITH THE HELP OF TESTS / or control exercises /.
6 slide
Slide Description:
With the help of control tests (tests), it is possible to reveal the absolute (explicit) and relative (hidden, latent) indicators of these abilities. Absolute indices characterize the level of development of certain motor abilities without taking into account their influence on each other. Relative indicators allow judging the manifestation of motor abilities, taking into account this influence.
7 slide
Slide Description:
The aforementioned physical abilities can be presented as existing potentially, that is, before the start of performing any motor activity or activities (they can be called potential abilities) and as manifesting themselves in reality at the beginning (including when performing motor tests) and in the process of performing this activities (actual physical abilities).
8 slide
Slide Description:
With a certain degree of convention, we can talk about ELEMENTARY and physical abilities COMPLEX physical abilities
9 slide
Slide Description:
RESEARCH RESULTS ALLOW TO DISTINCT THE FOLLOWING PHYSICAL ABILITIES SPECIAL SPECIFIC GENERAL COP
10 slide
Slide Description:
Special physical abilities refer to homogeneous groups of integral motor actions or activities: running, acrobatic and gymnastic exercises on apparatus, throwing motor actions, sports games (basketball, volleyball).
11 slide
Slide Description:
Specific manifestations of physical abilities can be spoken of as the components that make up their internal structure.
12 slide
Slide Description:
Thus, the main components of a person's coordination abilities are: the ability to orientate, balance, respond, differentiate the parameters of movements; ability to rhythm, reorganization of motor actions, vestibular stability, voluntary muscle relaxation. These abilities are specific.
13 slide
Slide Description:
The main components of the structure of speed abilities are considered the speed of response, the speed of a single movement, the frequency of movements and the speed manifested in integral motor actions.
14 slide
Slide Description:
The manifestations of strength abilities include: static (isometric) force, dynamic (isotonic) force - explosive, shock-absorbing force.
15 slide
Slide Description:
The structure of endurance is very complex: aerobic, requiring oxygen sources of energy breakdown for its manifestation; anaerobic (glycolytic, creatine phosphate energy sources - without the participation of oxygen); endurance of various muscle groups in static positions - static endurance; endurance in dynamic exercises performed at a speed of 20-90% of the maximum.
16 slide
Slide Description:
The manifestations (forms) of flexibility, where active and passive flexibility are distinguished, are less complex.
17 slide
Slide Description:
General physical abilities should be understood as the potential and realized capabilities of a person, which determine his readiness for successful implementation of motor actions, different in origin and meaning. Special physical abilities are the capabilities of a person that determine his readiness for the successful implementation of motor actions similar in origin and meaning. Therefore, tests provide information, first of all, about the degree of formation of special and specific physical (speed, coordination, strength, endurance, flexibility) abilities.
18 slide
Slide Description:
Special physical abilities are the capabilities of a person that determine his readiness for the successful implementation of motor actions similar in origin and meaning. Therefore, tests provide information, first of all, about the degree of formation of special and specific physical (speed, coordination, strength, endurance, flexibility) abilities.
19 slide
Slide Description:
The tasks of testing are to identify the levels of development of conditioning and coordination abilities, to assess the quality of technical and tactical readiness. Based on the test results, one can: compare the preparedness of both individual students and entire groups living in different regions and countries; to conduct a sports selection for practicing a particular sport, for participating in competitions; to carry out to a large extent objective control over the education (training) of schoolchildren and young athletes; identify the advantages and disadvantages of the tools used, teaching methods and forms of organizing classes; finally, to substantiate the norms (age, individual) of physical fitness of children and adolescents.
20 slide
Slide Description:
Along with the above tasks in the practice of different countries, the tasks of testing are reduced to the following: to teach schoolchildren themselves to determine the level of their physical fitness and to plan the necessary complexes of physical exercises; stimulate students to further improve their physical condition (form); to know not so much the initial level of development of motor ability as its change over a certain time; stimulate students who have achieved high results, but not so much for a high level, as for the planned increase in personal results.
21 slide
Slide Description:
A test is a measurement or test carried out to determine a person's ability or condition.
22 slide
Slide Description:
Only those tests (samples) that meet special requirements can be used as tests: the purpose of the application of any test (or tests) must be determined; a standardized test measurement method and test procedure should be developed; it is necessary to determine the reliability and information content of tests; test results can be reported in the appropriate grading system
23 slide
Slide Description:
Test. Testing. Test result The system of using tests in accordance with the task at hand, organizing conditions, performing tests by subjects, evaluating and analyzing the results is called testing. The numerical value obtained in the course of measurements is the result of testing (test).
24 slide
Slide Description:
The tests used in physical culture are based on motor actions (physical exercises, motor tasks). These tests are called motor or motor tests.
25 slide
Slide Description:
The classification of tests according to their structure is known and according to their predominant indications, single and complex tests are distinguished. A single test is used to measure and evaluate one attribute (coordination or conditioning ability).
26 slide
Slide Description:
27 slide
Slide Description:
With the help of a complex test, several characteristics or components of different or the same ability are assessed. for example, a jump up from a place (with a wave of the arms, without a wave of the arms, to a given height).
28 slide
Slide Description:
29 slide
Slide Description:
TESTS may be conditioning tests to assess strength ability to assess endurance; to assess speed abilities; to assess flexibility, coordination tests to assess coordination abilities related to separate independent groups of motor actions, which measure special coordination abilities; to assess specific coordination abilities - the ability to balance, orientation in space, response, differentiation of movement parameters, rhythm, restructuring of motor actions, coordination (communication), vestibular stability, voluntary muscle relaxation).
30 slide
Slide Description:
Each classification is a kind of guidelines for the selection (or creation) of the type of tests that are more relevant to the testing objectives.
31 slide
Slide Description:
CRITERIA OF MOTOR TESTS KINDERNESS The concept of a "motor test" meets its purpose when the test meets the relevant basic criteria: reliability, stability, equivalence, objectivity, information content (validity), as well as additional criteria: standardization, comparability and economy. Tests that meet the requirements of reliability and information content are called good-quality, or authentic (reliable).
32 slide
Slide Description:
The reliability of the test is understood as the degree of accuracy with which it evaluates a certain motor ability, regardless of the requirements of the one who evaluates it. Reliability is manifested in the degree of coincidence of the results when re-testing the same people in the same conditions; it is the stability or consistency of an individual's test result when the control exercise is repeated. In other words, a child in the group of those examined according to the results of repeated tests (for example, indicators of jumping, running time, throwing distance) steadily retains his rank place. The reliability of the test is determined using correlation-statistical analysis by calculating the reliability factor. In this case, various methods are used, on the basis of which the reliability of the test is judged.
33 slide
Slide Description:
The stability of the test is based on the relationship between the first and second attempts, repeated after a certain time under the same conditions by the same experimenter. The way to retest to determine reliability is called retest. The stability of the test depends on the type of test, the age and sex of the subjects, the time interval between the test and retest. For example, the indices of conditioning tests or morphological traits at short time intervals are more stable than the results of coordination tests; for older children, the results are more stable than for younger children. The retest is usually carried out no later than a week later. At longer intervals (for example, after a month), the stability of even tests such as running 1000 m or long jump from a place becomes noticeably lower.
34 slide
Slide Description:
Test Equivalence Test equivalence is the correlation of the test result with the results of other tests of the same type. For example, when it is necessary to choose which test more adequately reflects speed abilities: running at 30, 50, 60 or 100 meters. The attitude to equivalent (homogeneous) tests depends on many reasons. If it is necessary to increase the reliability of the estimates or conclusions of the study, then it is advisable to use two or more equivalent tests. And if the goal is to create a battery that contains a minimum of tests, then only one of the equivalent tests should be used. Such a battery, as noted, is heterogeneous, since the tests included in it measure different motor abilities. Examples of a heterogeneous battery of tests are 30m running, bar chin-up, forward bend, 1000m running.
35 slide
Slide Description:
The reliability of tests is also determined by comparing the average scores of even and odd attempts included in the test. For example, the average target throws from 1, 3, 5, 7 and 9 attempts are compared with the average target throws from 2, 4, 6, 8 and 10 attempts. This method of assessing reliability is called the doubling method, or splitting. It is used mainly in the assessment of coordination abilities and in the event that the number of attempts forming the test result is not less than six.
36 slide
Slide Description:
Objectivity (consistency) of the test Objectivity (consistency) of the test is understood as the degree of consistency of the results obtained on the same subjects by different experimenters (teachers, judges, experts). To increase the objectivity of testing, it is necessary to comply with the standard test conditions: testing time, place, weather conditions; unified material and hardware support; psychophysiological factors (volume and intensity of the load, motivation); presentation of information (precise verbal formulation of the test problem, explanation and demonstration). This is the so-called objectivity of the test. There is also talk of interpretive objectivity, referring to the degree of independence of interpretation of test results by different experimenters.
37 slide
Slide Description:
In general, as experts note, the reliability of tests can be improved in various ways: by stricter standardization of testing, an increase in the number of attempts, better motivation of subjects, an increase in the number of evaluators (judges, experts), an increase in the consistency of their opinions, and an increase in the number of equivalent tests. There are no fixed values for test reliability indicators. In most cases, they use the following recommendations: 0.95 - 0.99 - excellent reliability; 0.90 - 0.94 - good; 0.80 - 0.89 - acceptable; 0.70 - 0.79 - bad; 0.60 - 0.69 - doubtful for individual assessments, the test is suitable only for characterizing a group of subjects.
38 slide
Slide Description:
Informativeness of a test is the degree of accuracy with which it measures an assessed motor ability or skill. In foreign (and domestic) literature, instead of the word "informativeness", the term "validity" is used (from the English. Validity-validity, validity, legality). In fact, speaking about information content, the researcher answers two questions: what does this particular test (battery of tests) measure and what is the degree of measurement accuracy. There are several types of validity: logical (meaningful), empirical (based on experimental data) and predictive.
39 slide
Slide Description:
Important additional test criteria, as noted, are standardization, comparability, and cost effectiveness. The essence of standardization is that on the basis of test results it is possible to create norms that are of particular importance for practice. Test comparability is the ability to compare results obtained from one or more forms of parallel (homogeneous) tests. In practical terms, the use of comparable motor tests reduces the likelihood that, as a result of regular use of the same test, not only and not so much the level of ability as the degree of skill is assessed. Simultaneously compared test results increase the reliability of the conclusions. The essence of profitability as a criterion for the goodness of the test is that the test does not require a long time, large material costs and the participation of many assistants.
40 slide
Slide Description:
ORGANIZATION OF TESTING THE PREPAREDNESS OF SCHOOL AGE CHILDREN The second important problem of testing motor abilities (recall that the first is the selection of informative tests, is the organization of their application. testing The timing of testing is consistent with the school curriculum, which provides for mandatory two-time physical fitness testing of students.
41 slide
Slide Description:
Knowledge of annual changes in the development of children's motor abilities allows the teacher to make appropriate adjustments to the process of physical culture for the next academic year. However, the teacher must and can conduct more frequent testing, conduct the so-called operational control. This is useful in order to determine, for example, changes in speed, strength and endurance levels influenced by athletics lessons during the first quarter. For this purpose, the teacher can use tests to assess the coordination abilities of children at the beginning and at the end of mastering the material of the program, for example, in sports games, to identify changes in the indicators of the development of these abilities.
42 slide
Slide Description:
It should be borne in mind that the variety of pedagogical tasks to be solved does not allow the teacher to be provided with a unified testing methodology, the same rules for conducting tests and assessing test results. This requires experimenters (teachers) to show independence in solving theoretical, methodological and organizational issues of testing. Testing in the lesson must be linked to its content. In other words, the applied test or tests, subject to the corresponding requirements (as to the research method), should organically be included in the planned physical exercise. If, for example, children need to determine the level of development of speed abilities or endurance, then the necessary tests should be planned in that part of the lesson in which the tasks of developing the corresponding physical abilities will be solved.
43 slide
Slide Description:
The frequency of testing is largely determined by the rate of development of specific physical abilities, age-sex and individual characteristics of their development. For example, to achieve a significant increase in speed, endurance or strength, it takes several months of regular exercise (training). At the same time, in order to obtain a reliable increase in flexibility or individual coordination abilities, only 4-12 workouts are required. Improving physical quality, if you start from scratch, can be achieved in a shorter period of time. And in order to improve the same quality, when it is in a high-level child, it takes more time. In this regard, the teacher should study more deeply the features of the development and improvement of different motor abilities in children at different age and sex periods.
44 slide
Slide Description:
In assessing the general physical fitness of children, a wide variety of test batteries can be used, the choice of which depends on the specific testing tasks and the availability of the necessary conditions. However, due to the fact that the test results obtained can be assessed only by comparison, it is advisable to choose tests that are widely represented in the theory and practice of physical education of children. For example, rely on those recommended in the FC program. To compare the general level of physical fitness of a student or a group of students using a set of tests, they resort to translating test results into points or points. Changing the sum of points during repeated tests allows you to judge the progress of both an individual child and a group of children.
49 slide
Slide Description:
An important aspect of testing is the problem of choosing a test to assess a specific physical ability and general physical fitness.
50 slide
Slide Description:
Practical advice and advice. IMPORTANT: Determine (select) a battery (or a set) of necessary tests with a detailed statement of all the details of their conduct; Set the testing time (better - 2-3 weeks of September - 1st testing, 2-3 weeks of May - 2nd testing); In accordance with the recommendation, accurately determine the age of the children on the day of testing and their gender; Develop uniform protocols for data registration (possibly based on the use of ICT); Determine the circle of assistants and carry out the testing procedure itself; Immediately carry out mathematical processing of the test data - calculating the main statistical parameters (arithmetic mean, arithmetic mean error, standard deviation, coefficient of variation and assessing the reliability of differences between arithmetic mean indicators, for example, parallel classes of the same and different schools of children of the same age and gender ); One of the significant stages of work can be the translation of test results into points or points. With regular testing (2 times a year, over several years), this will allow the teacher to have an idea of the progress of the results.
51 slides
Slide Description:
Moscow "Enlightenment" 2007 The book contains the most common motor tests to assess the conditioning and coordination abilities of students. The manual provides an individual approach of a physical education teacher to each specific student, taking into account his age and physique.
Basic concepts of test theory.
A measurement or test carried out to determine the condition or ability of an athlete is called a test. Any test includes measurement. But not every change is a test. The measurement or test procedure is called testing.
A test based on motor tasks is called a motor test. There are three groups of movement tests:
- 1. Control exercises, performing which the athlete receives the task to show the maximum result.
- 2. Standard functional tests, during which the task, which is the same for everyone, is dosed either by the amount of work performed, or by the amount of physiological shifts.
- 3. Maximum functional tests, during which the athlete must show the maximum result.
High quality testing requires knowledge of measurement theory.
Basic concepts of measurement theory.
Measurement is identifying the correspondence between the phenomenon under study on the one hand, and numbers on the other.
The basics of measurement theory are three concepts: measurement scales, measurement units and measurement accuracy.
Measurement scales.
A measurement scale is the law by which a numerical value is assigned to a measured result as it increases or decreases. Let's consider some of the scales used in sports.
Scale of names (nominal scale).
This is the simplest of all scales. In it, numbers act as labels and serve to detect and distinguish objects under study (for example, the numbering of players on a football team). The numbers that make up the naming scale are allowed to be changed with metas. There are no more-less relationships on this scale, so some people think that the naming scale should not be considered a measurement. When using the naming scale, only some mathematical operations can be performed. For example, its numbers cannot be added or subtracted, but you can count how many times (how often) a particular number occurs.
Order scale.
There are sports where the result of an athlete is determined only by the place occupied in the competition (for example, martial arts). After such competitions, it is clear which of the athletes is stronger and which is weaker. But how much stronger or weaker, one cannot say. If three athletes took the first, second and third places, respectively, then what are the differences in their sportsmanship remains unclear: the second athlete may be almost equal to the first, or may be weaker than him and be almost the same with the third. The places occupied in the scale of order are called ranks, and the scale itself is called rank or non-metric. In such a scale, its constituent numbers are ordered by ranks (i.e., places occupied), but the intervals between them cannot be accurately measured. In contrast to the scale of names, the scale of order allows not only to establish the fact of equality or inequality of the measured objects, but also to determine the nature of inequality in the form of judgments: "more - less", "better - worse", etc.
Using scales of order, you can measure qualitative indicators that do not have a strict quantitative measure. These scales are especially widely used in the humanities: pedagogy, psychology, sociology.
More mathematical operations can be applied to the ranks of the order scale than to the numbers of the denomination scale.
Interval scale.
It is a scale in which numbers are not only ordered by rank, but also separated by specific intervals. A feature that distinguishes it from the scale of relations described below is that the zero point is chosen arbitrarily. Examples include calendar time (the beginning of chronology in different calendars was set for random reasons), articular angle (the angle in the elbow joint with full extension of the forearm can be taken to be either zero or 180 °), temperature, potential energy of the lifted load, potential of the electric field, etc. dr.
The results of measurements on the scale of intervals can be processed by all mathematical methods, except for the calculation of ratios. These intervals scales give an answer to the question: "how much more", but do not allow asserting that one value of the measured value is so many times greater or less than another. For example, if the temperature has increased from 10 to 20 C, then it cannot be said that it has become twice as warm.
Relationship scale.
This scale differs from the interval scale only in that it strictly defines the position of the zero point. Due to this, the scale of ratios does not impose any restrictions on the mathematical apparatus used to process the results of observations.
In sports, the relationship scale measures distance, strength, speed, and dozens of other variables. The scale of relations also measures those values that are formed as the difference between numbers counted on the scale of intervals. So, calendar time is counted on a scale of intervals, and time intervals - on a scale of relations. When using the scale of ratios (and only in this case!), The measurement of any quantity is reduced to the experimental determination of the ratio of this quantity to another similar quantity, taken as a unit. By measuring the length of the jump, we find out how many times this length is greater than the length of another body, taken as a unit of length (meter ruler in a particular case); weighing the barbell, we determine the ratio of its mass to the mass of another body - a unit weight "kilogram", etc. If we restrict ourselves only to the use of scales of relations, then we can give another (narrower, particular) definition of measurement: to measure any quantity means to find empirically its relation to the corresponding unit of measurement.
Units of measurement.
In order for the results of different measurements to be compared with each other, they must be expressed in the same units. In 1960, at the International General Conference on Weights and Measures, the International System of Units was adopted, which was abbreviated as SI (from the initial letters of the words System International). At present, the preferred application of this system has been established in all fields of science and technology, in the national economy, as well as in teaching.
SI currently includes seven independent basic units (see table 2.1.)
Table 1.1.
Units of other physical quantities are derived from these basic units as derivatives. Derived units are determined on the basis of formulas linking physical quantities. For example, the unit of length (meter) and the unit of time (second) are the base units, and the unit of speed (meter per second) is the derivative.
In addition to the main ones, two additional units are highlighted in SI: radian - a unit of a flat angle and steradian - a unit of a solid angle (angle in space).
Accuracy of measurements.
No measurement can be made with absolute precision. The measurement result inevitably contains an error, the magnitude of which is smaller, the more accurate the measurement method and the measuring device. For example, using a regular ruler with millimeter divisions, you cannot measure length with an accuracy of 0.01 mm.
Basic and additional error.
Basic error is the error of a measurement method or measuring instrument that occurs under normal conditions of use.
Additional error is the error of the measuring device caused by the deviation of its operating conditions from normal. It is clear that devices designed to operate at room temperature will give inaccurate readings if used in the summer at the stadium under the scorching sun or in the winter in the cold. Measurement errors can occur when the voltage of the mains or battery power supply is below normal or not constant in value.
Absolute and relative errors.
The value E = A - Ao, equal to the difference between the reading of the measuring device (A) and the true value of the measured quantity (Ao), is called the absolute measurement error. It is measured in the same units as the measured value itself.
In practice, it is often convenient to use not an absolute, but a relative error. The relative measurement error is of two types - real and reduced. The actual relative error is the ratio of the absolute error to the true value of the measured quantity:
A D = --------- * 100%
The reduced relative error is the ratio of the absolute error to the maximum possible value of the measured quantity:
Ap = ---------- * 100%
Systematic and random errors.
Systematic is an error, the value of which does not change from measurement to measurement. Due to this peculiarity, the systematic error can often be predicted in advance or, in extreme cases, detected and eliminated at the end of the measurement process.
The way to eliminate the systematic error depends primarily on its nature. Systematic measurement errors can be divided into three groups:
errors of known origin and known value;
errors of known origin, but of unknown magnitude;
errors of unknown origin and unknown value. The most harmless are errors of the first group. They are easily eliminated
by introducing appropriate corrections to the measurement result.
The second group includes, first of all, errors associated with the imperfection of the measurement method and measuring equipment. For example, the error in measuring physical performance using a mask for inhaling exhaled air: the mask makes breathing difficult, and the athlete naturally demonstrates physical performance that is underestimated in comparison with the true one measured without the mask. The magnitude of this error cannot be predicted in advance: it depends on the individual abilities of the athlete and his state of health at the time of the study.
Another example of a systematic error of this group is the error associated with the imperfection of the equipment, when the measuring device deliberately overestimates or underestimates the true value of the measured value, but the magnitude of the error is unknown.
Errors of the third group are the most dangerous, their appearance is associated both with the imperfection of the measurement method and with the characteristics of the object of measurement - the athlete.
Random errors arise under the influence of various factors that cannot be predicted in advance or accurately taken into account. In principle, random errors are not removable. However, using the methods of mathematical statistics, it is possible to estimate the magnitude of the random error and take it into account when interpreting the measurement results. Measurement results cannot be considered reliable without statistical processing.
What is testing
In accordance with IEEE Std 829-1983 Testing is a software analysis process aimed at identifying differences between its actually existing and required properties (defect) and at evaluating software properties.
According to GOST R ISO IEC 12207-99, in the software life cycle, among others, auxiliary processes of verification, certification, joint analysis and audit are identified. The verification process is the process of determining that software products are operating in full compliance with the requirements or conditions implemented in prior work. This process can include analysis, verification and testing (testing). The attestation process is the process of determining the completeness of compliance of the established requirements, the created system or software product with their functional purpose. The collaborative review process is the process of assessing the states and, if necessary, the results of the work (products) on the project. The audit process is the process of determining compliance with the requirements, plans and terms of the contract. These processes add up to what is commonly referred to as testing.
Testing relies on test procedures with specific inputs, initial conditions, and expected outcomes designed for a specific purpose, such as testing a single program or verifying compliance with a specific requirement. Test procedures can test various aspects of a program's performance, from the correct operation of a single function to the adequate fulfillment of business requirements.
When executing a project, it is necessary to consider in accordance with which standards and requirements the product will be tested. What tools will (if any) be used to find and document found defects. If you remember about testing from the very beginning of the project, testing the product under development will not bring any unpleasant surprises. This means that the quality of the product is likely to be quite high.
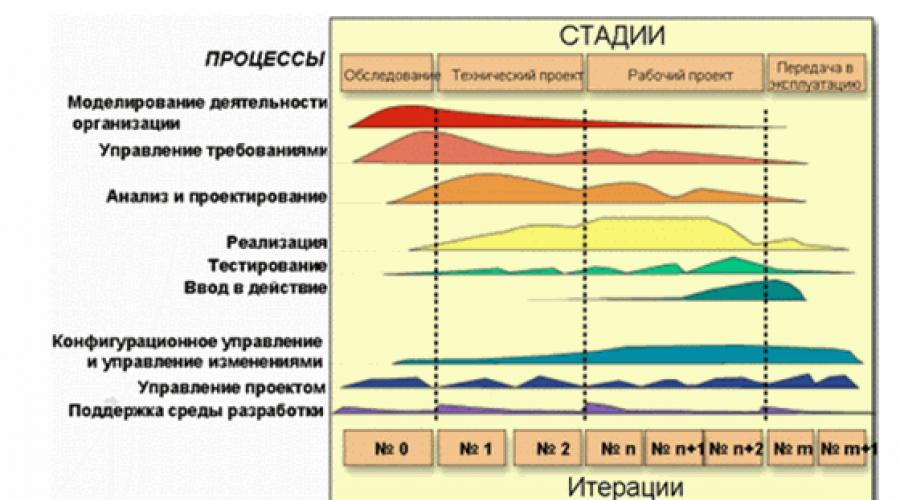
Product life cycle and testing
Increasingly, in our time, iterative software development processes are used, in particular, technology RUP - Rational Unified Process(Fig. 1). When using this approach, testing ceases to be an out-of-the-box process that starts after the programmers have written all the necessary code. Work on tests begins from the very initial stage of identifying requirements for a future product and is tightly integrated with current tasks. And this puts new demands on testers. Their role is not limited to simply identifying errors as fully and as early as possible. They should participate in the overall process of identifying and eliminating the most significant project risks. To do this, for each iteration, a test goal and methods for achieving it are determined. And at the end of each iteration, it is determined to what extent this goal has been achieved, whether additional tests are needed, and whether the principles and tools for conducting tests need to be changed. In turn, each detected defect must go through its own life cycle.
Rice. 1. Product life cycle according to RUP
Testing is usually done in cycles, each with a specific list of tasks and goals. The test cycle can coincide with an iteration or correspond to a specific part of it. Typically, the testing cycle is conducted for a specific build of the system.
The life cycle of a software product consists of a series of relatively short iterations (Fig. 2). Iteration is a complete development cycle leading to the release of a final product or some reduced version of it, which expands from iteration to iteration to eventually become a complete system.
Each iteration includes, as a rule, tasks of work planning, analysis, design, implementation, testing and evaluation of the results achieved. However, the relationship between these tasks can vary significantly. In accordance with the ratio of the various tasks in the iteration, they are grouped into phases. The first phase - Inception - focuses on the analysis tasks. The iterations of the second phase - Development - focus on the design and testing of key design solutions. The third phase - Build - has the largest share of development and testing tasks. And in the last phase - Transfer - the tasks of testing and transferring the system to the Customer are solved to the greatest extent.

Rice. 2. Iterations of the software product life cycle
Each phase has its own specific goals in the product life cycle and is considered complete when these goals are achieved. All iterations, except, perhaps, iterations of the Start phase, are completed with the creation of a functioning version of the system under development.
Testing Categories
Tests differ significantly in the tasks that are solved with their help, and in the technique used.
| Testing Categories | Category description | Testing types |
|---|---|---|
| Current testing | A set of tests performed to determine the health of new system features added. |
|
| Regression testing | The purpose of regression testing is to verify that additions to the system have not diminished its capabilities, i.e. testing is carried out according to the requirements that were already met before adding new features. |
|
Testing subcategories
| Testing subcategories | Description of the type of testing | Testing subtypes |
|---|---|---|
| Stress Testing | It is used to test all functions of the application without exception. In this case, the sequence of testing functions does not matter. |
|
| Business Cycle Testing | It is used to test application functions in the sequence they are called by the user. For example, imitation of all actions of an accountant for 1 quarter. |
|
| Stress testing |
Used for testing Application performance. The purpose of this testing is to determine the framework for the stable operation of the application. During this testing, all available functions are called. |
|
Testing types
Unit testing (unit testing) - this type involves testing individual application modules. To obtain the maximum result, testing is carried out simultaneously with the development of modules.
Functional testing - The purpose of this testing is to ensure that the test item is functioning properly. The correctness of navigation through the object is tested, as well as the input, processing and output of data.
Database testing - checking the operability of the database during normal operation of the application, in moments of overloads and in multi-user mode.
Unit testing
For OOP, the usual organization of unit testing is to test the methods of each class, then the class of each package, and so on. Gradually, we move on to testing the entire project, and the previous tests are regression tests.
The output documentation of these tests includes test procedures, input data, code that executes the test, and output data. The following is a view of the output documentation.
Functional testing
Functional testing of the test object is planned and carried out based on the testing requirements specified during the requirements definition stage. The requirements are business rules, use-case diagrams, business functions, and, if available, activity diagrams. The purpose of functional tests is to verify that the developed graphics components meet specified requirements.
This type of testing cannot be fully automated. Hence, it is subdivided into:
- Automated testing (to be used in the case where the output can be verified).
Purpose: to test the input, processing and output of data;
- Manual testing (in other cases).
Purpose: The correctness of fulfillment of user requirements is tested.
It is necessary to execute (play) each of the use-cases, using both correct values and deliberately erroneous ones, to confirm correct functioning, according to the following criteria:
- the product responds adequately to all input data (expected results are displayed in response to correctly entered data);
- the product responds adequately to incorrectly entered data (corresponding error messages appear).
Database testing
The purpose of this testing is to make sure that database access methods are reliable, correctly executed, without compromising data integrity.
You should consistently use as many database calls as possible. An approach is used in which the test is composed in such a way as to "load" the base with a sequence of both correct values and deliberately erroneous ones. The response of the database to data input is determined, and the time intervals for their processing are estimated.
A measurement or test carried out to determine the condition or ability of an athlete is called dough... Not all measurements can be used as tests, but only those that meet special requirements: standard, availability of a rating system, reliability, information content, objectivity. Tests that meet the requirements of reliability, information content and objectivity are called solid.
The testing process is called testing, and the numerical values obtained as a result of the measurement are test result.
Tests based on motor tasks are called motor or motor... Three groups of motor tests are distinguished depending on the task that the subject faces.
Varieties of motor tests
|
Test name |
Assignment to the athlete |
Test result | |
|
Control exercise |
Motor achievements |
1500m running, running time |
|
|
Functional standard tests |
The same for all, dosed: 1) according to the amount of work performed; 2) by the magnitude of physiological shifts |
Physiological or biochemical indicators at standard work Motor indicators at a standard magnitude of physiological shifts |
Recording heart rate at standard work 1000 kgm / min Running speed at heart rate 160 beats / min |
|
Maximum functional tests |
Show maximum result |
Physiological or biochemical parameters |
Determination of maximum oxygen debt or maximum oxygen consumption |
Sometimes not one, but several tests are used with a single ultimate goal. This group of tests is called battery of tests.
It is known that even with the most stringent standardization and precise equipment, test results always vary somewhat. Therefore, one of the important conditions for the selection of good tests is their reliability.
Reliability of the test is the degree of coincidence of the results when the same people are tested again under the same conditions. There are four main reasons for intra-individual or intra-group variation in test results:
changes in the state of the subjects (fatigue, change in motivation, etc.); uncontrolled changes in external conditions and equipment;
change in the state of the person conducting or evaluating the test (well-being, replacement of the experimenter, etc.);
imperfection of the test (for example, deliberately imperfect and unreliable tests - free throws into the basketball basket before the first miss, etc.).
The test reliability criterion can be reliability factor, calculated as the ratio of the true variance to the variance recorded in the experiment: r = true s 2 / registered s 2, where the true value is understood as the variance obtained with an infinite number of observations under the same conditions; the recorded variance is derived from experimental studies. In other words, the coefficient of reliability is simply the fraction of true variation in the variation recorded in experience.
In addition to this coefficient, they also use reliability index, which is considered as the theoretical coefficient of correlation or relationship between the recorded and true values of the same test. This method is most common as a criterion for assessing the quality (reliability) of the test.
One of the characteristics of the reliability of the test is its equivalence, which reflects the degree of coincidence of the test results of the same quality (for example, physical) by different tests. The attitude to test equivalence depends on the specific task. On the one hand, if two or more tests are equivalent, their combined use increases the reliability of the estimates; on the other hand, it seems possible to apply only one equivalent test, which will simplify testing.
If all tests in any test battery are highly equivalent, they are called homogeneous(for example, to assess the quality of jumping, it must be assumed that the long jump, upward, triple jumps will be homogeneous). On the contrary, if there are no equivalent tests in the complex (for example, for assessing general physical fitness), then all tests included in it measure different properties, i.e. essentially the complex is heterogeneous.
The reliability of tests can be improved to a certain extent by:
stricter standardization of testing;
increasing the number of attempts;
increasing the number of evaluators and improving the consistency of their opinions;
increasing the number of equivalent tests;
better motivation of the subjects.
Objectivity of the test there is a special case of reliability, i.e. independence of test results from the person conducting the test.
Informativeness of the test Is the degree of accuracy with which it measures the property (athlete quality) for which it is used. In different cases, the same tests may have different informational content. The question of the informativeness of the test breaks down into two particular questions:
What does this test change? How exactly does it measure?
For example, is it possible to judge the readiness of distance runners by such an indicator as IPC, and if so, with what degree of accuracy? Can this test be used in the monitoring process?
If the test is used to determine the condition of an athlete at the time of examination, then they speak of diagnostic informativeness of the test. If, on the basis of the test results, they want to draw a conclusion about the possible future performance of the athlete, they talk about predictive informativeness. The test can be diagnostically informative, but not prognostically, and vice versa.
The degree of information content can be characterized quantitatively - on the basis of experimental data (the so-called empirical informativeness) and qualitatively - based on a meaningful analysis of the situation ( logical informativeness). Although in practical work, logical or meaningful analysis should always precede the mathematical one. The indicator of the informativeness of the test is the correlation coefficient calculated for the dependence of the criterion on the result in the test, and vice versa (the indicator is taken as a criterion, obviously reflecting the property that is going to be measured using the test).
In cases of insufficient information content of any test, they resort to using a battery of tests. However, the latter, even with high separate criteria for information content (judging by the correlation coefficients), does not allow obtaining a single number. Here a more complex method of mathematical statistics can come to the rescue - factor analysis. Which allows you to determine how many and which tests work together on a particular factor and what is the degree of their contribution to each factor. And then it is already easy to select the tests (or their combinations) that most accurately assess the individual factors.
|
1 What is called a test? | |
|
2 What is testing? |
Quantification of an Athlete's Quality or Condition A Measurement or Test to Determine an Athlete's Condition or Ability Testing Process that quantifies an Athlete's Quality or Condition No Definition Required |
|
3 What is called a test result? |
Quantification of an Athlete's Quality or Condition A Measurement or Test to Determine an Athlete's Condition or Ability Testing Process that quantifies an Athlete's Quality or Condition No Definition Required |
|
4 What kind of tests does running 100 meters? | |
|
5 What kind of tests does hand dynamometry? |
Control exercise Functional test Maximum functional test |
|
6 What kind of tests does the sample belong to? IPC? |
Control exercise Functional test Maximum functional test |
|
7 What kind of tests does three-minute run under the metronome? |
Control exercise Functional test Maximum functional test |
|
8 What kind of tests does the maximum number of pull-ups on the bar? |
Control exercise Functional test Maximum functional test |
|
9 In what case is a test considered informative? | |
|
10 When is the test considered reliable? |
The ability of the test to reproduce results when re-tested The ability of the test to measure the quality of the athlete of interest Independence of test results from the person conducting the test |
|
11 When is the test considered objective? |
The ability of the test to reproduce results when re-tested The ability of the test to measure the quality of the athlete of interest Independence of test results from the person conducting the test |
|
12 What criterion is necessary when assessing the test for information content? | |
|
13 What criterion is needed when evaluating a reliability test? |
Student's t-test F-Fisher's test Correlation coefficient Determination coefficient Variance |
|
14 What criterion is needed when evaluating the test for objectivity? |
Student's t-test F-Fisher's test Correlation coefficient Determination coefficient Variance |
|
15 What is the name of the informativeness of the test, if it is used to assess the degree of training of an athlete? | |
|
16 What informativeness of control exercises is the coach guided by when selecting children for his sports section? |
Logical Predictive Empirical Diagnostic |
|
17 Is correlation analysis necessary to assess the informativeness of tests? | |
|
18 Is factor analysis necessary to assess the informativeness of tests? | |
|
19 Is it possible to evaluate the reliability of a test using correlation analysis? | |
|
20 Is it possible to evaluate the objectivity of the test using correlation analysis? | |
|
21 Will tests designed to assess general physical fitness be equivalent? | |
|
22 When measuring the same quality by different tests, tests are used ... |
Designed to measure the same quality Having a high correlation among themselves Having a low correlation among themselves |
FUNDAMENTALS OF ASSESSMENT THEORY
To assess athletic performance, special scoring tables are often used. The purpose of such tables is to convert the shown sports result (expressed in objective measures) into conditional points. The law of converting sports results into points is called rating scale... The scale can be specified as a mathematical expression, table or graph. There are 4 main types of scales used in sports and physical education.
Proportional scales
Regression scales
Progressive scales.
Proportional scales imply the accrual of the same number of points for an equal increase in the results (for example, for every 0.1 s improvement in the result in the 100 m race, 20 points are awarded). Such scales are used in modern pentathlon, speed skating, skiing, Nordic combined, biathlon and other sports.
Regression scales imply the accrual, for the same increase in the result as sports achievements increase, an ever smaller number of points (for example, for an improvement in the result in 100 m running from 15, 0 to 14.9 s, 20 points are added, and for 0.1 s in the range 10.0-9.9 s - only 15 points).
Progressive scales. Here, the higher the sports result, the more points increase its improvement is estimated (for example, 10 points are added for an improvement in running time from 15.0 to 14.9 s, and 100 points from 10.0 to 9.9 s). Progressive scales are used in swimming, certain types of athletics, and weightlifting.
Sigmoid scales are rarely used in sports, but are widely used in assessing physical fitness (for example, this is how the scale of physical fitness standards of the US population looks like). On these scales, improvements in performance in the very low and very high performance zones are sparingly encouraged; the most points are gained by the increase in results in the middle achievement zone.
The main objectives of the assessment are:
compare different achievements in the same task;
compare achievements in different tasks;
define norms.
The norm in sports metrology, the boundary value of the result is called, which serves as the basis for attributing an athlete to one of the classification groups. There are three types of norms: comparative, individual, due.
Comparative norms are based on the comparison of people belonging to the same population. For example, dividing people into subgroups according to the degree of resistance (high, medium, low) or reactivity (hyperreactive, normoreactive, hyporeactive) to hypoxia.
Different grades of assessments and norms
|
Percentage of test subjects |
Norms in scales |
||||||||
|
Verbal |
in points |
Percentile |
|||||||
|
Very low |
Below M - 2 | ||||||||
|
From M - 2 to M - 1 | |||||||||
|
Below average |
From M-1 to M-0.5 | ||||||||
|
From M – 0.5 to M + 0.5 | |||||||||
|
Above average |
From M + 0.5 to M + 1 | ||||||||
|
From M + 1 to M + 2 | |||||||||
|
Very high |
Above M + 2 | ||||||||
These norms characterize only the comparative success of the subjects in a given population, but they do not say anything about the population as a whole (or on average). Therefore, benchmarking rates should be compared with data from other populations and used in conjunction with individual and proper rates.
Individual norms based on a comparison of the performance of the same athlete in different states. For example, in many sports there is no relationship between your own body weight and athletic performance. Each athlete has an individually optimal weight corresponding to the state of sports form. This rate can be controlled at different stages of sports training.
Due norms based on an analysis of what a person should be able to successfully cope with the tasks that life sets before him. An example of this can be the standards of individual complexes for physical training, the proper values of VC, basal metabolic rate, body weight and height, etc.
|
1 Is it possible to directly measure the quality of endurance? | |
|
2 Is it possible to directly measure the quality of speed? | |
|
3 Is it possible to directly measure the quality of dexterity? | |
|
4 Is it possible to directly measure the quality of flexibility? | |
|
5 Is it possible to directly measure the strength of individual muscles? | |
|
6 Can the assessment be expressed in a qualitative characteristic (good, satisfactory, bad, credit, etc.)? | |
|
7 Is there a difference between a measurement scale and a rating scale? | |
|
8 What is a rating scale? |
System for measuring sports results The law of converting sports results into points System for assessing norms |
|
9 The scale assumes the accrual of the same number of points for an equal increase in results. It … | |
|
10 For the same increase in the result, a smaller number of points are awarded as sports achievements increase. It … |
Progressive scale Regressive scale Proportional scale Sigmoid scale |
|
11 The higher the sports result, the more points increase its improvement is estimated. It … |
Progressive scale Regressive scale Proportional scale Sigmoid scale |
|
12 Improvement in performance in very low and very high performance areas is sparingly encouraged; the most points are gained by the increase in results in the middle achievement zone. It … |
Progressive scale Regressive scale Proportional scale Sigmoid scale |
|
13 Norms based on the comparison of people belonging to the same population are called ... | |
|
14 The norms based on the comparison of the performance of the same athlete in different states are called ... |
Individual standards Due standards Comparative standards |
|
15 The norms based on the analysis of what a person should be able to do in order to cope with the tasks assigned to him are called ... |
Individual standards Due standards Comparative standards |
BASIC CONCEPTS OF QUALIMETRY
Qualimetry(Latin qualitas - quality, metron - measure) studies and develops quantitative methods for assessing qualitative characteristics.
Qualimetry is based on several assumptions:
Any quality can be measured;
The quality depends on a number of properties that form the “tree of quality” (for example, the tree of the quality of exercises performance in figure skating consists of three levels - the highest, the middle, the lowest);
Each property is defined by two numbers: relative index and weight; the sum of the weights of properties at each level is equal to one (or 100%).
Qualimetry methodological techniques are divided into two groups:
Heuristic (intuitive) based on expert assessments and questionnaires;
Instrumental.
Expert is called an estimate obtained by asking the opinions of specialists. Typical examples of expertise: judging in gymnastics and figure skating, competition for the best scientific work, etc.
The examination includes the following main stages: the formation of its goal, the selection of experts, the choice of the methodology, the survey and the processing of the information received, including the assessment of the consistency of individual expert assessments. During the examination, the degree of consistency of the opinions of experts is of great importance, assessed by the value rank correlation coefficient(in case of several experts). It should be noted that rank correlation underlies the solution of many qualimetry problems, since it allows mathematical calculations with qualitative features.
In practice, an indicator of an expert's qualifications is often the deviation of his assessments from the average assessments of a group of experts.
Questioning is called the method of collecting opinions by filling out questionnaires. Questionnaire, along with interview and conversation, refers to survey methods. In contrast to interviews and conversations, the questionnaire survey presupposes written answers of the person filling out the questionnaire - the respondent - to a system of standardized questions. It allows you to study the motives of behavior, intentions, opinions, etc.
With the help of questionnaires, it is possible to solve many practical problems in sports: assessment of the psychological status of an athlete; his attitude to the nature and orientation of training sessions; interpersonal relationships in the team; own assessment of technical and tactical readiness; assessment of the diet and many others.
|
1 What does qualimetry study? |
Studying the quality of tests Studying the qualitative properties of the trait Studying and developing quantitative methods for assessing the quality |
|
2 Mathematical methods used in qualimetry? |
Pairwise correlation Rank correlation Analysis of variance |
|
3 What methods are used to assess the level of performance? | |
|
4 What methods are used to assess the diversity of technical elements? |
Questionnaire method Method of expert assessments Method not specified |
|
5 What methods are used to evaluate the complexity of technical elements? |
Questionnaire method Method of expert assessments Method not specified |
|
6 What methods are used to assess the psychological state of an athlete? |
Questionnaire method Method of expert assessments Method not specified |
The first component, test theory, contains a description of the statistical models for processing diagnostic data. It contains models for analyzing answers in test items and models for calculating the total test results. Mellenberg (1980, 1990) called this "psychometrics." Classical test theory, modern test theory (or model of analysis of answers to test items - IRT) and model
sample items constitute the three most important types of test theory models. The subject of psychodiagnostics is the first two models.
Classical test theory. Most of the intelligence and personality tests have been developed on the basis of this theory. The central concept of this theory is the concept of "reliability". Reliability refers to the consistency of results when reevaluated. In reference books, this concept is usually presented very briefly, and then a detailed description of the apparatus of mathematical statistics is given. In this introductory chapter, we present a concise description of the main meaning of the noted concept. In the classical theory of tests, reliability is understood as the repeatability of the results of several measurement procedures (mainly measurements using tests). Reliability involves calculating the measurement error. The results obtained during testing can be presented as the sum of the true result and the measurement error:
Xi = Ti+ Еj
where Xi is the evaluation of the results obtained, Ti is the true result, and Еj- measurement error.
The assessment of the results obtained is, as a rule, the number of correct answers to the test tasks. The true result can be seen as a true estimate in the Platonic sense (Gulliksen, 1950). The concept of expected results is widespread, i.e. ideas about the points that can be obtained as a result of a large number of repetitions of measurement procedures (Lord & Novich, 1968). But it is not possible to carry out the same assessment procedure with one person. Therefore, it is necessary to search for other solutions to the problem (Witlman, 1988).
Within this concept, some assumptions are made about the true results and measurement errors. The latter are taken as an independent factor, which, of course, is a well-founded assumption, since random fluctuations in the results do not give covariances: r EE = 0.
It is assumed that there is no correlation between true scores and measurement errors: r EE = 0.
The total error is 0, because the arithmetic mean is taken as a true estimate:
These assumptions eventually lead us to the well-known definition of reliability as the ratio of the true result to the total variance or expression: 1 minus the ratio, in the numerator of which is the measurement error, and in the denominator - the total variance:
 , OR
, OR 
From this formula for determining the reliability, we obtain that the variance of the error S 2 (E) is equal to the total variance in the number of cases (1 - r XX "); thus, the standard error of measurement is determined by the formula:
![]()
After the theoretical substantiation of the reliability and its derivatives, it is necessary to determine the reliability index of a particular test. There are practical procedures for evaluating test reliability, such as using interchangeable forms (parallel tests), splitting items into two, retesting, and measuring internal consistency. Each reference contains indexes of the constancy of test results:
r XX ’= r (x 1, x 2)
where r XX ’ is the stability coefficient, and x 1 and x 2 - the results of two measurements.
The concept of the reliability of interchangeable forms was introduced and developed by Gulliksen (1950). This procedure is rather laborious, since it is associated with the need to create a parallel series of tasks.
r XX ’= r (x 1, x 2)
where r XX ’ is the equivalence coefficient, and x 1 and x 2 - two parallel tests.
The next procedure - splitting the main test into two parts A and B - is easier to use. The indicators obtained for both parts of the test are correlated. Using the Spearman-Brown formula, the reliability of the test as a whole is assessed:
where A and B are two parallel parts of the test.
The next method is to determine the internal consistency of the test items. This method is based on determining the covariance of individual items. Sg is the variance of a randomly selected item, and Sgh is the covariance of two randomly selected items. The most commonly used coefficient for determining internal consistency is Cronbach's “alpha coefficient”. The formula is also used KP20 and λ-2(lambda-2).
In the classical concept of reliability, measurement errors are determined that occur both during testing and during observation. The sources of these errors are different: it can be personal characteristics, and the peculiarities of the testing conditions, and the test tasks themselves. There are specific methods for calculating errors. We know that our observations can turn out to be wrong, our methodological tools are imperfect, just as people themselves are imperfect. (How not to remember Shakespeare: "You are unreliable, whose name is man"). The fact that in classical test theory measurement errors are explicated and explained is an important positive point.
The classical test theory has a number of significant features that can be considered as its shortcomings. Some of these characteristics are noted in reference books, but their importance (from an everyday point of view) is rarely emphasized, just as it is not noted that, from a theoretical or methodological point of view, they should be considered shortcomings.
First. The classical theory of tests and the concept of reliability are focused on calculating the total test indicators, which are the result of adding the estimates obtained in separate tasks. So, when working
Second. The reliability factor assumes an estimate of the magnitude of the spread of the measured indicators. It follows that the coefficient of reliability will be lower if (with the equality of other indicators) the sample is more homogeneous. There is no single coefficient of internal consistency of test items, this coefficient is always "contextual". Crocker and Aljina (1986), for example, propose a special “homogeneous sample correction” formula designed for the highest and lowest scores obtained by those undergoing testing. It is important for the diagnostician to know the characteristics of the variations in the sample, otherwise he will not be able to use the coefficients of internal consistency specified in the manual for this test.
Third. The phenomenon of reduction to the arithmetic mean is a logical consequence of the classical concept of reliability. If the score on the test fluctuates (i.e., it is not reliable enough), then it is quite possible that when the procedure is repeated, subjects with low scores will receive higher scores, and vice versa, subjects with high scores will receive low scores. This artifact of the measurement procedure cannot be mistaken for a true change or manifestation of developmental processes. But at the same time, it is not easy to distinguish between them, tk. the possibility of change in the course of development can never be ruled out. For complete confidence, it is necessary to "compare with the control group.
The fourth characteristic of tests designed in accordance with the principles of classical theory is the availability of normative data. Knowledge of test norms allows the researcher to adequately interpret the results of the tested. Outside of the norm, test scores are meaningless. The development of test norms is a rather expensive undertaking, since a psychologist must obtain test results on a representative sample.
2 Ya ter Laak
If we talk about the shortcomings of the classical concept of reliability, then it is appropriate to cite the statement of Si-tsma (1992, pp. 123-125). He notes that the first and foremost assumption of classical test theory is that test results obey the interval principle. However, there are no studies to support this assumption. In essence, this is a "measurement according to an arbitrarily established rule." This feature puts the classical theory of tests in a less favorable position in comparison with the scales of measurement of attitudes and, of course, in comparison with the modern theory of tests. Many methods of data analysis (analysis of variance, regression analysis, correlation and factor analysis) are based on the assumption of the existence of an interval scale. However, it does not have a solid foundation. To consider the scale of true results as a scale of values of psychological characteristics (for example, arithmetic abilities, intelligence, neuroticism) can only be assumed.
The second remark concerns the fact that the results of the test are not absolute indicators of one or another psychological characteristic of the tested person, they should be considered only as the results of the performance of this or that test. Two tests may claim to study the same psychological characteristics (for example, intelligence, verbal ability, extraversion), but this does not mean that the two tests are equivalent and have the same capabilities. Comparison of the indicators of two people tested by different tests is incorrect. The same applies to the completion of two different tests by the same subject. The third remark refers to the assumption that the standard error of measurement is the same for any level of the individual's measurable ability. However, there is no empirical test for this assumption. So, for example, there is no guarantee that a test taker with good mathematical ability will get high scores when working with a relatively simple arithmetic test. In this case, a person with low or average abilities is more likely to receive a high rating.
Within the framework of modern test theory or theory of answer analysis, test items contain a description of a large
the number of models of possible responses of respondents. These models differ in their underlying assumptions, as well as requirements in relation to the obtained data. The Rush model is often seen as synonymous with theories of analysis of answers to questions on the test (1RT). In fact, this is only one of the models. The formula presented in it for describing the characteristic curve for setting g is as follows:

where g- a separate test task; exp- exponential function (non-linear dependence); δ ("Delta") - the difficulty level of the test.
Other test items such as h, also get their own characteristic curves. Condition fulfillment δ h> δ g (g means that h- a more difficult task. Therefore, for any value of the indicator Θ ("Theta" - latent properties of test takers' abilities) probability of successful completion of the task h smaller. This model is called strict because it is obvious that with a low degree of expression of the trait, the probability of completing the task is close to zero. There is no room for guesswork or guesswork in this model. For assignments with options, there is no need to make assumptions about the likelihood of success. In addition, this model is strict in the sense that all test items must have the same discriminative ability (high discriminativeness is reflected in the slope of the curve; here it is possible to construct a Guttmann scale, according to which at each point of the characteristic curve the probability of completing a task varies from O to 1). Because of this condition, not all assignments can be included in tests based on the Rush model.
There are several variants of this model (for example, Birnbaura, 1968, See Lord & Novik). It allows the existence of tasks with different discriminative
ability.
The Dutch researcher Mokken (1971) has developed two models for analyzing answers in test items, the requirements of which are not as strict as in the Rush model, and therefore, perhaps, are more realistic. As the main condition
Viya Mokken puts forward the position that the characteristic curve of the task should follow monotonously, without breaks. At the same time, all test tasks are aimed at studying the same psychological characteristics, which should be measured v. Any form of this dependency is allowed as long as it does not break. Therefore, the shape of the characteristic curve is not determined by any specific function. This "freedom" allows you to use more items on the test, and the level of assessment is no higher than the usual one.
The methodology of response models to test items (IRT) differs from the methodology of most experimental and correlation studies. The mathematical model is designed to study behavioral, cognitive, emotional characteristics, as well as developmental phenomena. These phenomena under consideration are often limited to responses to tasks, which has led Mellenberg (1990) to refer to IRT as a "mini-theory of mini-behavior." The results of the study can to a certain extent be presented as concordance curves, especially in cases where there is no theoretical understanding of the studied characteristics. Until now, we have at our disposal only a few tests of intelligence, ability and personality tests, created on the basis of numerous models of the IRT theory. Variants of Rush's model are more commonly used in the design of achievement tests (Verhelst, 1993), while Mocken's models are more suited to developmental phenomena (see also Chapter 6).
The test taker's response to the test items is the basic unit of the IRT models. The type of response is determined by the severity of the studied characteristic in a person. Such a characteristic can be, for example, arithmetic or spatial ability. In most cases, this is one or another aspect of intelligence, characteristics of achievement or personality traits. It is assumed that there is a nonlinear relationship between the position of this particular person in a certain range of the studied characteristic and the probability of successful completion of a particular task. The nonlinearity of this relationship is, in a sense, intuitive. Famous phrases "Every beginning is difficult" (slow
linear start) and “Becoming a saint is not so easy” mean that further improvement after reaching a certain level is difficult. The curve slowly approaches, but almost never reaches 100% success rate.
Some models are more likely to contradict our intuitive understanding. Let's take this example. A person with an index of the severity of an arbitrary characteristic equal to 1.5 has a 60 percent probability of success on the task. This contradicts our intuitive understanding of this situation, because you can either successfully cope with the task, or not cope with it at all. Let's take this example: 100 times a person tries to take a height of 1m 50 cm. Success accompanies him 60 times, i.e. it has a 60 percent success rate.
To assess the severity of the characteristic, at least two tasks are required. The Rush model assumes the determination of the severity of characteristics, regardless of the difficulty of the task. This also contradicts our intuitive understanding: suppose that a person has an 80 percent probability of jumping above 1.30 m.If so, according to the characteristic curve of the tasks, he has a 60 percent probability of jumping above 1.50 m and a 40 percent the probability of jumping higher than 1.70 m. Therefore, regardless of the value of the independent variable (height), it is possible to assess a person's ability to jump in height.
There are about 50 IRT models (Goldstein & Wood, 1989). There are many non-linear functions that describe (explain) the likelihood of success in a task or group of tasks. The requirements and limitations of these models are different, and these differences can be found when comparing the Rush model and the Mocken scale. The requirements of these models include:
1) the need to determine the studied characteristics and assess the position of a person in the range of this trait;
2) assessment of the sequence of tasks;
3) verification of specific models. In psychometrics, many procedures have been developed to test a model.
In some reference books, IRT theory is considered as a form of test item analysis (see, for example,
Croker & Algina, J 986). It is possible, however, to argue that the IRT theory is a "mini-theory of mini-behavior." Proponents of the IRT theory note that if middle-level concepts (models) are imperfect, then what about the more complex constructs in psychology?
Classical and modern test theory. People can't help but compare things that look almost the same. (Perhaps the everyday equivalent of psychometry consists mainly in comparing people according to significant characteristics and choosing between them). Each of the theories presented - both the theory of measuring estimation errors and the mathematical model of answers to test items - has its supporters (Goldstein & Wood, 1986).
The IRT models are not reproached for being “rule-based,” in contrast to classical test theory. The IRT model is focused on the analysis of the assessed characteristics. Personality characteristics and characteristics of tasks are assessed using scales (ordinal or interval). Moreover, it is possible to compare the performance indicators of different tests aimed at studying similar characteristics. Finally, reliability is not the same for each value on the scale, and averages are usually more reliable than those at the beginning and end of the scale. Thus, the IRT models appear to be more advanced in theory. There are also differences in the practical use of modern test theory and classical theory (Sijstma, 1992, pp. 127-130). Modern test theory is more complex than classical test theory, so it is less commonly used by non-specialists. Moreover, IRT has special requirements for assignments. This means that items should be excluded from the test if they do not meet the model's requirements. This rule applies further to those tasks that were part of the widely used tests, built according to the principles of classical theory. The test becomes shorter and therefore less reliable.
IRT offers mathematical models for studying real-world phenomena. Models should help us understand key aspects of these phenomena. However, there is a basic theoretical question here. Models can be considered
as an approach to the study of the complex reality in which we live. But model and reality are not the same thing. According to the pessimistic view, it is possible to model only isolated (and, moreover, not the most interesting) types of behavior. You can also find the statement that reality is not subject to modeling at all, because it obeys not only the laws of cause and effect. At best, it is possible to model individual (ideal) behavioral phenomena. There is another, more optimistic view of the possibilities of modeling. The above position blocks the possibility of deep comprehension of the nature of the phenomena of human behavior. The application of this or that model raises some general, fundamental questions. In our opinion, there is no doubt that IRT is a concept theoretically and technically superior to the classical test theory.
The practical purpose of tests, on whatever theoretical basis they are created, is to define significant criteria and establish, on their basis, the characteristics of certain psychological constructs. Does the IRT model have advantages in this regard as well? It is possible that tests based on this model do not provide a more accurate prediction than tests based on classical theory, and it is possible that their contribution to the development of psychological constructs is not more significant. Diagnosticians prefer criteria that are directly relevant to an individual, institution, or community. A more scientifically advanced model "ipso facto" * does not define a more appropriate criterion and is somewhat limited in explaining scientific constructs. It is obvious that the development of tests based on the classical theory will continue, but at the same time new IRT models will be created, extending to the study of a larger number of psychological phenomena.
In the classical theory of tests, the concepts of "reliability" and "validity" are distinguished. Test results should be reliable, i.e. the results of the initial and retesting should be consistent. Besides,
* ipso facto(varnish) - by itself (approx. transl.).
the results should be free (as far as possible) from estimation errors. The presence of validity is one of the requirements for the results obtained. In this case, reliability is considered as a necessary, but not yet a sufficient condition for the validity of the test.
Validity assumes that the results obtained are related to something of practical or theoretical importance. The conclusions drawn from the test scores must be valid. Most often they talk about two types of validity: predictive (criterion) and construct. There are also other types of validity (see Chapter 3). In addition, validity can also be determined in the case of quasi-experiments (Cook & Campbell, 1976, Cook & Shadish, 1994). However, the main type of validity is still predictive validity, which is understood as the ability to predict something significant about behavior in the future from the test result, as well as the possibility of a deeper understanding of a particular psychological property or quality.
The types of validity presented are discussed in each guide and are accompanied by a description of the methods for analyzing the validity of the test. Factor analysis is more suitable for determining construct validation, and linear regression equations are used to analyze predictive validity. These or those characteristics (academic performance, effectiveness of therapy) can be predicted on the basis of one or more indicators, obtained when working with intellectual or personality tests. Data processing techniques such as correlation, regression, analysis of variance, analysis of partial correlations and variances are used to determine the predictive validity of a test.
Content validity is often described as well. It is assumed that all tasks and tasks of the test should belong to a specific area (mental properties, behavior, etc.). The concept of meaningful validity characterizes the correspondence of each test task to the measured area. Content validity is sometimes seen as part of robustness or "generalizability" (Cronbach, Gleser, Nanda & Rajaratnam, 1972). However, with
When choosing items for tests of achievement in a specific subject area, it is also important to pay attention to the rules for including items in the test.
In classical test theory, reliability and validity are considered relatively independently of each other. But there is also another understanding of the relationship between these concepts. Modern test theory is based on the application of models. The parameters are evaluated within a certain model. If the task does not meet the requirements of the model, then within the framework of this model it is recognized as invalid. Construct validation is part of the validation of the model itself. This validation refers mainly to the verification of the existence of a one-dimensional latent trait under investigation with known scale characteristics. Scale scores, of course, can be used to determine the appropriate criteria, and their correlation with the indicators of other constructs is possible to collect information about the convergent and divergent validity of the construct.
Psychodiagnostics is analogous to language, described as the unity of four components, represented at three levels. The first component, test theory, is analogous to the syntax, the grammar of the language. Generative (generative) grammar is, on the one hand, an ingenious model, on the other, a system that obeys rules. With the help of these rules, complex sentences are built on the basis of simple affirmative sentences. At the same time, however, this model leaves aside the description of how the communication process is organized (what is transmitted and what is perceived), and for what purposes it is carried out. To understand this, additional knowledge is required. The same can be said about the theory of tests: it is necessary in psychodiagnostics, but it is not able to explain what the psychodiagnostician does and what his goals are.
1.3.2. Psychological theories and psychological constructs
Psychodiagnostics is always a diagnosis of something specific: personal characteristics, behavior, thinking, emotions. The tests are designed to assess individual differences. There are several concepts
individual differences, each of which has its own distinctive characteristics. If it is recognized that psychodiagnostics is not limited only to the assessment of individual differences, then other theories also acquire essential significance for psychodiagnostics. An example is the assessment of differences in mental development processes and differences in the social environment. Although the assessment of individual differences is not an indispensable attribute of psychodiagnostics, nevertheless there are certain traditions of research in this area. Psychodiagnostics began with an assessment of the differences in intelligence. The main task of the tests was to "determine the inherited transmission of genius" (Gallon) or the selection of children for training (Binet, Simon). The measurement of the intelligence quotient received theoretical comprehension and practical development in the works of Spearman (Great Britain) and Thurstone (USA). Raymond B. Kettel did a similar thing to assess personality traits. Psychodiagnostics becomes inextricably linked with theories and ideas about individual differences in achievements (assessment of extreme possibilities) and forms of behavior (level of typical functioning). This tradition continues to be effective today. In textbooks on psychodiagnostics, differences in the social environment are much less often assessed in comparison with the consideration of the characteristics of the developmental processes themselves. There is no reasonable explanation for this. On the one hand, diagnostics are not limited to specific theories and concepts. On the other hand, it needs theories, since it is in them that the diagnosed content is determined (that is, "what" is diagnosed). So, for example, intelligence can be considered both as a general characteristic and as the basis for many independent abilities. If psychodiagnostics is trying to "get away" from one theory or another, then common sense ideas become the basis of the psychodiagnostic process. In research, various methods of data analysis are used, and the general logic of research determines the choice of a particular mathematical model and determines the structure of the psychological concepts used. Such methods of mathematical statistics
ki, as analysis of variance, regression analysis, factor analysis, calculation of correlations assume the existence of linear dependencies. In case of incorrect application of these methods, they "bring" their structure into the received data and used constructs.
The ideas about the differences in the social environment and about the development of the personality had almost no effect on psychodiagnostics. Textbooks (see, for example, Murphy & Davidshofer, 1988) consider the classical theory of tests and discuss the appropriate methods of statistical processing, describe well-known tests, consider the use of psychodiagnostics in practice: in management psychology, in personnel selection, in assessing the psychological characteristics of a person ...
Theories of individual differences (as well as ideas about the differences between social environment and mental development) are similar to the study of the semantics of language. This is the study of the essence, and the content, and the meaning. Meanings are structured in a certain way (like psychological constructs), for example, by similarity or contrast (analogy, convergence, divergence).
1.3.3. Psychological tests and other methodological tools
The third component of the proposed scheme is tests, procedures and methodological tools, with the help of which information about personality characteristics is collected. Draene and Siitsma (1990, p. 31) give the following definition of tests: “A psychological test is considered as a classification according to a certain system or as a measurement procedure that makes it possible to make a certain judgment about one or several empirically selected or theoretically substantiated characteristics of a particular side of human behavior (for the framework of the test situation). At the same time, the response of respondents to a certain number of carefully selected stimuli is considered, and the received answers are compared with the test norms ”.
Diagnostics require tests and techniques to collect reliable, accurate, and valid information about features
and personality traits, thinking, emotions and behavior of a person. In addition to developing test procedures, this component also includes the following questions: how tests are created, how tasks are formulated and selected, how the testing process proceeds, what are the requirements for testing conditions, how measurement errors are taken into account, how test results are calculated and interpreted.
In the process of developing tests, rational and empirical strategies are distinguished. The application of a rational strategy begins with the definition of basic concepts (for example, the concepts of intelligence, extraversion), and in accordance with these ideas, test tasks are formulated. An example of such a strategy is Guttman's concept of the facet theory (1957, 1968, 1978). First, various aspects of the basic constructs are identified, then tasks and tasks are selected in such a way that each of these aspects is taken into account. The second strategy is that tasks are selected on an empirical basis. For example, if a researcher tries to create a test of professional interests that would differentiate physicians from engineers, then the procedure should be like this. Both groups of respondents must answer all the test items, and those items in the answers to which statistically significant differences are found are included in the final version of the test. If, for example, there are differences between groups in the responses to a statement “I love fishing,” then that statement becomes an element of the test. The main point of this book is that the test is related to the conceptual or taxonomic theory that defines these characteristics.
The purpose of the test is usually specified in the instructions for use. The test needs to be standardized so that it can measure differences between people and not between testing conditions. There are, however, deviations from standardization in procedures called testing the limits and learning potential tests. In these conditions, the respondent is assisted in the process
testing and then evaluating the impact of such a procedure on the result. Scoring for answers to tasks is objective, i.e. carried out in accordance with the standard procedure. The interpretation of the results obtained is also strictly defined and carried out on the basis of test norms.
The third component of psychodiagnostics - psychological tests, tools, procedures - contains certain tasks, which are the smallest units of psychodiagnostics and in this sense, tasks are similar to the phonemes of the language. The number of possible combinations of phonemes is limited. Only certain phonemic structures can form words and sentences that provide information to the listener. Also and test items: only in a certain combination with each other, they can become an effective means of assessing the corresponding construct.