Istota metody symulacji. Modelowanie symulacji procesów gospodarczych: cechy i główne typy
Federalna agencja rybołówstwa
minister rolnictwa
Kamchatsky Gosardic Technical University
Departament Systemów Informacyjnych
Temat: "Imitacja modelowania ekonomicznego
Działalność przedsiębiorstw »
Praca kursu
Lider: Pozycja
Billchinskaya s.g. "__" ________ 2006
Deweloper: Student C.
Zheitheva D.S. 04 PI1 "__" ________ 2006
Praca jest chroniona przez "___" __________ 2006 Z szacunkiem ______
Petropavlovsk- Kamchatsky, 2006
Wprowadzenie ................................................. .. ................................................ .. ......................... 3.
1. Teoretyczne podstawy modelowania imitacji .......................................... 4
1.1. Modelowanie. Modelowanie symulacyjne .......................................... 4
1.2. Metoda Monte Carlo ............................................... ........................................... dziewięciu
1.3. Wykorzystanie praw dystrybucji zmiennych losowych ....................... 12
1.3.1. Jednolita dystrybucja ................................................ ................ 12.
1.3.2. Dystrybucja dyskretna (ogólna sprawa) ................................... 13
1.3.3. Normalna dystrybucja................................................ .................. czternaście.
1.3.4. Dystrybucja wykładnicza ................................................ ...... piętnaście
1.3.5. Uogólniona dystrybucja Erlandia .............................................. . .. Szesnaście.
1.3.6. Dystrybucja trójkątna ................................................ ................. 17.
1.4. Planowanie eksperymentu komputera symulacyjnego ................... 18
1.4.1. Cyber \u200b\u200bPodejście do organizacji badań eksperymentalnych złożonych obiektów i procesów ................................... ..... ............................................. ..... ............. osiemnaście.
1.4.2. Analiza regresji i modelowanie modelowania modelu. dziewiętnaście
1.4.3. Ortogonalne planowanie drugiego rzędu ................................ 20
2. Praktyczna praca .......................................... .................................................. ..... 22.
3. Wnioski dotyczące modelu biznesowego "Wydajność produkcji" ................................... 26
Wnioski ................................................. .................................... .............. .............. ..................... 31.
Bibliografia ............................................... .. ................................. 32.
Załącznik A ................................................ .................................................. .......... 33.
Załącznik B ................................................ .................................................. ........... 34.
Dodatek w ................................................ .. ................................................ .. ........... 35.
Dodatek G ................................................ .................................................. ........... 36.
Dodatek D ................................................ .................................................. ........... 37.
Dodatek E ................................................ .................................................. ........... 38.
Wprowadzenie
Modelowanie w gospodarce zaczęła stosować na długo przed gospodarką ostatecznie podjęte jako niezależne dyscypliny naukowej. Modele matematyczne były używane przez F. Kene (1758. Stół ekonomiczny), A. Smith (klasyczny model makroekonomiczny), D. Ricardo (Międzynarodowy model handlowy). W XIX wieku szkoła matematyczna (L. Valras, O. Kurto, Pareto, F. Edgeworth i inni, przyczyniły się do modelowania. W XX wieku metody modelowania matematycznego gospodarki były stosowane bardzo szeroko i przy użyciu związane są z wybitnymi dziełami zwycięzców Nagrody Nobla (D. Hicks, R. Solowa, V. Leontiev, P. Samuelson).
Oczywiście prace nad przedmiotem "Modelowanie imitacja procesów gospodarczych" jest niezależną pracą edukacyjną i badawczą.
Celem pisania tej pracy oczywiście jest konsolidacja wiedzy teoretycznej i praktycznej. Podejście oświetleniowe i metody korzystania z modelowania imitacji w ramach projektu działalności gospodarczej.
Głównym zadaniem jest zbadanie skuteczności działalności gospodarczej przedsiębiorstwa za pomocą modelowania symulacji.
1. Teoretyczne podstawy modelowania imitacji
1.1. Modelowanie. Modelowanie symulacji.
W procesie zarządzania różnymi procesami konieczność przewidywania wyników w pewnych warunkach stale przewiduje. Aby przyspieszyć decyzję w sprawie wyboru optymalnej wersji zarządzania i oszczędności do eksperymentu, stosuje się procesy.
Modelowanie jest transferem właściwości jednego systemu, który nazywa się obiektem modelowania, do innego systemu, który nazywa się modelem obiektu, wpływ na model jest przeprowadzany w celu określenia właściwości obiektu według natury jego zachowanie.
Taka wymiana (transfer) właściwości obiektu musi być wykonana w przypadkach, gdy bezpośrednio studiuje, jest trudne, a nawet niemożliwe. Jako praktyka pokazów modelowania obiekt zastępujący jego model daje często pozytywny efekt.
Model jest reprezentacją obiektu, systemu lub koncepcji (pomysłów) w jakiejś formie innej niż ich prawdziwe istnienie. Model dowolnego obiektu może być dokładną kopią tego obiektu (choć wykonany z innego materiału i na innej skali) lub wyświetla niektóre z charakterystycznych właściwości obiektu w postaci abstrakcyjnej.
Jednocześnie podczas procesu symulacji możliwe jest uzyskanie wiarygodnych informacji o obiekcie przy mniejszym czasie, finanse, funduszy i innych zasobach.
Główne cele modelowania są:
1) Analiza i definicja właściwości obiektów według modelu;
2) projektowanie nowych systemów i rozwiązanie na model zadania optymalizacji (znalezienie najlepszej opcji);
3) zarządzania obiektów złożonych i procesów;
4) prognozowanie zachowania się obiektu w przyszłości.
Najczęstsze rodzaje modelowania są najczęstsze:
1) matematyczny;
2) fizyczne;
3) Imitacja.
W modelowaniu matematycznym, w ramach badania obiektu zastępuje się odpowiednimi stosunkami matematycznymi, wzorami, wyrażeniami, z którymi niektóre zadania analityczne są rozwiązywane (analiza), istnieją optymalne rozwiązania, a prognozy są wykonane.
Modele fizyczne są prawdziwymi systemami tego samego rodzaju, co badany obiekt lub inny. Najbardziej typową opcją modelowania fizycznego jest użycie układów, instalacji lub wyboru fragmentów obiektów dla ograniczonych eksperymentów. I najczęściej znaleźć zastosowanie nauk przyrodniczych, czasami w gospodarce.
W przypadku systemów złożonych obejmuje systemy ekonomiczne, społeczne, informacyjne i inne społeczno-informacyjne, była szeroko stosowana symulacja symulacji. Jest to wspólny rodzaj modelowania analogowego realizowanego przy użyciu zestawu matematycznych narzędzi instrumentalnych specjalnych imitujących programów komputerowych i technologii programistycznych, umożliwiając procesom analogowym przeprowadzenie ukierunkowanego badania struktury i funkcji prawdziwego złożonego procesu w pamięci komputera w pamięci Tryb "imitacja", wykonaj optymalizację niektórych parametrów.
Aby uzyskać niezbędne informacje lub wyniki, konieczne jest "uruchomienie" modeli symulacyjnych, a nie "zdecydować o nich. Modele imitacji nie są w stanie tworzyć własnego rozwiązania, w którym odbywa się w modelach analitycznych, i może służyć jedynie jako sposób na analizę zachowania systemu w warunkach określonych przez eksperymentatora.
W konsekwencji modelowanie imitacji nie jest teorią, ale metodologią rozwiązywania problemów. Ponadto modelowanie symulacji jest tylko jedną z kilku dostępnych systemowych analitycznych najważniejszych metod rozwiązywania problemów. Ponieważ konieczne jest, aby dostosować narzędzie lub metodę do rozwiązania problemu, a nie odwrotnie, a następnie pojawia się naturalne pytanie: w jakich przypadkach przydatne jest modelowanie naśladowanie?
Potrzeba rozwiązywania problemów przez eksperymentowanie staje się widoczne, gdy potrzeba powstaje informacje o konkretnych informacji, których nie można znaleźć w znanych źródłach. Bezpośrednie eksperymentowanie na prawdziwym systemie eliminuje wiele trudności, jeśli konieczne jest zapewnienie zgodności między modelem a rzeczywistymi warunkami; Jednak wady takiego eksperymentowania są czasami bardzo znaczące:
1) może zakłócić ustaloną procedurę spółki;
2) Jeżeli składnik systemu jest ludzie, wyników eksperymentów może wpływać na tak zwany efekt koutorm, przejawiający się w fakcie, że ludzie czują, że są dla nich obserwowane, mogą zmienić ich zachowanie;
3) może być trudny do utrzymania tych samych warunków pracy z każdym powtórzeniem eksperymentu lub w ciągu całego czasu serii eksperymentalnej;
4) Aby uzyskać taki sam rozmiar próbki (w konsekwencji, istotne znaczenie statystyczne wyników eksperymentów) może wymagać nadmiernych kosztów czasu i środków;
5) Podczas eksperymentowania z prawdziwymi systemami może być niemożliwe do badania wielu alternatywnych opcji.
Z tych powodów, badacz powinien rozważyć wykonalność modelowania imitacji w obecności dowolnego z następujących warunków:
1. Nie ma ukończonego formułowania matematycznego tego zadania, ani analityczne metody rozwiązywania formułowanego modelu matematycznego nie zostały jeszcze opracowane. Ta kategoria obejmuje wiele modeli konserwacji masowych związanych z uwzględnieniem w kolejce.
2. Dostępne są metody analityczne, ale procedury matematyczne są tak złożone i natężenia pracy, które modelowanie symulacyjne daje prostsze sposoby rozwiązywania problemu.
3. Istnieją rozwiązania analityczne, ale ich realizacja jest niemożliwa ze względu na niewystarczające przygotowanie matematyczne dostępnego personelu. W tym przypadku konieczne jest porównanie kosztów projektowania, testowania i pracy na modelu symulacji kosztów związanych z zaproszeniem specjalistów z części.
4. Oprócz oszacowania niektórych parametrów pożądane jest wdrożenie na modelu symulacji monitorując proces procesowy przez pewien okres.
5. Modelowanie imitacji może być jedyną możliwością spowodowania trudnościami eksperymentów i obserwacji zjawisk w rzeczywistych warunkach (na przykład badanie zachowania statku kosmicznego w warunkach lotów międzyplanetarnych).
6. W przypadku długoterminowych działań systemów lub procesów może być konieczne, aby skompresować osi czasu. Modelowanie imitacja umożliwia w pełni kontrolę czasu badanego procesu, ponieważ zjawisko można spowolnić lub przyspieszyć zgodnie z pożądanym (na przykład problemy badawcze spadku miast).
Dodatkowa zaleta Symulacja może być uznana za najszerszą możliwością jej zastosowania w dziedzinie edukacji i szkoleń. Rozwój i użycie modelu symulacji pozwala eksperymentatorowi zobaczyć i przetestować rzeczywiste procesy i sytuacje na modelu. To z kolei powinni znacznie pomóc zrozumieć i doświadczyć problemu, który stymuluje proces znalezienia innowacji.
Symulacja jest realizowana przez zestaw narzędzi matematycznych, specjalnych programów komputerowych i technik, które umożliwiają korzystanie z komputera do przeprowadzenia ukierunkowanego modelowania w trybie "imitacji" struktury i funkcji kompleksu i optymalizacji niektórych jego parametrów. Zestaw technik oprogramowania i modelowania określa specyfikę systemu symulacji - specjalne oprogramowanie.
Symulacja procesów gospodarczych jest zwykle stosowana w dwóch przypadkach:
1. Aby zarządzać złożonym procesem biznesowym, gdy model symulacyjny zarządzanego obiektu gospodarczego jest wykorzystywany jako narzędzie w obwodzie systemem sterowania adaptacyjnym utworzonym na podstawie technologii informacyjnych;
2. Podczas prowadzenia eksperymentów z dyskretnymi ciągłymi modelach złożonych przedmiotów gospodarczych do uzyskania i "obserwacji" ich dynamiki w sytuacjach nadzwyczajnych związanych z ryzykiem, których naturalne modelowanie jest niepożądane lub niemożliwe.
Modelowanie symulacyjne jako specjalna technologia informacyjna składa się z następujących głównych etapów:
1. Analiza strukturalna procesów . Na tym etapie analiza struktury złożonego realnego procesu i jego rozkładu w prostsze powiązane subproceszy, z których każdy wykonuje określoną funkcję. Zidentyfikowane podprocesy można podzielić na inne prostsze podszycia. Zatem struktura symulowanego procesu może być reprezentowana jako wykres o konstrukcji hierarchicznej.
Analiza strukturalna jest szczególnie skuteczna w modelowaniu procesów gospodarczych, w których wiele składników podprocesów postępuje wizualnie i nie ma podmiotu fizycznego.
2. Sformalizowany opis modelu. . Uzyskany obraz graficzny modelu symulacyjnego, funkcje wykonywane przez każdą podprocesową, warunki interakcji wszystkich podprocesów powinny być opisane w języku specjalnym dla kolejnej transmisji.
Można to zrobić na różne sposoby: aby opisać ręcznie w dowolnym języku lub za pomocą komputera graficznego.
3. Model budowy . Ten etap obejmuje połączenia nadawcze i edytowanie, a także weryfikację parametrów.
4. Prowadzenie ekstremalnego eksperymentu . Na tym etapie użytkownik może uzyskać informacje o tym, jak blisko jest utworzony model naprawdę istniejącego zjawiska i jak najlepszy model nadaje się do badania nowych, jeszcze testowanych wartości argumentów i parametrów systemu.
1.2. Metoda Monte Carlo.
Testy statystyczne Zgodnie z metodą Monte Carlo są najprostszym modelowaniem imitacji z całkowitą brakiem jakichkolwiek zasad postępowania. Uzyskanie próbek zgodnie z metodą Monte Carlo - główną zasadą symulacji komputerowej systemów zawierających elementy stochastyczne lub probabilistyczne. Wytwarzanie metody wiąże się z dziełem Neumananu i Ułana pod koniec lat 40., kiedy wprowadzili dla niego nazwę "Monte Carlo" i zastosował go do rozwiązania niektórych zadań ekranujących emisji jądrowej. Ta metoda matematyczna była znana i wcześniej, ale znalazłem moje drugie narodziny w Los Alamos w zamkniętych dziełach na technologii jądrowej, które zostały przeprowadzone w ramach oznaczenia kodu "Monte Carlo". Korzystanie z metody było tak udane, że został dystrybuowany w innych obszarach, w szczególności w gospodarce.
Dlatego wielu specjalistów termin "Monte Carlo Metoda" czasami wydawała się synonimem terminu "Modelowanie symulacyjne", które jest ogólnie nieprawidłowe. Modelowanie symulacyjne jest szerszym koncepcją, a metoda Monte Carlo jest ważna, ale daleko od jedynego składnika metodologicznego symulacji.
Według metody Monte Carlo, projektant może symulować pracę tysiącom złożonych systemów, które kontrolują tysiące odmian takich procesów i zbadać zachowanie całej grupy, przetwarzając dane statystyczne. Innym sposobem zastosowania tej metody jest symulację zachowania systemu sterowania w bardzo dużym zakresie czasu modelowego (kilku lat), z czasem astronomicznym wykonywania programu symulacyjnego na komputerze może spowodować podział sekund.
Podczas analizowania metody Monte Carlo komputer wykorzystuje procedurę generowania numerów pseudotumantycznych w celu symulacji danych z populacji ogólnej. Procedura analizy metody Monte Carlo buduje próbki z ogólnego zestawu zgodnie z instrukcjami użytkownika, a następnie wykonuje następujące czynności: Imituje losową próbkę z ogólnej populacji, analiza próbki prowadzi analizę i zachowuje wyniki. Po dużej liczbie powtórzeń, zapisane wyniki są dobrze naśladującą prawdziwą dystrybucję próbnych statystyk.
W różnych zadaniach napotkanych podczas tworzenia złożonych systemów, których wartości są określane losowo. Przykładami takich wartości to:
1 przypadkowe chwile czasu, w których zamówienia przychodzą do firmy;
3 oddziaływanie zewnętrzne (wymagania lub zmiany ustawodawstw, płatności dla grzywien itp.);
4 Płatność kredytów bankowych;
5 Odbiór środków od klientów;
6 błędów pomiarowych.
Numer, zestaw liczb, wektor lub funkcji może być używany jako odpowiednie zmienne. Jedną z odmian metody Monte Carlo metody z liczbowym rozwiązaniem zadań, w tym zmiennych losowych, jest metoda testów statystycznych, która ma modelować zdarzenia losowe.
Metoda Monte Carlo opiera się na testach statystycznych, a z natury jest skrajna, może być wykorzystywana do rozwiązania w pełni deterministycznych zadań, takich jak odwołanie macierzy, rozwiązywanie równań różniczkowych w prywatnych instrumentach pochodnych, znalezienia ekstremów i integracji numerycznej. Przy obliczaniu metody Monte Carlo, wyniki statystyczne są uzyskiwane przez powtarzanie testów. Prawdopodobieństwo, że wyniki te różnią się od prawdziwej nie więcej niż dana wartość, jest funkcją liczby testów.
Obliczenia na metodzie Monte Carlo leży losowy wybór liczb z danej dystrybucji probabilistycznej. Dzięki praktycznym obliczeniom numery te są pobierane z tabel lub uzyskuje się przez niektóre operacje, których wyniki są liczbami pseudo-losowymi o tych samych właściwościach, co liczb uzyskane przez próbkę losową. Istnieje duża liczba algorytmów obliczeniowych, które pozwalają nam uzyskać długich sekwencji liczb pseudotrobelkowych.
Jedna z najprostszych i wydajnych metod obliczeniowych do uzyskania sekwencji jednolicie rozpowszechnianych liczb losowych r i, Używanie, na przykład, kalkulator lub jakiekolwiek inne urządzenie działające w systemie liczb dziesiętnego, zawiera tylko jedną operację mnożenia.
Metoda jest następująca: jeśli r i \u003d. 0,0040353607, a następnie R i + 1 \u003d (40353607RI) MOD 1, w którym MOD 1 oznacza działanie ekstrakcji wynikające tylko z części ułamkowej po przecinku. Jak opisano w różnych źródłach literackich, liczba r zaczynam być powtarzany po cyklu 50 milionów numerów, więc r 5OOOOOO1 \u003d R 1. Sekwencja R1 otrzymuje się równomiernie rozmieszczone w przedziale (0, 1).
Zastosowanie metody Monte Carlo może dać znaczący wpływ na modelowanie rozwoju procesów, których obserwacja jednokierunkowa jest niepożądana lub niemożliwa, a inne metody matematyczne w stosunku do tych procesów nie są opracowywane lub niedopuszczalne ze względu na liczne zastrzeżenia i założenia które może prowadzić do poważnych błędów lub nieprawidłowych wniosków. W tym względzie konieczne jest nie tylko przestrzeganie rozwoju procesu w niepożądanych obszarach, ale także ocenianie hipotez na parametrach niechcianych sytuacji, do których prowadzi się taki rozwój, w tym parametry ryzyka.
1.3. Korzystanie z praw dystrybucji zmiennych losowych
W celu oceny wysokiej jakości systemu złożonego jest wygodne wykorzystanie wyników teorii procesów losowych. Doświadczenie w obserwacji obiektów pokazuje, że funkcjonują w warunkach działania dużej liczby czynników losowych. Dlatego przewidywanie zachowania złożonego systemu może mieć sens tylko w kategoriach probabilistycznych. Innymi słowy, jedynie prawdopodobieństwa ich wystąpienia można wskazać na oczekiwane zdarzenia, i w stosunku do niektórych wartości konieczne jest ograniczenie przepisów ich dystrybucji lub innych właściwości prawdopodobieństwowych (na przykład, średnich wartości, dyspersji itp. ).
Aby zbadać proces funkcjonowania każdego konkretnego złożonego systemu, biorąc pod uwagę czynniki losowe, konieczne jest posiadanie dość jasnej idei źródeł losowych wpływów i bardzo wiarygodnych danych na ich cechy ilościowe. Dlatego wszelkie obliczenia lub analizę teoretyczną związaną z badaniem złożonego systemu jest poprzedzony eksperymentalną akumulacją materiału statystycznego charakteryzującego zachowanie poszczególnych elementów i systemu jako całości w rzeczywistych warunkach. Przetwarzanie tego materiału umożliwia uzyskanie danych źródłowych do obliczania i analizy.
Prawo podziału losowej wariancji nazywa się stosunkiem, który pozwala określić prawdopodobieństwo zmiennej losowej w dowolnym przedziale. Może być ustawione tabele, analitycznie (jako formuła) i graficznie.
Istnieje kilka przepisów dotyczących dystrybucji zmiennych losowych.
1.3.1. Jednolita dystrybucja
Ten rodzaj dystrybucji służy do uzyskania bardziej złożonych rozkładów, zarówno dyskretnych, jak i ciągłych. Takie rozkłady uzyskuje się przy użyciu dwóch głównych technik:
a) funkcje odwrotne;
b) łączenie wartości dystrybuowanych przez inne prawa.
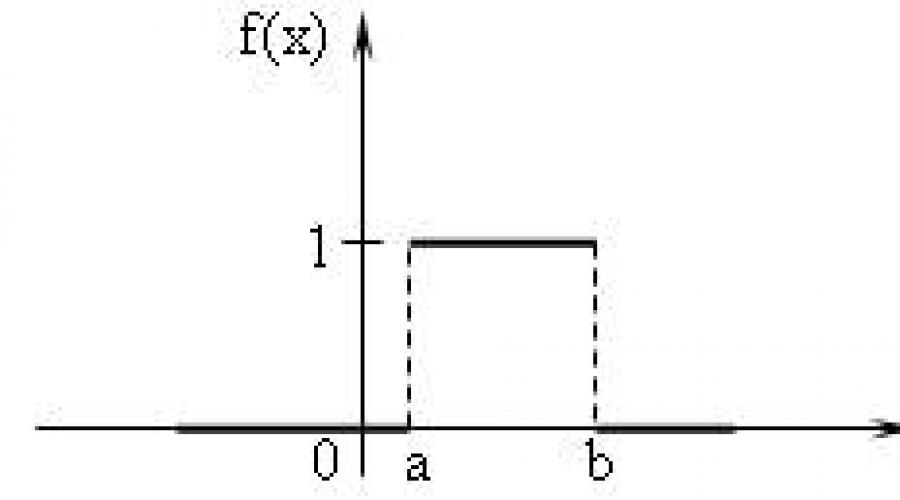
Jednolite prawo - prawo rozkładu zmiennych losowych o symetrycznym wyglądzie (prostokąt). Gęstość jednolitej dystrybucji podaje formułę:
te. W przedziale, do którego należą wszystkie możliwe wartości zmiennej losowej, gęstość oszczędza stałą wartość (rys. 1).

Fig.1 Funkcja gęstości prawdopodobieństwa i charakterystyki jednolitej dystrybucji
W modelach imitacja procesów ekonomicznych, jednolity dystrybucja jest czasami używany do symulacji prostego (jednorazowego) pracy, przy obliczaniu harmonogramów sieci pracy, w pracy wojskowej - aby modelować czas przejścia przez podziały, czas kopania okopy i budowa struktur fortyfikacji.
Jednolita dystrybucja jest używana, gdyby tylko fakt, że mają maksymalne rozprzestrzenianie się, wiadomo o odstępach czasu i nic nie wiadomo o dystrybucjach prawdopodobieństwa tych odstępówek.
1.3.2. Dyskretna dystrybucja
Dyskretna dystrybucja jest prezentowana przez dwa prawa:
1) binomina, w której prawdopodobieństwo zdarzenia w kilku niezależnych testach jest określona przez formułę Bernoulliego:
n - liczba niezależnych testów
m to liczba zdarzeń w testach n.
2) Dystrybucja Poissona, gdzie z dużą liczbą testów prawdopodobieństwo wystąpienia zdarzenia jest bardzo małe i jest określona przez wzór:
k - liczba zdarzeń w kilku niezależnych testach
Średnia liczba zdarzeń w kilku niezależnych testach.
1.3.3. Normalna dystrybucja
Dystrybucja normalna lub Gaussa jest niewątpliwie jednym z najważniejszych i często używanych rodzajów ciągłych dystrybucji. Jest symetrycznie w stosunku do oczekiwań matematycznych.
Ciągła ilość losowa t. ma normalny dystrybucję prawdopodobieństwa z parametrami t. i > O Jeśli jego gęstość prawdopodobieństwa jest powiązana (rys. 2, rys.3):

gdzie t. - wartość oczekiwana M [t];
Rys. 2, Rys. 3. Funkcja gęstości prawdopodobieństwa i charakterystyki dystrybucji normalnej
Wszelkie złożone prace w obiektach gospodarki składają się z wielu krótkich kolejnych elementów podstawowych. Dlatego w szacunkach koszty pracy zawsze sugeruje, że ich czas trwania jest losową odmianą rozproszoną zgodnie z normalnym prawem.
W modelach procesów ekonomicznych stosuje się prawo rozkładu normalnego do symulacji złożonych prac wielokierunkowych.
1.3.4. Dystrybucja wykładnicza
Zajmuje także bardzo ważne miejsce podczas prowadzenia ogólnoustrojowej analizy działalności gospodarczej. Niniejsze prawo dystrybucyjne podlega wielu zjawiskom, na przykład:
1 czas otrzymania zamówienia dla przedsiębiorstwa;
2 wizyty w kupujących sklepu supermarketu;
3 rozmowy telefoniczne;
4 Lifetime części i węzłów w zainstalowanym komputerze, na przykład w rachunkowości.
Funkcja dystrybucji wykładniczej jest następująca:
F (x) \u003d At \u200b\u200b0 Parametr dystrybucji wykładniczej,\u003e 0. Dystrybucja wykładnicza to specjalne przypadki rozkładu gamma. Figa. 5 Funkcja gęstości prawdopodobieństwa rozkładu gamma W modelach procesów ekonomicznych, dystrybucja wykładnicza służy do symulacji interwałów zamówień wchodzących do firmy z licznych klientów. W teorii niezawodności służy do symulacji przedziału czasu między dwiema kolejnymi błędami. W przyłączeniu i naukach komputerowych - do przepływów informacyjnych modelowania. 1.3.5. Uogólniono dystrybucja Erland P (t) \u003d w t≥0; Gdzie K-elementarne składniki kolejne rozprowadzane przez prawo wykładnicze. Uogólnione dystrybucja Erlandia jest stosowana w tworzeniu modeli matematycznych i imitacyjnych. Rozkład ten jest dogodnie używany zamiast normalnego rozkładu, jeśli model jest zredukowany do zadania czysto matematycznego. Ponadto w prawdziwym życiu występuje obiektywne prawdopodobieństwo grup aplikacji jako reakcji na niektóre działania, dlatego występują wątki grupy. Zastosowanie czysto matematycznych metod badań w modelach efektów z takich przepływów grupy jest niemożliwe ze względu na brak sposobu uzyskania wyrażenia analitycznego lub trudne, ponieważ wyrażenia analityczne zawierają duży błąd systematyczny ze względu na liczne założenia, dzięki który badacz był w stanie otrzymać te wyrażenia. Opisać jedną z odmian strumienia grupy, możesz zastosować uogólnioną dystrybucję Erland. Pojawienie się przepływów grupowych w złożonych systemach gospodarczych prowadzi do gwałtownego wzrostu średnich czasów różnych opóźnień (zamówienia w kolejce, opóźnienia w płatnościach itp.), A także wzrost prawdopodobieństw ryzykownych zdarzeń lub zdarzeń ubezpieczonych. 1.3.6. Trójkątna dystrybucja Dystrybucja trójkątna jest bardziej informacyjna niż mundur. W tym dystrybucji określono trzy wartości - minimum, maksimum i moda. Wykres funkcji gęstości składa się z dwóch segmentów bezpośrednich, z których jeden wzrasta podczas zmiany X. Z minimalnej wartości do mody, a drugi zmniejsza się podczas zmiany X. z wartości mody do maksimum. Wartość oczekiwań matematycznych dystrybucji trójkątnej jest równa jednej trzeciej sumy minimalnej, maksymalnej i maksimum. Dystrybucja trójkątna jest używana, gdy najbardziej prawdopodobna wartość jest znana w pewnym przedziale i zakłada się, że jest fragmentarycznym liniowym charakterem funkcji gęstości. Rys.5 Funkcja gęstości prawdopodobieństwa i trójkątna charakterystyka dystrybucji. Dystrybucja trójkątna jest łatwa do zastosowania i interpretacji, ale jest to konieczne do wyboru na ciężkie tereny. W modelach procesów ekonomicznych, taki dystrybucja jest czasami używana do symulacji czasu dostępu do baz danych. 1.4. Planowanie eksperymentu komputerowego symulacji Model symulacyjny jest niezależny od wybranego systemu modelowania (na przykład pielgrzym lub GPS) pozwala uzyskać pierwsze pierwsze punkty i informacje na temat prawa dystrybucji dowolnej wielkości eksperymentatora, który jest zainteresowany (eksperymentator jest przedmiotem To wymaga wniosków jakościowych i ilościowych dotyczących charakterystyki procesu w badaniu). 1.4.1. Cyber \u200b\u200bpodejście do organizowania badań eksperymentalnych złożonych przedmiotów i procesów. Planowanie eksperymentów można uznać za podejście cybernetyczne do organizacji i prowadzenia badań eksperymentalnych złożonych przedmiotów i procesów. Główną ideą sposobu składa się z możliwości optymalnej kontroli eksperymentu w warunkach niepewności, co jest znane tymi warunkami, na których opiera się cybernetyka. Celem większości prac badawczych jest określenie optymalnych parametrów złożonego systemu lub optymalnych warunków dla procesu przetwarzania: 1. Określanie parametrów projektu inwestycyjnego w warunkach niepewności i ryzyka; 2. Wybór parametrów strukturalnych i elektrycznych instalacji fizycznej, zapewniając najbardziej opłacalny tryb swojej operacji; 3. Uzyskanie najwyższej możliwej reakcji reakcji, zmieniając temperaturę, ciśnienie i stosunek odczynników - w zadaniach chemii; 4. Wybór elementów stopowych do uzyskania stopu z maksymalną wartością dowolnej cechy (lepkość, odporność na szczelinę itp.) - w metalurgii. Podczas rozwiązywania tego rodzaju problemów konieczne jest uwzględnienie wpływu dużej liczby czynników, z których niektóre nie są podatne na regulację i kontrolę, co jest niezwykle trudne do uzupełnienia teoretycznych badań problemu. Dlatego idą ścieżkę nawiązywania podstawowych wzorów poprzez serię eksperymentów. Badacz był w stanie wyrazić wyniki eksperymentu w wygodnym do analizy i użytkowania. 1.4.2. Eksperyment analizy regresji i modelowania modelowania Rys.7 Przykład uśredniania wyników eksperymentalnych Wartości rozproszenia η V. W tym przypadku nie tylko błędy pomiarowe, a głównie efekt zakłóceń z jot. . Złożoność optymalnego problemu sterowania charakteryzuje się nie tylko złożonością samej zależności η v (V \u003d 1, 2, ..., n) ale także wpływ z jot. Co sprawia, że \u200b\u200belement szansa w eksperymencie. Uzależnienie od wykresu η v (x I) Określa wartości połączenia korelacji η V. i x I. które można uzyskać zgodnie z wynikami eksperymentu przy użyciu matematycznych metod statystyk. Obliczanie takich zależności z dużą liczbą parametrów wejściowych x I. i znaczące zakłócenia z jot. I jest głównym zadaniem badacza eksperymentatora. Jednocześnie trudniejsze zadanie, tym bardziej skuteczne wykorzystanie metod planowania eksperymentu. Wyróżnij dwa typy eksperymentów: Bierny; Aktywny. Dla pasywny eksperyment Badacz prowadzi tylko do monitorowania procesu (zmieniając parametry wejściowe i wyjściowe). Zgodnie z wynikami obserwacji stwierdza się, że zawarte są parametry wejściowe w weekend. Pasywny eksperyment jest zwykle wykonywany na podstawie istniejącego procesu gospodarczego lub produkcyjnego, który nie pozwala na aktywną interwencję eksperymentatora. Ta metoda jest mała kosztowna, ale wymaga dużo czasu. Aktywny eksperyment. Jest przeprowadzany głównie w warunkach laboratoryjnych, gdzie eksperymentator ma możliwość zmiany właściwości wejściowych zgodnie z ustalonym planem. Taki eksperyment szybszy prowadzi do celu. Odpowiednie metody przybliżeń zostały nazwane analizą regresji. Analiza regresji Jest to narzędzie metodologiczne podczas rozwiązywania problemów prognozowania, planowania i analizowania działalności gospodarczej przedsiębiorstw. Zadania analizy regresji są ustanowienie formy relacji między zmiennymi, oceną funkcji regresji i ustanowienia wpływu czynników na zmienną zależną, ocenę nieznanych wartości (prognoza wartości) zmiennej zależnej. 1.4.3. Ortogonalne planowanie drugiego rzędu. Planowanie ortogonalne eksperymentu (w porównaniu z niejednorodem) zmniejsza liczbę eksperymentów i znacznie upraszcza obliczenia po otrzymaniu równania regresji. Jednak takie planowanie jest możliwe tylko z możliwością przeprowadzenia aktywnego eksperymentu. Praktyczne środki znalezienia ekstremum jest eksperymentem czynnikiem. Główne zalety eksperymentu czynnika - prostota i możliwość znalezienia skrajnego punktu (z pewnym błędem), jeśli nieznana powierzchnia jest wystarczająco płynna i nie ma lokalnych skrajności. Należy zauważyć dwa główne wady eksperymentu czynnika. Pierwsza jest niemożność znalezienia ekstremum w obecności nieznanych powierzchni krokowych i lokalnych ekstremów. Drugi jest w przypadku braku sposobów opisywania charakteru powierzchni w pobliżu skrajnego punktu ze względu na wykorzystanie najprostszych równania regresji liniowej, co wpływa na bezwładność systemu sterowania, ponieważ w procesie zarządzania konieczne jest prowadzenie czynnika Eksperymenty, aby wybrać efekty kontroli. Do celów zarządzania planowanie ortogonalne drugiego rzędu jest najbardziej odpowiednie. Zazwyczaj eksperyment składa się z dwóch etapów. Najpierw, używając eksperymentu czynnika, obszar, w którym istnieje punkt ekstremalny. Następnie, w obszarze istnienia skrajnego punktu przeprowadzany jest eksperyment w celu uzyskania równania regresji drugiego rzędu. Równanie regresji drugiego rzędu umożliwia natychmiastowe określenie wpływów kontroli bez dodatkowych eksperymentów lub eksperymentów. Dodatkowy eksperyment będzie wymagany tylko w przypadkach, gdy powierzchnia odpowiedzi znacznie zmieni się pod wpływem niekontrolowanych czynników zewnętrznych (na przykład znacząca zmiana polityki podatkowej w kraju poważnie wpłynie na powierzchnię odpowiedzi odzwierciedlającą koszty produkcji przedsiębiorstwo 2. Praktyczna praca. W tej sekcji będziemy spojrzeć na to, w jaki sposób możesz zastosować teoretyczną wiedzę do konkretnych sytuacji gospodarczych. Głównym zadaniem naszego kursu jest określenie skuteczności przedsiębiorstwa zaangażowanego w działalność handlową. Aby wdrożyć projekt, wybraliśmy pakiet pielgrzymów. Pakiet Pielgrzymia ma szeroką gamę możliwości symulujących dynamikę tymczasową, przestrzenną i finansową symulowanych obiektów. Dzięki nim możesz tworzyć modele dyskretne ciągłe. Modele opracowane mają własność procesu zarządzania zbiorowego modelowania. W tekście modelu można wstawić dowolne bloki za pomocą standardowego języka C ++. Pakiet Pielgrzym ma własność mobilności, tj. Przenieś do każdej innej platformy w obecności kompilatora C ++. Modele w systemie pielgrzyma są skompilowane i dlatego mają dużą prędkość, co jest bardzo ważne, co jest bardzo ważne dla opracowania rozwiązań do zarządzania i adaptacyjnego wyboru opcji w skali czasowej ultrawy. Kod obiektu odebrany po kompilacji może być osadzony w opracowywanych programach lub przesyłaniu (sprzedawać) do Klienta, ponieważ podczas operacyjnych modeli opakowania narzędzi pakiet pielgrzymowy nie są używane. Piąta wersja pielgrzyma jest produktem oprogramowania utworzonym w 2000 r. Na zasadzie obiektów i biorąc pod uwagę główne pozytywne właściwości poprzednich wersji. Zalety tego systemu: Orientacja na wspólne modelowanie materiałów, informacji i procesów "gotówkowych"; Obecność rozwiniętej skorupy, która umożliwia budowę wielu modeli wielopoziomowych w trybie analizy systemu strukturalnego; Dostępność interfejsów z bazami danych; Możliwość dostępu do modeli użytkowników końcowych bezpośrednio analizuje wyniki dzięki sformalizowanemu technologii do tworzenia funkcjonalnego monitorowania modelu za pomocą Visual C ++, Delphi lub innych środków; Możliwość sterowania modeli bezpośrednio podczas ich wykonania przy użyciu specjalnych okien dialogu. Tak więc pakiet pielgrzymowy jest dobrym sposobem tworzenia zarówno modeli dyskretnych, jak i ciągłych, ma wiele zalet i znacznie upraszcza tworzenie modelu. Przedmiotem obserwacji jest przedsiębiorstwo zajmujące się wdrażaniem wytwarzanych towarów. W przypadku analizy statystycznej tych funkcjonowania przedsiębiorstwa i porównywanie uzyskanych wyników, porównano wszystkie czynniki wpływające na proces wydawania i sprzedaży towarów. Firma zajmuje się produkcją towarów w małych partiach (znana jest rozmiar tej partii). Jest rynek, w którym sprzedawany jest ten produkt. Rozmiar partii zakupionych towarów w ogólnym przypadku jest wartością losową. Schemat strukturalny procesu biznesowego zawiera trzy warstwy. Na dwóch warstwach istnieją autonomiczne procesy "produkcja" (dodatek A) i "sprzedaż" (Załącznik B), których programy są niezależne od siebie. Brak ścieżek do transakcji transakcji. Interakcja za pośrednictwem tych procesów jest przeprowadzana tylko poprzez zasoby: zasoby materialne (w postaci produktów gotowych) i zasobów pieniężnych (głównie za pośrednictwem rachunku bieżącego). Zarządzanie zasobami pieniężnymi występuje na oddzielnej warstwie - w procesie "Operacje monetarne" (Załącznik B). Przedstawiamy funkcję docelową: Czas opóźnienia płatności z konta bieżącego TRS. Główne parametry zarządzające: 1 produkty jednostkowe ceny; 2 objętość wyprodukowanego towaru; 3 Kwota pożyczki wymagała w banku. Naprawianie wszystkich innych parametrów: 4 godziny uwolnienia strony; 5 Liczba linii produkcyjnych; 6 Odstęp odstępu zamówienia od kupujących; 7 Rozpraszanie wielkości sprzedanej partii; 8 kosztów komponentów i materiałów do uwolnienia strony; 9 kapitału startowego na rachunku bieżącym; możesz zminimalizować TRS dla określonej sytuacji rynkowej. Minimum TRS osiąga się z jedną z maksimów kwoty pieniędzy na rachunku bieżącym. Ponadto prawdopodobieństwo zdarzenia ryzyka - brak wypłaty długów na kredyty są blisko minimum (można to udowodnić podczas eksperymentu statystycznego z modelu). Pierwszy proces " Produkcja "(Dodatek A) implementuje główne procesy podstawowe. Knot 1 naśladuje otrzymywanie zamówień na produkcję partii produktów z zarządzania spółki. Węzeł 2 - próba uzyskania pożyczki. W tym węźle pojawia się transakcja pomocnicza - żądanie do banku. Knot 3 - Czekam na pożyczkę na ten wniosek. Węzeł 4 jest administracją bankową: Jeśli poprzednia pożyczka zostanie zwrócona, to nowy (w przeciwnym razie żądanie czeka w kolejce). Węzeł 5 przenosi pożyczkę na konto bieżące firmy. W węźle 6, wniosek pomocniczy jest zniszczony, ale dostarczane są pożyczki, to "bariera" na ścieżce następnego wniosku o kolejną pożyczkę (Hold Operation). Główna usuwanie transakcji przechodzi przez węzeł 2 bezzwłocznie. W węźle 7 składniki są wypłacane, jeśli istnieje wystarczająca ilość na rachunku bieżącym (nawet jeśli pożyczka nie zostanie odebrana). W przeciwnym razie istnieje oczekiwanie z pożyczki lub wypłaty sprzedanych produktów. W węźle 8 transakcja staje się kolejkowana, jeśli zajmują wszystkie linie produkcyjne. W węźle 9 przeprowadza się wytwarzanie partii produktów. W węźle 10 istnieje dodatkowa aplikacja do zwrotu pożyczki, jeśli pożyczka została wcześniej podświetlona. Ta aplikacja wprowadza węzeł 11, w którym pieniądze są przekazywane z rachunku bieżącego Spółki do Banku; Jeśli nie ma pieniędzy, aplikacja oczekuje. Po zwróceniu pożyczki, ta aplikacja zostanie zniszczona (w węźle 12); Bank ma informacje, które pożyczka jest zwracana, a firma może zostać wydana następująca pożyczka (operację rozsądną). Zlecenie transakcji przechodzi węzeł 10 bez opóźnienia, aw węzła 13 jest zniszczony. Następnie uważa się, że impreza jest wykonana i weszła do magazynu gotowych produktów. Drugi proces " Sprzedaż "(Załącznik b) naśladuje podstawowe funkcje sprzedaży produktów. Węzeł 14 jest generatorem nabywców produktów. Transakcje te zwracają się do magazynu (węzeł 15), a jeśli istnieje żądana ilość towarów, towary są uwalniane przez kupującego; W przeciwnym razie kupujący czeka. Węzeł 16 imituje wakacje towarów i kontroli kolejki. Po otrzymaniu towarów kupujący wymieniono pieniądze na konto bieżące firmy (węzeł 17). W węźle 18, kupujący jest uważany za serwisowany; Odpowiednia transakcja nie jest już potrzebna i zniszczona. Trzeci proces " Operacje monetarne. "(Załącznik b) naśladuje okablowanie w rachunkowości. Wnioski o okablowanie pochodzą z pierwszej warstwy z węzłów 5, 7, 11 (proces "produkcja") i z węzła 17 (proces "sprzedaży"). Linie przerywane pokazują przepływ kwot pieniężnych na koncie 51 ("Konto rozliczeniowe", Węzeł 20), Konto 60 ("Dostawcy, Wykonawcy", Węzeł 22), Konto 62 ("Kupujący, Klienci", Węzeł 21) i Konto 90 ("Bank", węzeł 19). Konwencjonalne liczby w przybliżeniu odpowiadają planowi rachunkowości. Węzeł 23 naśladuje pracę dyrektora finansowego. Serwowane transakcje po księgowościach wracają do tych węzłów, skąd je; Węzły te znajdują się w parametrze transakcji T → Updrackon. Kod źródłowy modelu jest przedstawiony w aplikacji. Ten kod źródłowy buduje sam model, tj. Tworzy wszystkie węzły (prezentowane w strukturalnym schemacie procesu biznesowego) i związek między nimi. Kod można wygenerować przez Designer Pilgrim (GEM), w którym zbudowane są procesy w formularzu obiektu (dodatek E). Model jest tworzony przy użyciu Microsoft Developer Studio. Microsoft Developer Studio to pakiet oprogramowania oparty na języku C ++. Po dołączeniu do projektu dodatkowych bibliotek (Pilgrim.lib, COMCCL32.LIB) i pliki zasobów (Pilgrim.res), skompilować ten model. Po kompilacji otrzymujemy gotowy model. Plik raportu jest automatycznie tworzony, w którym wyniki modelowania uzyskane po uruchomieniu jednego modelu są przechowywane. Plik raportu jest przedstawiony w Załączniku D. 3. Wnioski dotyczące modelu biznesowego "Efektywność produkcji" 1) Numer węzła; 2) Nazwa węzła; 3) Rodzaj węzła; 5) m (t) średni czas oczekiwania; 6) Miernik wejściowy; 7) pozostaje transakcja; 8) stan węzła w tym momencie. Model składa się z trzech niezależnych procesów: główny proces produkcyjny (Załącznik A), proces sprzedaży produktów (Załącznik B) oraz proces zarządzania przepływami pieniężnymi (aplikacja b). Główny proces produkcji.
W okresie modelowania procesu biznesowego w węźle 1 utworzono ("Zamówienia") utworzono 10 wniosków o wytwarzanie produktów. W wyniku tego, że średni czas tworzenia zamówienia wynosi 74 dni, w wyniku czego jedna transakcja nie weszła do ram procesu modelowania. Pozostałe 9 transakcji wszedł do węzła 2 ("Development1"), gdzie utworzono odpowiednią liczbę wniosków do banku, aby otrzymać pożyczkę. Średni czas oczekiwania wynosi 19 dni, ten czas modelowania, dla którego spełnione były wszystkie transakcje. Ponadto widać, że 8 wniosków otrzymało pozytywną odpowiedź w Węzeł 3 (Emisja rozdzielczości "). Średnia pozwolenie na czas wynosi 65 dni. Ładowanie tego węzła wynosiło średnio 70,4%. Stan węzła w momencie zakończenia czasu symulacji jest zamknięty, wynika to z faktu, że ten węzeł zapewnia nową pożyczkę tylko w przypadku powrotu poprzedniego, zatem pożyczki w tym czasie Koniec modelowania nie został spłacony (widać to z węzła 11). Węzeł 5 przenosi pożyczkę do rachunku bieżącego przedsiębiorstwa. I, jak widać z tabeli wyników, bank przeniesiony na konto Spółki 135 000 rubli. W węźle 6 wszystkie 11 wniosków o kredyt zostały zniszczone. W węźle 7 ("Opłata dostawcy") została wpłacona na składniki w wysokości uzyskanej wcześniej pożyczki (135 000 rubli). W węźle 8 widzimy, że 9 transakcji jest w kolejce. Dzieje się tak, gdy wszystkie linie produkcyjne są zajęte. W węźle 9 ("Zamówienie") przeprowadza się bezpośrednio do produkcji. Do produkcji jednej partii produktów trwa 74 dni. W okresie modelowania wykonano 9 zamówień. Ładowanie tego węzła wynosiło 40%. W węźle 13 zastosowania do produkcji produktów zostały zniszczone w ilości 8 szt. Przy obliczeniu, które strony są wykonane i wprowadzane do magazynu. Średni czas produkcji wynosi 78 dni. W węźle 10 ("Fork 2") powstało 0 dodatkowych zwrotu kredytów. Wnioski te zostały zapisane do węzła 11 ("powrót"), gdzie bank zwrócił pożyczkę w wysokości 120 000 rubli. Po zwróceniu pożyczki aplikacja zwrotna została zniszczona w węźle 12 w wysokości 7 szt. ze średnim czasem -37 dni. Proces sprzedaży produktów.
W węźle 14 ("Klienci") wygenerowano 26 kupujących transakcji produktów o średnio 28 dni. Jedna transakcja oczekuje. Następnie, 25 transakcji nabywców "odwrócił się" do magazynu (węzła 15) dla towarów. Ładowanie magazynu do okresu modelowania wynosił 4,7%. Produkty z magazynu zostały wydane natychmiast - bez opóźnień. W wyniku emisji produktów, 1077 jednostek pozostały w magazynie. Produkty, w linii, uzyskiwanie towarów nie są oczekiwane zatem, otrzymując zamówienie, firma może wydać pożądaną ilość towarów bezpośrednio z magazynu. Węzeł 16 Imituje wydanie produktów 25 klientów (1 transakcja w linii). Po otrzymaniu towarów, klienci bezzwłocznie zapłacili towary otrzymane w wysokości 119160 rubli. W węźle 18 wszystkie serwowane transakcje zostały zniszczone. Proces zarządzania przepływem pieniężnym.
W tym procesie mamy do czynienia z następującym okablowaniem rachunkowym (wnioski o wykonanie, które pochodzą odpowiednio z węzłów 5, 7, 11 i 17, odpowiednio): 1 wydany bank kredytowy - 135000 rubli; 2 Płatność dla dostawców do akcesoriów - 135000 rubli; 3 Zwrot kredytu bankowego - 120000 rubli; 4 Na rachunku bieżącym otrzymał środki ze sprzedaży produktów - 119160 rubli. W wyniku tych okablowania otrzymaliśmy następujące dane dotyczące dystrybucji środków na rachunkach: 1) Sch. 90: Bank. 9 transakcji były obsługiwane, oczekuje się w kolejce. Saldo wynosi 9970000 rubli. Wymagane - 0 rubli. 2) SCH. 51: P / Konta. Serwowane są 17 transakcji, oczekuje się w kolejce. Równowaga funduszy -14260 RUB. Wymagany - 15 000 rubli. W konsekwencji, gdy czas modelowania jest przedłużony, transakcja w kolejce jest natychmiast obsługiwana, ze względu na brak środków na rachunek Spółki. 3) Sch. 61: Klienci. 25 Serwowane transakcje. Rest Rest Balance - 9880840 RUB. Wymagane - 0 rubli. 4) SCH. 60: Dostawcy. 0 podawane transakcje (proces "dostaw towarów" nie został uwzględniony w ramach tego eksperymentu). Saldo wynosi 135 000 rubli. Wymagane - 0 rubli. Węzeł 23 naśladuje pracę dyrektora finansowego. Byli obsługiwani 50 transakcji Analiza harmonogramu "Dynamika opóźnień".
W wyniku trybu modelu, oprócz pliku zawierającego informacje o tabeli, otrzymujemy wykres opóźnień w kolejce (rys. 9). Zaplanuj dynamikę opóźnień w kolejce w węźle "Calc. Konto 51 wskazuje, że opóźnienie wzrasta z czasem. Czas opóźnienia płatności z rachunku bieżącego przedsiębiorstwa jest ≈ 18 dni. To raczej wysoki wskaźnik. W rezultacie przedsiębiorstwo jest coraz mniejsze płatności, a wkrótce czas opóźnienia przekroczy czas oczekiwania wierzyciela - może to prowadzić do bankructwa przedsiębiorstwa. Ale na szczęście te opóźnienia nie są częste, a zatem jest to plus do tego modelu. Możesz rozwiązać sytuację, minimalizując czas opóźnienia płatności za określoną sytuację rynkową. Minimalny czas opóźnienia zostanie osiągnięty w jednej z maksymalnych ilości pieniędzy na rachunku bieżącym. W tym przypadku prawdopodobieństwo braku wypłaty długów o pożyczkach będzie blisko minimum. Ocena wydajności modelu.
Na podstawie opisu procesów możemy stwierdzić, że procesy produkcji i sprzedaży w ogólnej pracy skutecznie. Głównym problemem modelu jest proces zarządzania przepływem monetarnym. Głównym problemem tego procesu jest długi związane z spłatą kredytu bankowego, powodując tym samym brak funduszy na rachunku bieżącym, co nie pozwoli swobodnie manipulować przez otrzymane środki Muszą zostać wysłane, aby spłacić pożyczkę. Ponieważ staliśmy się znani z analizy harmonogramu "Dynamika opóźnień", w przyszłości firma będzie mogła spłacić konta płatne w czasie, ale nie zawsze w wyraźnie określonych liniach Dlatego można stwierdzić, że w tej chwili model jest dość skuteczny, ale wymaga najmniejszego wyrafinowania. Uogólnienie wyników informacji statystycznych przeprowadzono poprzez analizę wyników eksperymentu. Harmonogram opóźnień w węźle "Konto rozliczeniowe" pokazuje, że przez cały okres modelowania, czas opóźnienia w węźle trwa, głównie na tym samym poziomie, chociaż czasami pojawia się opóźnienia. Wynika z tego, że wzrost prawdopodobieństwa pojawienia się sytuacji, gdy przedsiębiorstwo może być na skraju bankructwa, niezwykle niskie. W związku z tym model jest dość akceptowalny, ale jak wspomniano powyżej, wymaga drobnych ulepszeń. Wniosek Skomplikowane stosunki wewnętrzne i duże w liczbie elementów systemu są opłacalne, bezpośrednie metody modelowania i często do budowania i badania są przesyłane do metod symulacyjnych. Pojawienie się najnowszych technologii informacyjnych zwiększa nie tylko możliwości systemów modelowania, ale pozwala również zastosować większą różnorodność modeli i metod ich wdrażania. Poprawa technik obliczeniowych i telekomunikacyjnych doprowadziła do rozwoju metod modelowania maszyn, bez których niemożliwe jest studiowanie procesów i zjawisk, a także budowy dużych i złożonych systemów. Na podstawie wykonanej pracy można powiedzieć, że wartość modelowania w gospodarce jest bardzo duża. Dlatego współczesny ekonomista powinien być dobry w metodach gospodarczych i matematycznych, aby móc praktycznie stosować je do modeli rzeczywistych sytuacji gospodarczych. Pozwala to lepiej przyswoić teoretyczne zagadnienia współczesnej gospodarki, przyczynia się do podniesienia poziomu kwalifikacji i ogólnej kultury zawodowej specjalisty. Za pomocą różnych modeli biznesowych możliwe jest opisanie obiektów gospodarczych, wzorów, komunikacji i procesów nie tylko na poziomie oddzielnej firmy, ale także na poziomie państwa. I jest to bardzo ważny fakt dla każdego kraju: możesz przewidzieć wspinaczki i naklejki, kryzysy i stolce w gospodarce. BIBLIOGRAFIA 1. EMELEANOV A.A., VLASOVA E.A. Modelowanie komputerowe - m.: Moskwa stan. Uniwersytet Ekonomiczny, Statystyki i Informatyki, 2002. 2. Zamkov O.O., Tolstopyenko A.v., Cheremnykh Yu.n. Metody matematyczne w ekonomii, M., Biznes i obsługa, 2001. 3. Koleev V.a., Matematyczna Ekonomia, M., Uniti, 1998. 4. Eksperymenty Naulor T. Imitacja maszyny z modeli systemów gospodarczych. - m.: Mir, 1975. - 392 p. 5. Sowieci B.ya., Yakovlev S.a. Symulacja systemów. - m.: Wyższy. Shk., 2001. 6. Shannon R.e. Modelowanie systemu symulacji: nauka i sztuka. - M.: Mir, 1978. 7. www.thrusta.narod.ru. Załącznik A. Schemat modelu biznesu "Efektywność przedsiębiorstwa" Załącznik B. Proces wdrażania produktów modelu biznesu "Efektywność przedsiębiorstwa" Załącznik B. Proces zarządzania przepływami pieniężnymi modelu biznesu "Efektywność przedsiębiorstwa" Dodatek G. Model kodu źródłowego Dodatek D. Plik raportu modelu. Dodatek E. Studenci, studiach studentów, młodych naukowców, którzy korzystają z bazy wiedzy w swoich badaniach i pracach, będą ci bardzo wdzięczni. University of International Business. Na ten temat: Imitacja modelowania w gospodarce Wykonywany student c. Gospodarka Tazbaonaev Ermek. Almaty 2009. Plan Wprowadzenie 1. Definicja koncepcji "modelowania imitacji" 2. Imitacja modelowania procesów reprodukcyjnych w przemyśle naftowym i gazowym 3. Metoda Monte Carlo jako rodzaj modelowania imitacji 4. Przykład. Ocena zapasów geologicznych Wniosek Wprowadzenie Badanie operacji jest szeroko stosowany zarówno modele analityczne, jak i statystyczne. Każdy z tych typów ma swoje zalety i wady. Modele analitycznych bardziej niegrzecznych, biorąc pod uwagę mniejszą liczbę czynników, zawsze wymagają żadnych założeń i uproszczeń. Ale wyniki obliczeń na nich są łatwiej przewidywalne, wyraźniej odzwierciedlają nieodłączne zjawisko. I główne rzeczy, modele analityczne są bardziej dostosowane do znalezienia optymalnych rozwiązań. Modele statystyczne, w porównaniu z analitycznymi, bardziej dokładnymi i szczegółowymi, nie wymagają tak grubozowych założeń, umożliwiają rozważenie dużej (w teorii - nieograniczonej dużej) liczbie czynników. Ale mają też własne niedociągnięcia: masy, słabe zaburzenia, wysoki zużycie czasu maszyn, a co najważniejsze, skrajna trudność znalezienia optymalnych rozwiązań, które spadają "do dotyku", zgadując i próbki. Najlepszą pracą w dziedzinie operacji opiera się na wymianie modeli analitycznych i statystycznych. Model analityczny umożliwia ogólne warunki, aby wymyślić zjawisko, zakwestionowanie konturu głównych wzorców. Wszelkie wyjaśnienia można uzyskać za pomocą modeli statystycznych. Symulacja symulacyjna dotyczy procesów, w trakcie przebiegu może interweniować ludzką wolę od czasu do czasu. Osoba, która prowadzi działanie może, w zależności od ustalonej sytuacji, przyjmować te lub inne decyzje, podobnie jak szachy, patrząc na planszę, wybiera następny ruch. Następnie model matematyczny jest napędzany, który pokazuje, oczekuje się, jak oczekuje się sytuacji w odpowiedzi na niniejszą decyzję i do których konsekwencje doprowadzi się po pewnym czasie. Poniższe "obecne rozwiązanie" jest akceptowane już biorąc pod uwagę prawdziwą nową sytuację itp. W wyniku powtarzającego się powtarzania takiej procedury, głowa, jak to było, "zyskuje doświadczenie", studiuje błędy własne i inne błędy i stopniowo nauczyć się tworzyć odpowiednie rozwiązania - jeśli nie optymalne, a następnie prawie optymalne. 1.
Określenie koncepcji "modelowania imitacji" W nowoczesnej literaturze nie ma jednego punktu widzenia na pytanie, co rozumieć pod modelowaniem imitacji. Więc są różne interpretacje: W pierwszej - w ramach modelu symulacyjnego jest rozumiany jako model matematyczny w sensie klasycznym; W drugim - termin ten pozostaje tylko dla tych modeli, w których w taki czy inny sposób rozgrywane są losowe skutki (naśladowane); W trzecie, zakłada się, że model symulacyjny różni się od konwencjonalnego bardziej szczegółowego opisu matematycznego, ale kryterium, dla którego można powiedzieć, gdy model Model matematyczny i imitacji nie zostaną wprowadzone; Modelowanie symulacyjne jest stosowane do procesów, w trakcie, w którym może interweniować ludzką wolę od czasu do czasu. Osoba, która prowadzi działanie może, w zależności od ustalonej sytuacji, podejmuj pewne decyzje, podobnie jak szachowiec patrząc na planszy, wybiera następny ruch. Wtedy pracuje model matematyczny, który pokazuje, że sytuacja jest oczekiwana, w odpowiedzi na niniejszą decyzję i do jakich konsekwencji doprowadzi on po pewnym czasie. Kolejna obecna decyzja jest już wykonana już z uwzględnieniem prawdziwego nowego środowiska itp. W wyniku wielokrotnego powtórzenia takiej procedury, głowa tak jak była, "zyskuje doświadczenie", studiowanie samych i innych błędów ludzi i stopniowo Naucz się robić właściwe rozwiązania - jeśli nie jest optymalne, a następnie prawie optymalne. Spróbujmy zilustrować proces symulacji poprzez porównanie z klasycznym modelem matematycznym. Etapy procesu konstruowania modelu matematycznego złożonego systemu: 1. Sformułować podstawowe pytania dotyczące zachowania systemu, odpowiedzi, na które chcemy korzystać z modelu. 2. Od wielu przepisów kontrolujących zachowanie systemu, te, których wpływ są niezbędne podczas wyszukiwania odpowiedzi na pytania. 3. Oprócz tych przepisów, w razie potrzeby, w przypadku systemu jako całej lub poszczególnych części, formułuje się pewna hipoteza na funkcjonowaniu. Kryterium adekwatności modelu jest praktyka. Trudności w konstruowaniu modelu matematycznego złożonego systemu: Jeśli model zawiera wiele obligacji między elementami, różnorodnymi ograniczeniami nieliniowymi, dużą liczbą parametrów itp. Real Systems często podlegają wpływowi losowych różnych czynników, z których rachunkowość, której analitycznie reprezentuje bardzo duże trudności, często niezwyciężane z nimi; Możliwość dopasowania do modelu i oryginału z tym podejściem dopiero na początku. Trudności te są określane przez zastosowanie modelowania imitacji. Jest on wdrażany w następujących krokach: 1. Jak poprzednio, główne pytania dotyczące zachowania złożonego systemu są formułowane, odpowiedzi, na które chcemy zdobyć. 2. Rozkład systemu prowadzi się na prostszych blokach części. 3. Prawa i "wiarygodna" hipoteza są sformułowane w odniesieniu do zachowania jako systemu jako całej i poszczególnych części. 4. W zależności od pytań przedstawionych przed badaczem wprowadza się tak zwany czas systemowy, który symuluje czas w prawdziwym systemie. 5. Niezbędne właściwości fenomenologiczne systemu i oddzielnych części są ustawione formalizowane. 6. Losowe parametry, które pojawiają się w modelu, są porównywane z pewnymi wdrożeniami zapisanymi stałą dla jednego lub więcej cykli czasu systemowego. Następnie znaleziono nowe wdrożenia. 2.
Modelowanie symulacji procesów reprodukcyjnych w przemyśle naftowym i gazowym Nowoczesny etap rozwoju przemysłu ropy i gazu charakteryzuje się komplikacją linków i interakcji naturalnych, ekonomicznych, organizacyjnych, środowiskowych i innych czynników produkcji, zarówno na poziomie poszczególnych przedsiębiorstw, jak i naftowych i gazowych oraz na poziomie branży publicznej. W przemyśle naftowym i gazowym produkcja wyróżnia się długimi okresami, produkcji produkcji - proces w czasie (wyszukiwanie i eksploracja, rozwój i układ, produkcja oleju, gazu i kondensatu), obecność przemieszczeń opóźnionych i opóźnienia, dynamiczny Zasoby używane i inne czynniki, wartości wielu są zużyte probabilistyczny charakter. Wartości tych czynników systematycznie się zmieniają ze względu na uruchomienie nowych depozytów, a także nie potwierdzać oczekiwanych rezultatów na rozwój. Musza przemysł naftowy i gazowy, aby okresowo zmienić plany reprodukcji środków trwałych i redystrybucji zasobów w celu optymalizacji wyników działalności produkcyjnej i gospodarczej. W opracowywaniu planów znaczna pomoc dla osób przygotowywania projektu decyzji gospodarczej może zapewnić stosowanie metod modelowania matematycznego, w tym naśladowanie. Istotą tych metod jest wielokrotna reprodukcja zaplanowanych rozwiązań z późniejszą analizą i wyborem najbardziej racjonalnych ich w określonym systemie kryteriów. Korzystając z modelu symulacji, można utworzyć pojedynczy schemat strukturalny, który integruje kontrole funkcjonalne (planowanie strategiczne, taktyczne i operacyjne) dla głównych procesów przemysłowych przemysłu (wyszukiwania, eksploracji, rozwoju, wydobycia, transportu, ropy naftowej i gazu). 3.
Metoda Monte Carlo jako rodzajsymulacja symulacji Data urodzenia metody Montte Carlo jest uważana za 1949 r., Kiedy pojawił się artykuł o nazwie "Metoda Monte Carlo". Twórcy tej metody uważają amerykańskie matematyki J. Neuman i S. Ulama. W ZSRR pierwsze artykuły o metodzie Monte Carlo zostały opublikowane w latach 1955-1956. Jest ciekawa, że \u200b\u200bteoretyczna podstawa metody była znana od dłuższego czasu. Ponadto niektóre zadania statystyk zostały obliczone czasami za pomocą przypadkowych próbek, tj. W rzeczywistości przez Monte Carlo. Jednak przed pojawieniem się elektronicznych maszyn obliczeniowych (komputerów) metoda ta nie mogła znaleźć żadnych szerokich zastosowań, do symulowania zmiennych losowych "ręcznie - bardzo pracochłonna praca. Tak więc pojawienie się metody MONTA-CARLO jako bardzo uniwersalna metoda numeryczna była możliwe tylko z powodu komputera wyglądowego. Nazwa "Monte Carlo" pochodzi z miasta Monte Carlo w Księstwie Monako, słynącej z domu hazardowego. Idea metody jest niezwykle prosta i jest następująca. Zamiast opisywać proces przy użyciu urządzenia analitycznego (równań różnicowych lub algebraicznych), "rysowanie" zjawiska losowego jest wytwarzane przy użyciu specjalnie zorganizowanej procedury, która obejmuje wypadek i daje przypadkowy wynik. W rzeczywistości konkretna realizacja procesu losowego rozwija się za każdym razem; Ponadto, w wyniku modelowania statystycznego, otrzymujemy nowy, różniących się od drugiego wdrażania procesu w ramach studiów. Co może nam dać? Sam, nic, tak jak, powiedzmy, jeden przypadek leczenia pacjenta z lekiem. Kolejna rzecz, jeśli istnieje wiele takich implementacji. Ten zestaw wdrożeń może być stosowany jako pewien sztucznie uzyskany materiał statystyczny, który może być przetwarzany przez konwencjonalne metody statystyk matematycznych. Po takim leczeniu uzyskano wszelkie cechy zainteresowania: prawdopodobieństwa zdarzeń, oczekiwań matematycznych i dyspersji zmiennych losowych, itd. Podczas modelowania losowych zjawisk przez Monte Carlo, używamy najbardziej szansy jako urządzenia do nauki, zmuszając go "pracy odpowiedzialność." Często taka recepcja jest prostsza niż próby zbudowania modelu analitycznego. W przypadku złożonych operacji, w których zaangażowana jest duża liczba elementów (samochody, ludzi, organizacje, produkty użytkowe), w których trudno splecione czynniki losowe, w których proces jest wyraźnie Nemarkovskpy, metodą modelowania statystycznego, z reguły, Okazuje się być łatwiejszy niż analityczny (i często zdarza się jedyny możliwy). W istocie każde zadanie probabilistyczne można rozwiązać metodą Monte Carlo, ale staje się uzasadnione tylko wtedy, gdy procedura rysowania jest łatwiejsza i nie trudniejsza niż obliczenie analityczne. Daj nam przykład, gdy metoda Monte Carlo jest możliwa, ale niezwykle Nerazen. Niech, na przykład, w pewnym celu wykonane są trzy niezależne strzały, z których każda spada do celu z prawdopodobieństwem 1/2. Wymagane jest znalezienie prawdopodobieństwa co najmniej jednego trafienia. Obliczanie podstawowe daje nam prawdopodobieństwo co najmniej jednego trafienia równego 1 - (1/2) 3 \u003d 7/8. To samo zadanie można rozwiązać i "rysunek", modelowanie statystyczne. Zamiast "trzy strzały" rzucimy "trzy monety", biorąc pod uwagę, powiedzmy, herb - za uderzenie decyzji - dla "poślizgu". Doświadcza "udanego", jeśli przynajmniej jeden z herb jest jedną z monet. Produkujemy bardzo, bardzo wiele eksperymentów, obliczymy całkowitą liczbę "powodzenia" i podzieli liczbę n produkcji. Dlatego otrzymujemy częstotliwość zdarzenia i jest blisko prawdopodobieństwa z dużą liczbą eksperymentów. Więc co? Nałożyć taką recepcję, czy osoba, która nawet nie znała teorii prawdopodobieństw, jednak zasadniczo, jest to możliwe. Metoda Monte Carlo jest metodą numeryczną rozwiązywania problemów matematycznych przy użyciu modelowania zmiennych losowych. Rozważmy prostą metodę ilustrującej. Przykład 1. Załóżmy, że musimy obliczyć obszar płaskiej figury S. Może to być dowolna postać z granicą krzywoliniową, określoną graficznie lub analitycznie, podłączony lub składający się z kilku kawałków. Niech będzie to postać pokazana na rys. 1 i załóżmy, że wszystko znajduje się wewnątrz jednego kwadra. Wybierz wewnątrz kwadratu n losowych kropek. Oznaczono przez f Liczba punktów, które powstały na dodanie wewnątrz S. geometrycznie oczywiście, obszar S jest w przybliżeniu równy stosunku F / N. Im większa n, tym większa dokładność tej oceny. Dwie funkcje metody Monte Carlo. Pierwszą cechą metody jest prosta struktura algorytmu obliczeniowego. Drugą cechą sposobu jest błąd obliczeń, z reguły jest proporcjonalna do D / N2, gdzie d jest pewne stałe, n jest liczbą testów. Widać, że w celu zmniejszenia błędu 10 razy (innymi słowy, aby uzyskać inny wierny znak dziesiętny w odpowiedzi), konieczne jest zwiększenie N (tj. Wielkość pracy) jest w 100 razy. Oczywiste jest, że nie można osiągnąć wysokiej dokładności. Dlatego zwykle mówi się, że metoda Monte Carlo jest szczególnie skuteczna w rozwiązywaniu tych zadań, w których wynik jest potrzebny z małą dokładnością (5-10%). Metoda stosowania metody Monte Carlo w teorii jest dość prosta. Aby uzyskać sztuczną próbkę losową z zestawu ilości opisanych przez niektóre funkcje dystrybucji prawdopodobieństwa następujące: 1. Zbuduj wykres lub tabelę zintegrowanej funkcji dystrybucji opartych na wielu liczbach odzwierciedlających proces badanie (i nie oparty na wielu liczbach losowych), a wartości procesu zmiennego losowego są zdeponowane wzdłuż odcięcia Oś (X) i wartości prawdopodobieństwa (od 0 do 1) - na osi rzędnej (Y). 2. Za pomocą generatora liczby losowej, aby wybrać losową liczbę dziesiętną od 0 do 1 (z wymaganą liczbą wyładowań). 3. Przytrzymaj poziomy bezpośrednio z punktu na osi rzędnej odpowiadającej wybranej liczbie losowej, do skrzyżowania z krzywą dystrybucji prawdopodobieństwa. 4. Niższy z tego punktu skrzyżowania prostopadłego do osi odcięcia. b. Powtórz kroki 2-5 dla wszystkich wymaganych zmiennych losowych, zgodnie z zamówieniem, w którym zostały zarejestrowane. Ogólne znaczenie jest łatwe do zrozumienia z prostym przykładem: liczba połączeń do stacji telefonicznej przez 1 minutę odpowiada następującym dystrybucji: Liczba prawdopodobieństwa prawdopodobieństwa skumulowanego prawdopodobieństwa około 0,10 0,10 Przypuśćmy, że chcemy przeprowadzić eksperyment psychiczny przez pięć okresów. Konstruujemy skumulowany harmonogram dystrybucji prawdopodobieństwa. Za pomocą generatora liczb losowych otrzymujemy pięć liczb, z których każdy jest używany do określenia liczby połączeń w tym przedziale czasu. Ranom Numer Losowa liczba połączeń Robiąc kilka takich próbek, możesz upewnić się, że jeśli używane są używane są równomiernie, każde z wartości wartości w ramach badania pojawi się z taką samą częstotliwością, jak surrealistyczny świat, a otrzymamy wyniki typowe dla zachowanie systemu w ramach studiów. Wróćmy na przykład. Aby obliczyć, musieliśmy wybrać losowe kropki na jednym kwadracie. Jak to zrobić fizycznie? Wyobraź sobie taki eksperyment. Rys. 1. (Na powiększonej skali) z figurą i kwadratem zawieszonym na ścianie jako cel. Shooter, który był w pewnej odległości od ściany, strzela N razy, kierując się na środek placu. Oczywiście wszystkie pociski nie będą się położyć dokładnie do centrum: starają się na cel n losowych kropek. Czy można ocenić S. Plac w tych punktach. Oczywiste jest, że z strzałką o wysokiej kwalifikacji wynik doświadczenia będzie bardzo zły, ponieważ prawie wszystkie kule spadnie w pobliżu centrum i spadną do S. Nie trudno zrozumieć, że nasza metoda obliczania obszaru będzie ważna tylko wtedy, gdy losowe punkty nie będą proste "losowe", a także "równomiernie rozproszone" na całym placu. W celach operacyjnych metoda Monte Carlo jest stosowana w trzech pierwotnych rolach: 1) Podczas modelowania złożonych, zintegrowanych operacji, w których występuje wiele interakcji czynników losowych; 2) Podczas sprawdzania stosowania prostszych, metod analitycznych i wyjaśnienia warunków ich stosowania; 3) W celu opracowania poprawek do formuł analitycznych, takich jak "wzory empiryczne" w dziedzinie. 4.
Przykład. Ocena zapasów geologicznych Aby oszacować wartość rezerw odzyskiwalnych, konieczne jest przede wszystkim, aby określić ilość rezerw całkowitej lub geologicznej. Analiza pułapek strukturalnych. Aby oszacować zawartość w pułapce strukturalnej i / lub gazu, wyszukiwania i geologów i geofizyki powinny zbadać charakter pułapki strukturalnej. Takie badanie jest konieczne do określenia możliwej wielkości zapasów geologicznych. Zakres zmian akcji zależy od kombinacji następujących szacunków: objętość skał sedymentacyjnych (RV), porowatość (F), nasycenie wodociągowe Perico (SW), skuteczna moc (NP) G. Definicja prawdopodobnych wartości parametrów. Na tym etapie geologowie powinni oszacować wartość prawdopodobieństw dla parametrów stosowanych w obliczeniu zapasów geologicznych. Każdy parametr przypisuje się interwałowych wartości prawdopodobieństw, na podstawie ekspertów geologów Analiza wykresów prawdopodobieństwa. Grafika nagromadzona prawdopodobieństwo. Ciągłe krzywa jest prawdopodobieństwem, że wartość parametru rozważana będzie "równa lub większa" niż wartość w punkcie osi poziomej, która przecinająca pionową linię zaprojektowaną z krzywej, z prostopadłą osi pionowej W przypadku jakichkolwiek wartości od 0 do 100%. Krzywa jest zbudowana zgodnie z histogramy, które są wyświetlane jako zacienione kolumny. Histogramy to ekspertowa ocena geologów wyszukiwania i pola i geofizycy, którzy dostarczają informacji w następującej formie: Naszym zdaniem prawdopodobieństwo, że objętość osadów skał znajduje się w zakresie od 0 do 390 tysięcy stóp wynosi 10%; Według naszej oceny prawdopodobieństwo, że wielkość rasy wynosi od 380 do 550 cu. stopy wynosi 15% i tak dalej. Te szacunki geologów gromadzą się, w wyniku czego otrzymuje się uogólniona krzywa prawdopodobieństwa. Na podstawie tej krzywej możesz ekstrapolować wartości oczekiwanych prawdopodobieństw dla badanych parametrów. Liczenie zapasów geologicznych. Objętość rezerw geologicznych jest obliczana przy użyciu następującego wzoru: RVXFX (L-SW) X NPX - gdzie FV jest współczynnikiem oleju prowadzącego do warunków powierzchniowych. Wykorzystanie średnich wartości w celu uzyskania przybliżonego oszacowania zapasów geologicznych. Przy szacowaniu przybliżonej ilości oleju w polu, użyjemy następujących wartości parametrów: Średnia objętość objętości skał wynosi 1,35 mln akologitów (1 Acrofut \u003d 7760 beczek lub około 1230 m3) Średnia porowatość - 17% Średnia nasycenie wody - 20% Średnia wydajna moc - 75% Współczynnik przynoszenia - 1.02 (w warunkach zbiorników nie ma wolnego gazu). Teraz zastąpimy te wartości w formule (1,35 x 1 0) x (1 7%) x (1 - 20%) x (75%) x (tj.: 135000000x0,0,97x0.8x0.75x0.98) \u003d 134946 Acrofites lub 134946x7760 \u003d 1047413760, \\ t tj. Około 1,047 mld beczek oleju (165 mln M3, 141 mln ton). Bardziej powszechny sposób: Metoda Monte Carlo. Przede wszystkim konieczne jest skonstruowanie histogramów i krzywych zgromadzonego prawdopodobieństwa dla każdego parametru. Dla każdej z tych krzywych jest losowy, aby wybrać punkt odpowiadający prawdopodobieństwu od 0 do 100%. Następnie konieczne jest zastąpienie wartości parametru odpowiadającego tym prawdopodobieństwu w równaniu. Następnie możesz policzyć rezerwy geologiczne na tych wartościach parametrów i obliczyć pełne prawdopodobieństwo. Na przykład: Za 50% zgromadzonego prawdopodobieństwa mamy 25% szans, że objętość skał wynosi 690000 akroretów Za 20% zgromadzonego prawdopodobieństwa mamy 35% prawdopodobieństwo, że porowatość będzie 21% Za 25% zgromadzonego prawdopodobieństwa mamy 25% prawdopodobieństwa, że \u200b\u200bzawartość wody wynosi 33% 80% zgromadzone prawdopodobieństwo pokazuje 32% prawdopodobieństwa, że \u200b\u200bskuteczna moc wynosi 74%. Współczynnik doprowadzenia oleju do warunków powierzchniowych jest pobierany równy 1,02. Korzystając z tych wartości, obliczamy rezerwy geologiczne: (0,69 x 1 0) X (2 1%) X (L - 33%) X (74%) X ---- Decydowanie, otrzymujemy w przybliżeniu: 521 milionów beczek oleju (82 mln M3, 70 milionów ton). Wynik tego obliczenia jest znacznie mniejszy niż przy użyciu średnich wartości parametrów. Musimy poznać prawdopodobieństwo tego wyniku. Aby określić prawdopodobieństwo, że rezerwy geologiczne będą 521 milionów beczek oleju, obliczymy pełne prawdopodobieństwo: 0,25 x 0,35 x 0,20 x 0,35 x 1,0 \u003d 0,006125, tj. Prawdopodobieństwo wynosi 0,6125% - niezbyt dobre! Ta procedura jest powtarzana wielokrotnie, dla których korzystaliśmy z programu sporządzony do komputera. Daje nam to rozsądny problem probabilistyczny rezerw geologicznych. W wyniku wykonania programu przewidziano objętość rezerw geologicznych oleju: objętość oleju najprawdopodobniej wynosi 84658 acrofitów lub około 88,5 mln ton. Użyj rozkładu zgromadzonego prawdopodobieństwa. W następnym kroku, korzystając z harmonogramu, należy wybrać kilka szacunków z ich prawdopodobieństwami. Dla każdej z tych wartości oblicza się dynamika produkcji, warianty projektu rozwoju. Obliczenia te można następnie wykorzystać do oceny kosztów operacyjnych kapitałowych dla każdej wartości zapasów wybranych z harmonogramu. Następnie wskaźniki ekonomiczne są następnie przeanalizowane dla każdej wartości zapasów. Po pewnym czasie i po wierceniu niektórych studni, współczynnik sukcesu jest obliczany przez formułę. Stosunek sukcesu \u003d liczba studni Vasche. Olej liczba ruchu. Dobrze W okresie od kilku lat sporządzono wykres prawdopodobieństwa sukcesu. Na przykład, dla obszaru warunkowego, harmonogram współczynnika sukcesu jest skompilowany po dziewięciu latach działania. Poprzez odpowiednie wartości sukcesu są linie warunkowe, wówczas koperta krzywej jest przeprowadzana przez ich centra. Ekstremalne punkty tych linii odpowiadają maksymalnym poziomie sukcesu, a centralna krzywa odpowiada najbardziej prawdopodobnym poziomie osiągnięcia sukcesu wartości prawdopodobieństwa określa się na podstawie subiektywnych wyroków geologów komercyjnych. Podobnie określono poziom zapasów na studzienkę. Z pomocą szybkością sukcesu i średnich rezerw na dobro, prawdopodobieństwo osiągnięcia pewnego poziomu zapasów wymaganych do skompilowania programu wiertniczego i określa określoną liczbę dobrze wymaganych studni. Wniosek Główną wadą modeli analitycznych jest to, że nieuchronnie wymagają żadnych założeń, w szczególności o "walce" procesu. Dopuszczalność tych założeń nie zawsze jest oszacowana bez obliczeń kontrolnych, ale są one produkowane przez Monte Carlo. Metoda w przenośni Monte Carlo Metoda w zadaniach badań operacji odgrywa rolę rodzaju odbioru. Modele statystyczne nie wymagają poważnych założeń i uproszczeń. Zasadniczo w modelu statystycznym "wspina się" cokolwiek - wszelkie prawa dystrybucyjne, jakąkolwiek złożoność systemu, wiele jej stanów. Głównym brakiem modeli statystycznych jest ich nieporęczna i złożoność. Ogromna liczba implementacji potrzebnych do znalezienia pożądanych parametrów o dopuszczalnej dokładności wymaga dużo czasu maszyn. Ponadto wyniki modelowania statystycznego są znacznie trudniejsze do zrozumienia niż obliczenia dotyczące modeli analitycznych, a zatem trudniej jest zoptymalizować rozwiązanie (konieczne jest "uchwyt" na ślepo). Prawidłowa kombinacja metod analitycznych i statystycznych w badaniu operacji jest przypadkiem sztuki, osłabienia i doświadczenia badacza. Często metodami analitycznymi udaje nam się opisać niektóre "podsystemy", przydzielone w dużym systemie, a następnie z takich modeli, jak z "cegieł", zbuduj duży, złożony budynek modelu. Bibliografia 1. Ventcel E.S. "Badanie operacji", Moskwa "Radiet Radio" 1972 2. SOBE I.M. "Metoda Monte Carlo", Moskwa "Nauka", 1985 3. "Metody ekonomiczne i matematyczne i zastosowane modele", ed. Fedoseeva V.v., Moskwa "Uniti" 2001 Koncepcja modelowania imitacji, wykorzystania go w gospodarce. Etapy procesu konstruowania modelu matematycznego złożonego systemu, kryteria jego adekwatności. Modelowanie zdarzeń dyskretnych. Metoda Monte Carlo jest rodzajem symulacji. egzamin, dodano 12/23/2013 Model statystyczny procesu losowego. Metoda numeryczna Monte Carlo. Rodzaje imitacji, jego zalety i możliwości. Prosty model imitacji systemu przetwarzania dokumentów. Użyj symulacji języka SIMAN. Jego główne bloki modelujące. prezentacja dodana 22.10.2014 Obliczanie efektu ekonomicznego pracy banku. Symulacja na podstawie wstępnie zainstalowanych zależności. Funkcja dystrybucji prawa wykładniczego. Dostosowanie czasu obsługi klienta w Cass and Turn Promocja. badanie dodane 03.10.2008 Obliczanie efektu ekonomicznego pracy banku. Modelowanie symulacji algorytmu hali gotówkowej. Funkcja dystrybucji prawa wykładniczego. Dostosowanie czasu obsługi klienta w Cass and Turn Promocja. Programy listy. badanie dodane 03.10.2008 Modelowanie symulacji jako metoda analizy systemów gospodarczych. Badanie wstępnego projektu firmy drukarskiej. Badanie określonego systemu przy użyciu modelu procesu Markowa. Obliczanie czasu usługi jednej aplikacji. praca kursu, dodano 10/23/2010 Efektywność inwestycji kapitałowych. Statystyczne metody oceny wykonalności inwestycji z ryzykiem. Analiza wrażliwości, scenariusze. Ustanowienie wartości nominalnych i ograniczających niepewnych czynników. Modelowanie symulacji Monte Carlo. badanie dodane 10.27.2008 Koncepcja jednolitej zmiennej losowej. Metoda multipliceatywna zgodna. Modelowanie ciągłych zmiennych losowych i dyskretnych dystrybucji. Algorytm naśladowania modelowania stosunków gospodarczych między pożyczkodawcą a kredytobiorcą. praca kursu, dodano 01/03/2011 Przegląd metod rozwiązania problemu. Obliczanie liczby klientów, przychodów, średniego wielkości kolejki i liczby awarii do okresu modelowania. Algorytm do modelowania procesu, opracowywanie wdrażania oprogramowania. Eksperyment maszyny z rozwiniętym modelem. kursy, dodane 01.01.2011 Opis symulacji komputerowej. Zalety, etapy i podejścia do budowy modelowania imitacji. Zawartość podstawowej koncepcji budowania języka modelowania GPSS. Metoda oceny i rewizji planów (pert). Modelowanie w systemie GPSS. praca kursu, dodano 03/03/2011 Metoda modelowania symulacji w rozwoju modeli gospodarczych i matematycznych, aby uwzględnić niepewność statystyk przedsiębiorstw. Funkcjonowanie modelu symulacji wytwarzania małego przewodniczącego: czas pracy i urządzeń Współczynniki rozruchowe. Modelowanie symulacyjne to metoda, która umożliwia budowanie modeli opisujących procesy, które w rzeczywistości. Ten model może "stracić" w czasie zarówno dla testu, jak i określonego zestawu. W takim przypadku wyniki zostaną określone przez losowy charakter procesów. Zgodnie z tymi danych możesz uzyskać wystarczająco stabilną statystykę. Znaczenie tego tematu jest to, że modelowanie naśladowania na maszynach cyfrowych komputerów jest jednym z najpotężniejszych narzędzi badawczych, w szczególności złożonych systemów dynamicznych. Podobnie jak każda symulacja komputerowa, umożliwia przeprowadzenie eksperymentów obliczeniowych z tylko zaprojektowanymi systemami systemów i systemów studiów, eksperymenty terenowe, z których ze względów bezpieczeństwa lub wysokich kosztów nie są odpowiednie. Jednocześnie dzięki bliskość formularza do modelowania fizycznego metoda badania jest dostępna dla szerszego zakresu użytkowników. Modelowanie symulacyjne jest metodą badawczą, w której badany system jest zastępowany przez model z wystarczającą dokładnością opisującą realny system i eksperymenty są przeprowadzane w celu uzyskania informacji o tym systemie. Cele zachowania takich eksperymentów mogą być najbardziej różne - od identyfikacji właściwości i wzorców systemu w ramach studiów, przed rozwiązaniem określonych zadań praktycznych. Wraz z rozwojem sprzętu komputerowego i oprogramowania spektrum zastosowania imitacji w dziedzinie gospodarki znacznie się rozszerzyło. Obecnie stosuje się zarówno do rozwiązania problemów z zarządzania Intrafirny, jak i zarządzanie modelowaniem na poziomie makroekonomicznym. Rozważ główne zalety korzystania z modelowania imitacji w procesie rozwiązywania problemów z analizą finansową. W procesie modelowania symulacji badacz zajmuje się czterema głównymi elementami: Prawdziwy system; Model logika-matematyczny symulowanego obiektu; Model symulacji (maszyny); Komputer, na którym przeprowadza się imitacja jest kierowanym eksperymentem obliczeniowym. Aby opisać dynamikę symulowanych procesów w modelowaniu imitacji, wdrożono zadanie czasu. Mechanizmy te są osadzone w programach sterujących dowolnego systemu modelowania. Jeśli zachowanie jednego składnika systemu zostało symulowane na komputerze, wykonanie działań w modelu symulacji można przeprowadzić sekwencyjnie, poprzez ponowne obliczenie współrzędnej czasowej. Aby symulować zdarzenia równoległe w prawdziwym systemie, niektóre zmienne globalne (zapewniające synchronizację wszystkich zdarzeń w systemie) T0, który nazywa się czasem modelowym (lub systemowym). Istnieją dwa główne sposoby zmiany T0: Krok po kroku (odstępy stałe zmiany czas modelowy); Podobne (obowiązują przedziały zmienne zmiany czas modelowy, podczas gdy krok jest mierzony przez interwał przed następnym wydarzeniem). W przypadku metody krok po kroku, promocja czasu występuje z minimalnym możliwym stałym etapem kroku (zasada t). Algorytmy te nie są zbyt skuteczne od punktu widzenia wykorzystania czasu maszyny do ich wdrożenia. Uczciwą metodę (zasada "państw specjalnych"). W nim współrzędne zmieniają się tylko wtedy, gdy stan się zmienia się. W metodach czasu, długość tymczasowego kroku przesunięcia jest maksymalna możliwa. Czas modelu z bieżącej chwili zmienia się w najbliższym momencie następnego wydarzenia. Zastosowanie preferowanej metody jest korzystne, jeśli częstość występowania zdarzeń jest mała, a duża długość kroku przyspieszy czas modelu modelu. Podczas rozwiązywania wielu zadań analizy finansowej, zastosowane są modele zawierające zmienne losowe, których zachowanie nie jest podatne na zarządzania decydentami. Takie modele nazywane są stochastycznie. Korzystanie z imitacji pozwala wyciągnąć wnioski o możliwych wyników opartych na dystrybucjach probabilistycznych czynników losowych (wartości). Imitacja stochastyczna jest często nazywana Monte Carlo. Ze wszystkich powyższych, można stwierdzić, że modelowanie symulacji pozwala wziąć pod uwagę maksymalną możliwą liczbę zewnętrznych czynników środowiskowych w celu wspierania przyjęcia decyzji zarządzających i jest najpotężniejszym środkiem analizowania ryzyka inwestycyjnego. Potrzeba jego stosowania w krajowej praktyce finansowej wynika ze specyfiki rynku rosyjskiego charakteryzuje się podmiotem, uzależnienie od czynników nieekonomicznych i wysokiego stopnia niepewności. Wyniki symulacji mogą być uzupełniane przez analizę probabilistyczną i statystyczną oraz jako całość dostarczają menedżera z najbardziej szczegółowymi informacjami o stopniu wpływu kluczowych czynników oczekiwanych wyników i możliwych scenariuszy rozwoju wydarzeń. Procesy stają się metodą, która umożliwia projektowanie próbek opisujących procesy w taki sposób, jakby faktycznie funkcjonowały. Stosując je, możliwe jest uzyskanie stabilnych i niezawodnych statystyk. Na podstawie tych danych można wybrać optymalną ścieżkę rozwoju organizacji. Metoda symulacji jest metodą badawczą, w której określony system zostanie zastąpiony przez ten, który ma wystarczającą dokładność w opisie prawdziwego. Musi być przeprowadzony eksperymenty w celu uzyskania wiarygodnych informacji. Taka procedura pozwoli zrozumieć istotę zjawiska bez uciekania się w tym przypadku na rzeczywiste zmiany w obiekcie do czasu. Symulacja procesów biznesowych jest szczególnym przypadkiem modelowania matematycznego. Faktem jest, że istnieje klasa obiektów, dla których modele analityczne nie zostały opracowane z różnych powodów. Lub nie ma systemu korzystania z innowacyjnego rozwiązania. W takich przypadkach stosuje się modelowanie procesów gospodarczych. Jest to miejsce, kiedy: Procesy symulacyjne mają kilka typów. Rozważ je bardziej szczegółowo. Modelowanie alarmu jest innowacyjnym kierunkiem, który jest szeroko stosowany do eksploracji zdecentralizowanych systemów. Dynamika ich funkcjonowania określa się nie tak wiele przez globalne przepisy prawa i regulacje, ale przeciwnie, zasady te stają się wynikiem indywidualnej działalności członków tej grupy. Dlatego w tym przypadku cel i cele modeli mają uzyskać zgłoszenia w tych podstawowych zasadach, zachowanie wybranego systemu. Ale konieczne będzie przejście od założeń dotyczących indywidualnych, prywatnych zachowań poszczególnych obiektów, a także ich relacji w systemach. Agent staje się szczególną istotą, która ma aktywność i autonomię w zachowaniu, jest w stanie zaakceptować i stosować rozwiązania zgodnie z zestawem szczegółowych zasad, interakcji z otaczającym środowiskiem, a także niezależnie się zmienia. Modelowanie zdarzeń dyskretnych to podejście do modelowania, które oferuje abstrakcję z dostępnych wydarzeń, biorąc pod uwagę wiele podstawowych zdarzeń w systemie. Mówimy o "Czekaniu", "Przetwarzanie zamówień", "Ruch z ładunkiem", "rozładunku" i tak dalej. Takie modelowanie jest bardzo dobrze rozwinięte i ma ogromną sferę aplikacji - z logistyki, a także systemów usługowych do systemów produkcyjnych i transportowych. Ogólnie rzecz biorąc, metoda może być idealnie w każdej sytuacji; J. Gordon został założony w środku XX wieku. Dynamika systemu jest modelowaniem symulacji procesów ekonomicznych, gdy grafika, wykresy, obliczenia zostaną zbudowane do badanego obiektu, odzwierciedlając przyczyny i globalne wpływy niektórych kryteriów dla innych w pewnym okresie czasu. Następnie system utworzony na nich jest imitowany na komputerze. Dzięki temu istnieje prawdziwa okazja do realizacji istoty tego, co się dzieje i zidentyfikować istniejące połączenia przyczyn i dochodzeń między zjawiskami a obiektami. Dynamika systemu pomaga budować modele do rozwoju miast, procesów biznesowych, systemów produkcyjnych, ekologii, populacji, epidemii i tak dalej. Projekt kursu Zgodnie z tematem: "Modelowanie procesów przemysłowych i gospodarczych" Na temat: "Modelowanie symulacji procesów gospodarczych" Wprowadzenie I. Główne koncepcje teorii modelowania systemów gospodarczych i procesów 1 Koncepcja modelowania 1.2 Koncepcja modelu II. Główne koncepcje teorii modelowania systemów gospodarczych i procesów 2.1 Sprawdzanie i rozwój systemów gospodarczych 2 elementy modelu symulacji III. Podstawy symulacji 3.1 Model imitacji i jego funkcje 2 Istota symulacji IV. Praktyczna część 1 oświadczenie o problemach. 2 Rozwiązanie zadania Wniosek Lista używanych literatury podanie Wprowadzenie Symulacja, analiza programowania i regresji liniowej w zakresie i częstotliwości użytkowania od dawna zajmowały pierwsze trzy miejsca wśród wszystkich metod badań operacji w gospodarce. Podczas symulacji symulacji algorytm implementuje model odtwarza proces działalności systemu w czasie i przestrzeni, a składniki procesu zjawisk elementarnych są symulowane przy zachowaniu jego logicznej struktury czasowej. Obecnie symulacja stała się dość skutecznym rozwiązaniem do rozwiązania złożonych zadań automatyzacji badań, eksperymentów, projektowania. Ale opanować symulację jako narzędzie robocze, jego duże możliwości i rozwijają metodologię modelowania wyłącznie z pełnym opanowaniem technik i technologii praktycznego rozwiązania problemów modelowania funkcjonowania systemów na komputerze. Cel ten jest również dąży do tego warsztatu, który koncentruje się na metodach, zasadach i głównych etapach modelowania w ramach metodologii generalnej modelowania, a także rozważa modelowanie konkretnych opcji systemowych i umiejętności wykorzystania technologii modelowania z praktycznym wdrożeniem modeli funkcjonujących systemów . Rozważane są problemy masowych systemów konserwacyjnych, na których oparte są imitację modeli systemów gospodarczych, informacyjnych, technologicznych, technicznych i innych systemów. Przedstawiono metody probabilistycznego modelowania dyskretnych i przypadkowych ciągłych wartości, które umożliwiają rozważenie podczas modelowania systemów gospodarczych, przypadkowych wpływów na system. Wymagania wykonane przez nowoczesne społeczeństwo specjalistom w dziedzinie ekonomii stale rosną. Obecnie udane działania nie są możliwe w prawie wszystkich sferach gospodarki bez modelowania zachowania i dynamiki rozwoju procesów, badając cechy rozwoju obiektów gospodarczych, uwzględniając ich funkcjonowanie w różnych warunkach. Oprogramowanie i środki techniczne powinny być tutaj pierwszymi asystentami. Zamiast uczyć się z ich błędów lub na błędy innych ludzi, wskazane jest naprawienie i sprawdzenie poznania rzeczywistej rzeczywistości z wynikami uzyskanymi w modelach komputerowych. Modelowanie symulacyjne jest najbardziej wizualne, stosowane w praktyce dla symulacji komputerowej opcji zezwolenia na sytuacje w celu uzyskania najskuteczniejszych rozwiązań problemów. Symulacja pozwala na zbadanie analizowanego lub przewidywanego systemu zgodnie z systemem badania operacyjnego, który zawiera ze sobą połączone kroki: · Rozwój modelu koncepcyjnego; · Rozwój i wdrażanie oprogramowania modelu symulacyjnego; · Sprawdzanie poprawności, autentyczności modelu i oceny dokładności wyników modelowania; · Planowanie i prowadzenie eksperymentów; · podejmować decyzje. Pozwala to na wykorzystanie modelowania imitacji jako uniwersalnego podejścia do podejmowania decyzji w warunkach niepewności, biorąc pod uwagę modele trudne do formalizowanych czynników, a także stosuje podstawowe zasady systematycznego podejścia do rozwiązywania problemów praktycznych. Powszechne wprowadzenie tej metody w praktyce zapobiega potrzebie tworzenia implementacji oprogramowania modeli symulacyjnych, które odtwarzają w czasie modelu dynamika funkcjonowania symulowanego systemu. W przeciwieństwie do tradycyjnych metod programowania, rozwój modelu symulacji wymaga restrukturyzacji zasad myślenia. Nic dziwnego, że zasady oparte na modelowaniu imitacji, dały impuls do rozwoju programowania obiektów. Dlatego wysiłki programistów oprogramowania imitacji mają na celu uproszczenie implementacji programu modeli symulacyjnych: Tworzone języki i systemy są tworzone dla tych celów. Programy oprogramowania imitacji w ich rozwoju zmieniły się w ciągu kilku pokoleń, począwszy od języków modelowania i sposobów automatyzacji modeli do generowania programów, interaktywnych i inteligentnych systemów, rozproszonych systemów modelowania. Głównym celem wszystkich tych funduszy jest zmniejszenie złożoności tworzenia implementacji oprogramowania modeli imitacji i eksperymentowania z modeli. Jednym z pierwszych języków modelowania, które ułatwiają proces pisania programów symulacyjnych, był język GPSS stworzony w formie końcowego produktu Jeffrey Gordona w IBM w 1962 roku. Obecnie istnieją tłumacze do systemów operacyjnych DOS - GPS / PC, dla OS / 2 i DOS - GPSSS / H i Windows - świat GPSS. Badanie tego języka i tworzenie modeli umożliwiają zrozumienie zasad rozwoju programów symulacyjnych i nauczyć się pracować z modeli symulacyjnych. (System symulacji ogólnego przeznaczenia - system modelowania ogólnego przeznaczenia) jest używanym językiem modelującym Aby zbudować zdarzenia Dyskretne modele symulacyjne i prowadzenie eksperymentów za pomocą komputera osobistego. System GPSS jest językiem i tłumaczem. Jako każdy język, zawiera słownik i gramatykę, z którymi można opracować modele systemów określonego typu. I. Główne koncepcje teorii modelowania systemów gospodarczych i procesów 1.1 Koncepcja modelowania Pod modelowaniem jest rozumiany jako proces budowy, studiowania i używania modeli. Jest on ściśle związany z takimi kategoriami, jak abstrakcja, analogia, hipoteza itp. Proces symulacji koniecznie obejmuje budowę abstrakcji i wniosków analogicznych oraz projektowanie hipotez naukowych. Główną cechą modelowania jest to, że jest to sposób pośredniczy wiedzy z pomocą zastępcy obiektów. Model działa jako osobliwy instrument wiedzy, że badacz stawia się nawzajem i obiekt, z którym bada przedmiot zainteresowania. Każdy system społeczno-gospodarczy jest złożonym systemem, w którym dziesiątki i setki procesów gospodarczych, technicznych, technicznych i społecznych interakcji, które stale zmieniają się pod wpływem warunków zewnętrznych, w tym postęp naukowy i technologiczny. W takich warunkach, zarządzanie systemami społeczno-ekonomiczno-ekonomicznymi i produkcyjnymi jest przekształcane w złożone zadanie wymagające specjalnych środków i metod. Modelowanie jest jedną z głównych metod poznania, jest formą odbicia rzeczywistości i jest wyjaśnienie lub rozmnażanie pewnych właściwości rzeczywistych obiektów, obiektów i zjawisk przy użyciu innych obiektów, procesów, zjawisk lub przy użyciu opisu abstrakcyjnego jako obrazu, plan , karty, spalanie równań, algorytmów i programów. W najbardziej ogólnym znaczeniu, pod modelem, logicznym (słownym) lub matematycznym opisem składników i funkcji, które wyświetla istotne właściwości symulowanego obiektu lub procesu, są zwykle uważane za systemy lub elementy systemu z określonego punktu widok. Model jest używany jako warunkowy obraz zaprojektowany, aby uprościć badanie obiektu. Zasadniczo nie tylko matematyczne (kultowe), ale także modele materialne mają zastosowanie w gospodarce, ale modele materialne mają tylko wartość demonstracyjną. Istnieją dwa punkty widzenia na istotę modelowania: Jest to badanie obiektów wiedzy w modelach; Jest to konstrukcja i badanie modeli rzeczywiście istniejących obiektów i zjawisk, a także szacowanych (zaprojektowanych) obiektów. Możliwości modelowania, czyli przeniesienie wyników uzyskanych podczas budowy i badania modelu, oryginał opiera się na fakcie, że model w pewnym sensie wyświetla się (reprodukuje, symuluje, opisuje, naśladowanie) niektóre z badacze funkcji obiektów. Modelowanie jako formę odbicia rzeczywistości jest szeroko rozpowszechniona, a dość pełna klasyfikacja możliwych rodzajów modelowania jest niezwykle trudna, przynajmniej ze względu na znaczenie koncepcji "modelu", szeroko stosowaną nie tylko w nauce i technologii, ale także W sztuce i w życiu codziennym. Słowo "model" wystąpił z łacińskiego słowa "moduł", oznacza "środek", "próbka". Jego początkowe znaczenie było związane z sztuką budowlaną, a prawie wszystkie języki europejskie, został użyty do wyznaczenia obrazu lub warunków wstępnych lub rzeczy podobnych do tego z inną rzeczą. Wśród systemów społeczno-gospodarczych wskazane jest przydzielenie systemu produkcyjnego (PS), który, w przeciwieństwie do systemów innych klas, zawiera jako ważny element świadomie istniejącej osoby, która wykonuje funkcje zarządzania (podejmowanie decyzji i ich kontrola). Zgodnie z tym różne podziały przedsiębiorstw można uznać za PS, same przedsiębiorstwa, organizacje badawcze i projektowe, stowarzyszenia, branże i, w niektórych przypadkach gospodarka narodowa jako całość. Charakter podobieństwa między symulowanym obiektem a modelem jest wyróżnione: Fizyczny - obiekt i model mają taki sam lub podobny charakter fizyczny; Obserwuje się strukturę - podobieństwo między strukturą obiektu a strukturą struktury; Funkcjonalny - obiekt i model wykonują podobne funkcje w odpowiednim efekcie; Dynamiczny - istnieje korespondencja między sekwencyjnie zmieniającymi się stanami obiektu a modelem; Probabilistyczne - istnieje korespondencja między procesami probabilistycznymi w obiekcie i modelu; Geometryczny - istnieje korespondencja między cechami przestrzennymi obiektu a modelem. Modelowanie jest jednym z najczęstszych sposobów studiowania procesów i zjawisk. Modelowanie opiera się na zasadę analogii i pozwala nam zbadać obiekt w pewnych warunkach i, biorąc pod uwagę nieunikniony jednostronny punkt widzenia. Obiekt jest trudny do nauki, nie jest bezpośrednio badany, ale poprzez rozważanie innego, podobnego do niego i bardziej przystępnego dostępu - model. Zgodnie z właściwościami modelu zazwyczaj możliwe jest ocenianie właściwości badanych obiektów. Ale nie o wszystkich właściwościach, ale tylko o tych, które są podobne w modelu, w obiekcie, a jednocześnie są ważne dla badań. Takie właściwości są nazywane niezbędnymi. Czy istnieje potrzeba matematycznego modelowania gospodarki? Aby upewnić się, że wystarczy odpowiedzieć na pytanie: Czy można wykonać projekt techniczny bez planu działania, tj. Rysunki? Ta sama sytuacja ma miejsce w gospodarce. Czy konieczne jest udowodnienie konieczności korzystania z modeli ekonomicznych i matematycznych do podejmowania decyzji zarządzania w dziedzinie ekonomii? Model gospodarczy i matematyczny okazuje się być głównym sposobem eksperymentalnych badań gospodarki, ponieważ ma następujące właściwości: Naśladuje prawdziwy proces gospodarczy (lub zachowanie obiektów); Ma stosunkowo niski koszt; Może być wielokrotnie używany; Uwzględnia różne warunki funkcjonowania obiektu. Model może i powinien odzwierciedlać wewnętrzną strukturę obiektu gospodarczego z określonych (zdefiniowanych) punktów widzenia, a jeśli jest nieznany, a następnie jego zachowanie, stosując zasadę "czarnego pudełka". Zasadniczo każdy model można sformułować na trzy sposoby: W wyniku bezpośredniej obserwacji i badania zjawisk rzeczywistości (metoda fenomenologiczna); Wyczerpanie z bardziej ogólnego modelu (metoda dedukcyjna); Uogólniający więcej prywatnych modeli (metoda indukcyjna, tj. Dowód przez indukcję). Modele, niekończące się w ich różnorodności, można sklasyfikować zgodnie z różnymi funkcjami. Przede wszystkim wszystkie modele można podzielić na fizyczne i opisowe. A z tymi, a z innymi jesteśmy stale się zająć. W szczególności opisowy zawiera modele, w których symulowany obiekt jest opisany słowami, rysunkami, zależnościami matematycznymi itp. Do takich modeli można przypisać literatury, sztuki wizualnej, muzyce. Modele ekonomiczne i matematyczne są szeroko stosowane w zarządzaniu procesami gospodarczych. W literaturze nie ma dobrze ugruntowanej definicji modelu gospodarczego i matematycznego. Podejmij poniższą definicję jako podstawę. Model gospodarczy i matematyczny jest matematycznym opisem procesu gospodarczego lub obiektu przeprowadzonego w celu studiowania lub zarządzania nimi: rejestr matematyczny rozwiązany problem ekonomiczny (dlatego często terminy zadanie i model są używane jako synonimy). Modele mogą być również klasyfikowane do innych funkcji: Modele opisane w momencie, gdy stan gospodarki nazywane są statycznym. Modele, które pokazują rozwój obiektu modelowania nazywane są dynamiczne. Modele, które można zbudować nie tylko w formułach wzorów (reprezentacja analityczna), ale także w postaci przykładów numerycznych (reprezentacji numerycznej), w postaci tabel (reprezentacja matrycowa), w formie specjalnego rodzaju reprezentacji sieci wykresów ). 2 model koncepcyjny. Obecnie niemożliwe jest zadzwonić do obszaru działalności człowieka, w której metody obserwacji byłyby używane do jednego lub innego lub innego. Tymczasem ogólnie rozpoznana definicja koncepcji modelu nie istnieje. Naszym zdaniem, poniższa definicja zasługuje na preferencje: Model jest przedmiotem jakiegokolwiek charakteru tworzonego przez badacza w celu uzyskania nowej wiedzy na temat oryginalnego obiektu i odzwierciedla tylko znaczące (z punktu widzenia dewelopera) właściwości oryginału. Analiza treści tej definicji można wyciągnąć następujące wnioski: ) Każdy model jest subiektywny, nosi pieczęć indywidualności badacza; ) Każdy model homomorficznych, tj. Odzwierciedla to nie wszystkie, ale tylko podstawowe właściwości oryginalnego obiektu; ) Istnienie różnych modeli tej samej oryginalnej oryginalności, które można różnić w celach badania i stopnia adekwatności. Model jest uważany za odpowiedni obiekt oryginału, jeśli jest to wystarczający stopień przybliżenia na poziomie zrozumienia symulowanego procesu przez badacza odzwierciedla wzorce procesu funkcjonowania rzeczywistego systemu w środowisku zewnętrznym. Modele matematyczne można podzielić na analityczne, algorytmiczne (imitacja) i łącznie. W przypadku modelowania analitycznego charakterystyczne jest, że systemy algebraicznych, różnicowych, integralnych lub skończonych równania są używane do opisania działania systemu. Model analityczny może być badany przez następujące metody: a) analityczne, gdy mają tendencję do uzyskania wyraźnych zależności ogólnie dla pożądanych cech; b) Licznicy, gdy, nie wiedząc, jak rozwiązać równania w formie ogólnej, starają się uzyskać wyniki liczbowe z określonymi początkowymi danymi; c) jakościowy, gdy, bez rozwiązywania wyraźnej postaci, można znaleźć niektóre właściwości roztworu (na przykład do oceny stabilności roztworu). W modelowaniu algorytmicznego (symulacji), proces funkcjonowania systemu w czasie jest opisany, a elementy elementów elementów elementów elementów podstawowych, przy zachowaniu ich struktury logicznej i przepływu przepływu. Modele imitacji mogą być również deterministyczne i statystyczne. Ogólny cel modelowania procesu decyzyjnego został sformułowany wcześniej - ta definicja (obliczenie) wartości wybranego wskaźnika wydajności dla różnych strategii działania (lub przykładów wykonania przewidywanego systemu). Podczas opracowywania konkretnego modelu cel modelowania należy wyrafinować na podstawie użytego kryterium wydajności. Tak więc, cel modelowania jest zdefiniowany jako cel działania w ramach badań i planowanej metody korzystania z wyników badania. Na przykład, problematyczna sytuacja wymagająca podejmowania decyzji jest sformułowana w następujący sposób: Aby znaleźć opcję zbudowania sieci obliczeniowej, która miałaby minimalny koszt przy spełnieniu wymagań dotyczących wydajności i niezawodności. W tym przypadku cel modelowania jest znalezienie parametrów sieciowych zapewniających minimalną wartość PE, która jest rolą kosztów. Zadanie można formułować inaczej: z kilku opcji konfiguracji sieci komputerowej, wybierz najbardziej niezawodny. Tutaj jeden z wskaźników niezawodności jest wybrany jako PE (średnia operacja awarii, prawdopodobieństwo bezproblemowej pracy itp.), A cel symulacji jest porównawą ocenę opcji sieciowych dla tego wskaźnika. Przykłady przykładów pozwalają na wybór samego wskaźnika wydajności jeszcze nie definiuje jeszcze "architektury" przyszłego modelu, ponieważ na tym etapie koncepcja nie jest formułowana lub, jak mówią, model koncepcyjny systemu pod badanie nie jest zdefiniowane. II. Główne koncepcje teorii modelowania systemów gospodarczych i procesów 2.1 Sprawdzanie i rozwój systemów gospodarczych Modelowanie symulacyjne jest najpotężniejszą i uniwersalną metodą badawczą oraz ocena wydajności systemu, której zachowanie zależy od skutków czynników losowych. Takie systemy obejmują samolot i populację zwierząt oraz przedsiębiorstwo działające w warunkach wspomagających się stosunkami rynkowymi. Modelowanie imitacji opiera się na eksperymencie statystycznym (Metody Monte Carlo), której realizacja jest prawie niemożliwa bez użycia sprzętu komputerowego. Dlatego każdy model symulacyjny jest ostatecznie mniej lub bardziej złożony produkt oprogramowania. Oczywiście, jak każdy inny program, model symulacyjny można opracować na dowolnym uniwersalnym języku programowania, nawet w języku asemblera. Jednak w tym przypadku pojawiają się następujące problemy: Wiedza wymaga nie tylko obszaru przedmiotowego, do którego odnosi się system w ramach badań, ale także język programowania i na dość wysokim poziomie; Aby opracować konkretne procedury zapewniające eksperyment statystyczny (generacja przypadkowych wpływów, planowanie eksperymentu, przetwarzanie wyników) może zająć czas i siły przynajmniej niż rozwój samego modelu systemu. I wreszcie, jeszcze jeden jest najważniejszym problemem. W wielu praktycznych zadaniach zainteresowanie są nie tylko (a nie tak wiele) ocena ilościowa wydajności systemu, ile zachowań w taki czy inny sposób. W przypadku takiej obserwacji badacz musi mieć odpowiednie "okna przeglądania", które mogłyby być zamknięte, jeśli to konieczne, przeniesienie do innego miejsca, aby zmienić skalę i formę reprezentacji obserwowanych cech, itd. I bez czekania na koniec obecnego eksperymentu modelowego. Model symulacyjny w tym przypadku działa jako źródło odpowiedzi na pytanie: "Co się stanie, jeśli ...". Wdrożenie takich możliwości na uniwersalnym języku programowania jest bardzo trudne. Obecnie pojawi się wiele produktów oprogramowania, które umożliwiają modelowanie procesów. Takie pakiety obejmują: pielgrzym, GPS, Simplex i wiele innych. Jednocześnie, obecnie istnieje produkt na rosyjskim rynku technologii komputerowej, która pozwala bardzo skutecznie rozwiązać określone problemy, pakiet macierzyński zawierający narzędzie modelowania wizualnego SIMULINK. Simulink to narzędzie, które pozwala szybko symulować system i uzyskać oczekiwane efekty i porównać je z kosztami ich osiągnięcia. Istnieje wiele różnych typów modeli: fizycznych, analogowych, intuicyjnych itp. Specjalne miejsce wśród nich zajmują modele matematyczne, które według akademii A.a. Samara, "to największe zakłócenie rewolucji naukowej XX wieku". Modele matematyczne są podzielone na dwie grupy: analityczne i algo-rytmiczne (czasami nazywane symulacją). Obecnie nie można wymienić obszaru działalności człowieka, w której metody modelowania byłyby użyte w pewnym stopniu. Nie stanowi wyjątków i działalności gospodarczej. Jednak w dziedzinie naśladowania modelowania procesów gospodarczych niektóre trudności są nadal obserwowane. Naszym zdaniem ta okoliczność jest wyjaśniona z następujących powodów. Procesy gospodarcze występują w dużej mierze spontanicznie, niekontrolowane. Są one słabo udostępniane przez rząd wolicjonalny próby przez przywódców politycznych, publicznych i gospodarczych poszczególnych branż i gospodarki kraju jako całości. Z tego powodu systemy gospodarcze są słabo uczenia się i sformalizowane. Specjaliści w dziedzinie ekonomii, z reguły, mają niewystarczające szkolenia matematyczne w ogóle oraz w szczególności w kwestiach modelowania matematycznego. Większość z nich nie wie, jak formalnie opisać (sformalizowanie) obserwowanych procesów gospodarczych. To z kolei nie pozwala ustalić, czy model matematyczny w rozważanym systemie jest odpowiednie. Specjaliści w dziedzinie modelowania matematycznego, bez sformalizowanego opisu procesu gospodarczego do ich dyspozycji, nie mogą tworzyć odpowiedniego modelu matematycznego. Istniejące modele matematyczne, które są zwyczajowe, aby zadzwonić do modeli systemów gospodarczych, można podzielić na trzy grupy. Pierwsza grupa obejmuje modele, dość dokładnie odzwierciedlające jedną stronę pewnego procesu gospodarczego, który występuje w systemie stosunkowo małej skali. Z punktu widzenia matematyki są one bardzo proste stosunki między dwoma a trzema zmiennymi. Zwykle są to równania algebraiczne 2 lub trzeci stopień, jako ostatni ośrodek, system równań algebraicznych wymagających rozwiązania zastosowania metody iteracji (kolejne przybliżenia). Są one stosowane w praktyce, ale nie reprezentują INTE-RES z punktu widzenia specjalistów w dziedzinie modelowania matematycznego. Druga grupa może obejmować modele opisujące rzeczywiste procesy występujące w małych i średnich systemach gospodarczych narażonych na losowe i niepewne czynniki. Rozwój takich modeli wymaga akceptacji, aby umożliwić niepewności. Na przykład, musisz określić dystrybucję zmiennych losowych związanych z zmiennymi wejściowymi. Ta sztuczna operacja w znanym stepie powoduje wątpliwości co do wiarygodności wyników modelowania. Nie ma jednak innego sposobu stworzenia modelu matematycznego. Wśród modeli tej grupy modele tak zwanych masowych systemów konserwacyjnych były najczęstsze. Istnieją dwie odmiany tych modeli: analityczne i algorytmiczne. Modele analityczne nie uwzględniają działania czynników losowych i dlatego mogą być używane tylko jako modele pierwszego przybliżenia. Za pomocą modeli algorytmicznych proces w ramach badań może być opisany z dowolnym stopniem dokładności na poziomie zrozumienia przez Dyrektora Zadania. Trzecia grupa obejmuje modele dużych i bardzo dużych (makroekonomicznych) systemów: duże zakupy i przedsiębiorstwa przemysłowe oraz stowarzyszenia, sektory gospodarki narodowej i gospodarki kraju jako całość. Stworzenie matematycznego modelu systemu ekonomicznego takiej skali jest złożonym problemem naukowym, którego rozwiązaniem jest tylko główna instytucja badawcza. 2.2 Składniki modelu symulacji Symulacja numeryczna dotyczy trzech rodzajów wartości: dane źródłowe obliczone według wartości zmiennych i wartości parametrów. Na liściu macierzy Excel z tych wartości zajmują oddzielne obszary. Source Real Data, Próbki lub liczba liczb otrzymuje się z bezpośrednią obserwacją wewnętrzną lub eksperymentami. W ramach procedury symulacji pozostają niezmienione (jasne jest, że jeśli to konieczne, możesz dodać lub zmniejszyć zestawy wartości) i odgrywać podwójną rolę. Niektóre z nich (niezależne zmienne środowiskowe, X) służą jako podstawa do obliczania zmiennych modelowych; Najczęściej jest to charakterystyka czynników naturalnych (czas, fotoperiod, temperatura, obfitość paszy, dawka toksykalnego, resetowania objętości zanieczyszczeń itp.). Inną częścią danych (zmienne zależne obiektu, y) jest charakterystyczną cechą państwa, reakcji lub zachowania przedmiotu badań, które uzyskano w pewnych warunkach zgodnie z działaniem zarejestrowanych czynników środowiskowych. W sensie biologicznym pierwsza grupa wartości nie zależy od drugiego; Wręcz przeciwnie, zmienne obiektu zależą od zmiennych środowiskowych. Na arkuszu Excel dane są wprowadzane z klawiatury lub z pliku w normalnym trybie pracy za pomocą arkusza kalkulacyjnego. Modelowe dane rozliczeniowe reproduluje teoretycznie przemyślany stan obiektu, który jest określony przez poprzedniego stanu, poziom obserwowanych czynników środowiskowych i charakteryzuje się kluczowymi parametrami badanego procesu. W zwykłym przypadku, przy obliczaniu wartości modelowych (YM I) za każdym etapie czasu (I), stosuje się parametry (a), charakterystyczne dla poprzedniego stanu (YMI -1) i obecnych poziomów czynników środowiskowych (XI ): Y m i \u003d f (a, y m i-1, x i, i), gdzie () jest przyjętą formą stosunku parametrów i zmiennych medium, rodzaju modelu, \u003d 1, 2, ... T lub I \u003d 1, 2, ... n. Obliczenia charakterystyki systemu zgodnie z formułami modelowymi za każdym etapie czasu (dla każdego stanu) umożliwiają utworzenie tablicy modeli wyraźnych zmiennych (YM), co powinno powtórzyć strukturę tablicy rzeczywistych zmiennych zależnych (Y ), który jest niezbędny do kolejnego ustawienia parametrów modelu. Wzory do obliczenia zmiennych modelowych są wprowadzane do komórek arkusza Excela ręcznie (patrz Przydatne wycinki). Parametry modelu (a) tworzą trzecią grupę wartości. Wszystkie parametry mogą być reprezentowane jako wiele: \u003d (A 1, A 2, ..., J, ..., A M), gdzie j jest numerem parametru, m alnie całkowita liczba parametrów, i zorganizuj oddzielny blok. Oczywiste jest, że liczba parametrów jest określona przez strukturę metod formuł modelowych. Biorąc oddzielną pozycję na arkuszu Excela, odgrywają największą rolę w modelowaniu. Parametry są przeznaczone do scharakteryzowania najbardziej stworzenia, mechanizm wdrażania obserwowanych zjawisk. Parametry muszą mieć znaczenie biologiczne (fizyczne). W pewnych zadaniach należy porównać, że można porównać parametry obliczone dla różnych tablic danych. Czasami muszą towarzyszyć ich błędy statystyczne. Związek między składnikami systemu symulacji stanowią jedność funkcjonalną, koncentrowała się na osiągnięciu wspólnego celu - oceny parametrów modelu (Rys. 2.6, Tabela 2.10). W realizacji poszczególnych funkcji wskazanych przez strzałki, kilka elementów jest jednocześnie. Aby nie zaśmiecać obrazu, diagram nie odzwierciedla bloków przedstawicielstwa graficznego i randomizacji. System symulacji jest przeznaczony do obsługi wszelkich zmian w wzorach modelowych, które, jeśli to konieczne, można dokonać naukowca. Podstawowe projekty systemów imitacji, a także możliwe sposoby ich rozkładu i integracji przedstawiono w ramach systemów symulacyjnych. symulacja symulacji Wiersz gospodarczy III. Podstawy symulacji 1 model imitacji i jego funkcje Modelowanie symulacyjne jest rodzajem modelowania analogowego realizowanego przez zestaw narzędzi matematycznych, specjalnych imitujących programów komputerowych i technologii programistycznych, które pozwalają wykonać ukierunkowane badanie struktury i funkcji rzeczywistego złożonego procesu w pamięci komputera w " Tryb imitacji ", aby zoptymalizować niektóre parametry IT. Model symulacyjny jest modelem ekonomicznym i matematycznym, którego badanie przeprowadza się metodami eksperymentalnymi. Eksperyment obserwuje się dla wyników obliczeń w różnych wartościach wprowadzonych zmiennych egzogennych. Model symulacyjny jest modelem dynamicznym ze względu na fakt, że ma taki parametr w miarę upływu czasu. Model symulacyjny jest również nazywany specjalnym pakietem oprogramowania, który pozwala naśladować działania złożonego obiektu. Wygląd modelowania imitacji był związany z "nową falą" w modelowaniu gospodarki-tematyczne. Problemy nauki gospodarczej i praktyki w dziedzinie zarządzania i edukacji gospodarczej z jednej strony oraz wzrost wydajności komputerów, z drugiej strony, spowodowały, że pragnienie rozszerzenia ramy "klasycznych" metod gospodarczych i matematycznych . Niektóre rozczarowanie ma możliwości modeli regulacyjnych, równowagowych, optymalizacyjnych i teoretycznych i do gry, na początku zasłużenie przyciągniętego przez fakt, że przyczyniają się do wielu problemów z zakresem zarządzania gospodarczemu sytuacji logicznej jasności i obiektywności, a także prowadzić do "rozsądnej" (zrównoważony, optymalny, kompromisowy) rozwiązanie. Nie zawsze było możliwe do całkowitego zrozumienia celów a priori, a ponadto sformalizowanie kryterium optymalizacji i (lub) ograniczeń dotyczących dopuszczalnych rozwiązań. Dlatego wiele prób nadal stosuje takie metody zaczęły uzyskać niedopuszczalne, na przykład niezrealizowane (choć optymalne) rozwiązania. Pokonywanie trudności wynikających ze ścieżki niepowodzenia w pełni sformalizowaniu (jak jest wykonywane w modelach regulacyjnych) procedury przyjmowania rozwiązań społeczno-gospodarczych. Preferencje stało się rozsądną syntezą możliwości intelektualnych ekspertów i relikwii informacji komputera, który jest zwykle wdrażany w dialogach. Ten sam kurs w tym kierunku jest przejście do "półmatycznych" wielu kryteriów modeli ludzkich maszyn, drugi jest przeniesieniem środka ciężkości z modeli Suppriant skupionych na programie "Warunki - decyzję", dla modeli opisowych, które Daj odpowiedź na pytanie "Co się stanie, jeśli ..". Symulacja symulacji jest zwykle uciekana w przypadkach, w których zależności między elementami symulowanych systemów są tak kompleksowe i nie są pewni, że nie są one podatne na formalny opis w języku nowoczesnej matematyki, tj. Korzystanie z modeli analitycznych. Tak więc, naśladując modelowanie naukowców złożonych systemów są zmuszeni do stosowania, gdy metody czysto analityczne nie mają zastosowania lub niedopuszczalne (ze względu na złożoność odpowiednich modeli). Podczas symulowania modelowania procesy dynamiczne oryginalnego systemu są zastępowane procesami przez symulowany algorytm w modelu abstrakcyjnym, ale z przestrzeganiem tych samych stosunków trwania trwania, sekwencje logiczne i czasowe, jak w rzeczywistym systemie. Dlatego metoda symulacji może być nazywana algorytmicznym lub działaniem. Nawiasem mówiąc, taka nazwa byłaby bardziej udana, ponieważ imitacja (przetłumaczona z latynoskiej - imitacji) jest rozmnażanie wszelkich sztucznych środków, tj. Modelowanie. W związku z tym nazwa "modelowania symulacji" jest szeroko stosowana, jest tautologiczna. W procesie symulującego funkcjonowanie systemu w ramach badań, jak w eksperymencie z samym pierwotnym, niektóre zdarzenia i stany są rejestrowane, na których obliczane są niezbędne cechy funkcjonowania badanego systemu. W przypadku systemów, na przykład konserwacji informacji i obliczeń, ponieważ takie właściwości dynamiczne można zdefiniować: Wydajność urządzeń przetwarzania danych; Długość kolejek serwisowych; Czas oczekiwania na usługi w kolejkach; Liczba aplikacji pozostawiła system bez konserwacji. W modelowaniu symulacji, procesy dowolnego stopnia złożoności można odtwarzać, jeśli istnieje opis określony w dowolnej formie: wzory, tabele, wykresy, a nawet ustnie. Główną cechą modeli imitacji jest to, że proces badaniem jest "skopiowany" na maszynie komputerowej, więc modele imitacji, w przeciwieństwie do modeli analitycznych pozwalają: Weź pod uwagę w modelach ogromna liczba czynników bez brutalnych uproszczeń i założeń (a zatem zwiększyć adekwatność modelu badanego systemu); Wystarczy wziąć pod uwagę współczynnik niepewności w modelu spowodowanym losowym charakterem wielu zmiennych modeli; Wszystko to pozwala na dokonanie naturalnego wniosku, że modele imitacji można utworzyć dla szerszej klasy obiektów i procesów. 2 Istota symulacji Istota modelowania imitacji jest ukierunkowanym eksperymentowaniem z modelem symulacyjnym przez "Odtwarzanie" na nim różnych opcji dla systemu z odpowiednią analizą ekonomiczną. Natychmiast zauważamy, że wyniki takich eksperymentów i odpowiedniej analizy ekonomicznej powinny być wyznaczone w postaci tabel, wykresów, nomogramów itp., Co znacznie upraszcza proces decyzyjny w oparciu o wyniki modelowania. Listing powyżej wielu zalet modeli imitacji i symulacji symulacji, odnotowujemy również ich niedociągnięcia, które należy pamiętać w praktycznym wykorzystaniu symulacji. To: Brak dobrze zorganizowanych zasad budowania modeli imitacji, co wymaga znacznego badania każdego konkretnego przypadku jego budowy; Trudności metodologiczne znalezienia optymalnych rozwiązań; Zwiększone wymagania dotyczące prędkości komputera, na którym wdrażane są modele imitacji; Trudności związane z gromadzeniem i przygotowaniem reprezentatywnych danych statystycznych; Wyjątkowość modeli imitacji, która nie pozwala na używanie gotowych produktów oprogramowania; Złożoność analizy i zrozumienia wyników uzyskanych w wyniku eksperymentu obliczeniowego; Dość wysoki czas i koszty pieniędzy, zwłaszcza podczas wyszukiwania optymalnego zachowania systemu w badaniu. Numer i istota wymienionych niedociągnięć jest bardzo imponująca. Jednakże, biorąc jednak pod uwagę duże zainteresowanie naukowymi w tych metodach i ich niezwykle intensywnym rozwoju w ostatnich latach, może być pewnie przyjęty, że wiele z powyższych niedoborów modelowania imitacji można wyeliminować zarówno w koncepcyjnym, jak i stosowanym planie. Symulacja symulacji kontrolowanego procesu lub zarządzanego obiektu to wysoka technologia informacyjna, która zapewnia dwa typy działań wykonanych przy użyciu komputera: ) prace nad tworzeniem lub modyfikacją modelu symulacji; ) Działanie modelu symulacji i interpretacji wyników. Symulacja procesów gospodarczych jest zwykle stosowana w dwóch przypadkach: Aby zarządzać złożonym procesem biznesowym, gdy model symulacyjny zarządzanego obiektu ekonomicznego jest wykorzystywany jako narzędzie do narzędzia% w obwodzie systemu sterowania adaptacyjnego utworzonego na podstawie technologii informacyjnej; Podczas prowadzenia eksperymentów z dyskretnymi ciągłymi modelach złożonych przedmiotów gospodarczych do uzyskania i śledzenia ich dynamiki w sytuacjach nadzwyczajnych związanych z ryzykiem, których naturalne modelowanie jest niepożądane lub niemożliwe. Można odróżnić następujące typowe zadania, rozwiązane przez symulację przy użyciu modelowania imitacji podczas zarządzania przedmiotami ekonomicznymi: Modelowanie procesów logistycznych w celu zdefiniowania parametrów tymczasowych i wartościowych; Zarządzanie procesem wdrażania projektu inwestycyjnego na różnych etapach cyklu życia, biorąc pod uwagę możliwe ryzyko i taktyki perspektywy pieniężnej; Analiza procesów rozliczeniowych w pracach sieci instytucji kredytowych (w tym wniosek do procesów wzajemnych rozliczeń w kontekście rosyjskiego systemu bankowego); Prognozowanie wyników finansowych przedsiębiorstwa przez określony czas (z analizą salda salda na rachunkach); Reengineering biznesowy z tytułu przerwanego przedsiębiorstwa (zmiana struktury i zasobów bankrutujących przedsiębiorstwa, po czym możliwe jest, aby prognozować podstawowe wyniki finansowe za pomocą modelu symulacji i dostarczyć zaleceń w sprawie wykonalności tego lub tej opcji rekonstrukcja, inwestycje lub pożyczki do działalności przemysłowej); System symulacji, który zapewnia utworzenie modeli do rozwiązywania wymienionych zadań musi mieć następujące właściwości: Możliwość wykorzystania programów imitacji wraz ze specjalnymi modelach gospodarczych i matematycznych i metod opartych na teorii zarządzania; Instrumentalne metody prowadzenia analizy strukturalnej złożonego procesu gospodarczego; Możliwość modelowania materiałów, procesów monetarnych i informacji i przepływów w ramach jednego modelu, ogólnie, czasem modelu; Możliwość wprowadzenia trwałego trybu udoskonalenia po otrzymaniu danych wyjściowych (podstawowe wskaźniki finansowe, charakterystyki czasowe i przestrzenne, parametry ryzyka itp.) I ekstremalny eksperyment. Wiele systemów gospodarczych jest zasadniczo systemem usług masowych (SMO), tj. Systemy, w których z jednej strony mają wymóg przeprowadzenia jakichkolwiek usług, a z drugiej strony istnieją zadowolenie z tych wymagań. IV. Praktyczna część 1 oświadczenie o problemach. Zbadaj dynamikę wskaźnika ekonomicznego na podstawie analizy jednowymiarowej serii czasowych. W ciągu dziewięciu kolejnych tygodni, żądanie y (t) (M Mu Ruble) odnotowano na zasobach kredytowych firmy finansowej. Seria czasu Y (t) tego wskaźnika jest pokazana w tabeli. Wymaga: Sprawdź nieprawidłowe obserwacje. Zbuduj liniowy model Y (T) \u003d A 0 + A 1 t, których parametry do oceny MNC (Y (T)) - obliczone, wzorowane wartości serii czasu). Oceń adekwatność konstruowanych modeli przy użyciu właściwości niezależności składnika resztkowego, szans i zgodności z normą normalną (przy stosowaniu kryterium R / S, weź tabelaryczne granice z 2,7-3,7). Oceń dokładność modeli w oparciu o zastosowanie średniego względnego błędu przybliżenia. Przez dwie modele zbudowane przez prognozę popytu na najbliższe dwa tygodnie (przedział zaufania prognozy oblicza się w prawdopodobieństwie trupa P \u003d 70%) Rzeczywiste wartości wskaźnika, modelowania i prognozowania wyników są graficznie. 4.2 Rozwiązanie zadania jeden). Obecność niezbojowych obserwacji prowadzi do zniekształcenia wyników modelowania, więc konieczne jest upewnienie się, że nie ma nieprawidłowych danych. Aby to zrobić, używamy metody Irwin i znajdź charakterystyczny numer () (tabela 4.1). ; Obliczone wartości są porównywane z wartościami tabeli kryterium Irvine, a jeśli okażą się, aby były bardziej tabelaryczne, a odpowiednia wartość poziomu wiersza jest uważana za anomalowatą. Dodatek 1 (Tabela 4.1) Wszystkie uzyskane wartości porównano z wartościami tabel, nie przekracza ich, czyli nie ma nieprawidłowych obserwacji. ) Aby skonstruować model liniowy, których parametry do oceny MNC (obliczone, modelowane wartości serii czasowych). Aby to zrobić, użyj analizy danych w programie Excel Dodatek 1 ((rys. 4.2) .ris 4.1) Wynik analizy regresji jest zawarty w tabeli. Dodatek 1 (Tabela 4.2 i 4.3.) Na karcie drugiej kolumny. 4.3 zawiera współczynniki równania regresji A 0, A 1, w trzecim kolumnie - standardowe błędy współczynników równania regresji, aw czwartym - T - Statystyki używane do weryfikacji znaczenia współczynników równania regresji . Równanie regresji (popyt na zasoby kredytowe) od (czas) ma formę Dodatek 1 (Rys. 4.5) 3) Oceń adekwatność wybudowanych modeli. 1. Sprawdź niezależność (brak autokorelacji) z D - Darbina - kryterium WATSON według formuły: Dodatek 1 (Tabela 4.4) Dlatego Obliczona wartość D wprowadza interwał od 0 do D 1, tj. W odstępie od 0 do 1,08 nieruchomość niezależności nie jest wykonywana, poziomy rzędu pozostałości zawierają autokorelację. W związku z tym model w tym kryterium jest niewystarczający. 2. Sprawdź losowe poziomy pozostałości wiersza, będzie prowadzić na podstawie kryterium punktów zwrotnych. P\u003e Liczba punktów obrotowych wynosi 6. Dodatek 1 (Rys. 4.5) Nierówność jest wykonywana (6\u003e 2). W konsekwencji przeprowadza się dokładność wypadku. Model w tym kryterium jest odpowiedni. 3. Zgodność z liczbą pozostałości do normalnego prawa dystrybucji określać z RS - kryteria: Maksymalny poziom liczby pozostałości, Minimalny poziom liczby pozostałości, Odchylenie RMS, Obliczona wartość wchodzi w związku z interwałem (2,7-3.7), dlatego występuje właściwość normalności dystrybucyjnej. Model w tym kryterium jest odpowiedni. 4. Sprawdź równość zero matematyczne oczekiwania rzędu pozostałości. W naszym przypadku, zatem hipoteza równości matematycznego oczekiwania wartości serii resztkowej jest ważna. Tabela 4.3 Zebrano analizę danych wielu pozostałości. Dodatek 1 (Tabela 4.6) 4) Oceń dokładność modelu na podstawie stosowania średniego względnego błędu przybliżenia. Aby oszacować dokładność uzyskanego modelu, używamy wskaźnika błędu względnego przybliżenia, który jest obliczany przez wzoru: Obliczanie względnego błędu przybliżenia Dodatek 1 (Tabela 4.7) Jeśli błąd obliczony przez wzór nie przekracza 15%, dokładność modelu jest uważana za dopuszczalną. 5) Zgodnie z konstruowanym modelem prognoza popytu na najbliższe dwa tygodnie (przedział zaufania prognozy oblicza się podczas prawdopodobieństwa zaufania p \u003d 70%). Używamy funkcji Excel Studset. Dodatek 1 (Tabela 4.8) Aby zbudować prognozę interwałów, obliczymy przedział zaufania. W związku z tym podejmiemy wartość poziomu istotności, prawdopodobieństwo ufności wynosi 70%, a kryterium ucznia Szerokość przedziału ufności jest obliczana przez wzór: Oblicz górne i dolne limity prognozy (tab. 4.11). Dodatek 1 (Tabela 4.9) 6) Wyniki faktyczne wskaźnika, modelowania i prognozowania są graficznie. Przekształcimy harmonogram wyboru, dodając jego dane projekcji. Dodatek 1 (Tabela 4.10) Wniosek Model gospodarczy jest zdefiniowany jako system powiązanych zjawisk ekonomicznych, wyrażony w cechach ilościowych i przedstawiony w systemie równań, tj. Jest to system sformalizowanego opisu matematycznego. W celu ukierunkowanego badania zjawisk ekonomicznych i procesów i formułowania konkluzji ekonomicznej - zarówno teoretyczne, jak i praktyczne, wskazane jest stosowanie metody modelowania matematycznego. Szczególnie interesujący objawia się metody i środki symulacji, co wiąże się z poprawą technologii informacyjnych stosowanych w systemach symulacyjnych: rozwój powłok graficznych do projektowania modeli i interpretacji wyników modelowania, przy użyciu funduszy multimedialnych, rozwiązań internetowych itp . W analizie ekonomicznej symulacja jest najbardziej wszechstronnym instrumentem w dziedzinie planowania finansowego, strategicznego, planowania biznesowego, zarządzania produkcją i projektowaniem. Modelowanie matematyczne systemów gospodarczy Najważniejsza właściwość modelowania matematycznego jest jego wszechstronność. Metoda ta pozwala utworzyć różne warianty swojego modelu w projektowaniu i rozwoju systemu ekonomicznego, aby przeprowadzić wiele eksperymentów z uzyskanymi wariantami modelu w celu ustalenia (na podstawie określonych kryteriów funkcjonowania systemu) Parametry utworzone przez system niezbędny do zapewnienia jego wydajności i niezawodności. Nie wymaga nabycia lub produkcji jakiegokolwiek sprzętu lub sprzętu do wykonywania następnych obliczeń: konieczne jest po prostu zmienić wartości liczbowe parametrów, początkowe warunki i tryby działania badanych złożonych systemów gospodarczych. Modelowanie matematyczne metodologicznie obejmuje trzy główne typy: modelowanie modyfikacji analitycznej, symulacji i łącznej (imitacji analitycznej). Rozwiązanie analityczne, jeśli to możliwe, daje bardziej kompletny i wizualny obraz, co pozwala uzyskać zależność wyników modelowania z zestawu danych źródłowych. W tej sytuacji należy przenieść się do stosowania modeli symulacyjnych. Model symulacyjny w zasadzie pozwala odtworzyć cały proces funkcjonowania systemu gospodarczego z zachowaniem struktury logicznej, relacji między zjawiskami a sekwencją ich przepływu w czasie. Modelowanie symulacyjne umożliwia uwzględnienie dużej liczby rzeczywistych części funkcjonowania symulowanego obiektu i jest niezbędne na końcowych etapach systemu tworzenia systemu, gdy wszystkie pytania strategiczne są już rozwiązane. Można zauważyć, że modelowanie symulacji ma rozwiązać problemy obliczania charakterystyki systemowej. Liczba opcji, które należy oszacować, musi być stosunkowo niewielka, ponieważ wdrożenie modelowania symulacji dla każdego przykładu wykonania systemu gospodarczego wymaga znacznych zasobów obliczeniowych. Faktem jest, że główną cechą modelowania imitacji jest fakt, że konieczne jest stosowanie metod statystycznych do uzyskania znaczących wyników. Takie podejście wymaga wielokrotnego powtórzenia naśladowanego procesu ze zmieniającymi wartościami czynników losowych, a następnie uśrednianie statystyczne (przetwarzanie) wyników poszczególnych pojedynczych obliczeń. Wykorzystanie metod statystycznych, nieuniknionych w modelowaniu symulacji, wymaga dużych wydatków czasu maszyny i zasobów obliczeniowych. Inną wadą metody symulacji jest fakt, że stworzenie wystarczająco znaczących modeli systemu ekonomicznego (oraz na tych etapach tworzenia systemu ekonomicznego, gdy potrzebne są modelowanie symulacyjne, potrzebne są bardzo szczegółowe i znaczące modele) Istnieją istotne wysiłki koncepcyjne i programisty wymagany. Modelowanie połączonych pozwala na połączenie zalet analitycznych i symulacji. Aby zwiększyć niezawodność wyników, należy zastosować łączne podejście na podstawie kombinacji metod analitycznych i symulacyjnych. W tym przypadku należy zastosować metody analityczne na etapach analizowania właściwości i syntezy systemu optymalnego. Zatem z naszego punktu widzenia, potrzebny jest system kompleksowych narzędzi do nauki i metod zarówno analitycznej, jak i symulacji. Organizacja studiów praktycznych studenci studiuje sposoby rozwiązywania zadań optymalizacji, które są zredukowane do logowania liniowe. Wybór tej metody modelowania wynika z prostoty i przejrzystości zarówno znaczącej preparatu odpowiednich zadań, jak i jak je rozwiązać. W procesie wykonywania prac laboratoryjnych studenci rozwiązują następujące typowe zadania: zadanie transportu; zadanie dystrybucji zasobów przedsiębiorstwa; Zadaniem umieszczenia sprzętu itp. 2) Badanie fundamentów modelowania symulacji przemysłowych i nieprodukcyjnych systemów konserwacyjnych masowych w środowisku Światowego GPSS (świat ogólnego przeznaczenia Symulacji). Rozważane są kwestie metodologiczne i praktycznych tworzenia i wykorzystania modeli imitacji w analizie i projektowaniu złożonych systemów gospodarczych i podejmowania decyzji w wykonywaniu działań komercyjnych i marketingowych. Sposoby opisywania i sformalizowania symulowanych systemów, etapów i technologii do budowy i stosowania modeli imitacji, badane są kwestie ukierunkowanych badań eksperymentalnych w modelach symulacyjnych. Lista używanych literatury Konserwacja 1. Akulich I.L. Programowanie matematyczne w przykładach i zadaniach. - M.: Wyższa szkoła, 1986 2. VLASOV M.P., Shimko P.D. Symulacja korzyści procesów. - Rostov-on-Donu, Phoenix - 2005 (podręcznik elektroniczny) 3. Javorsky V.v., Amirov A.J. Informatyki gospodarcze i systemy informacyjne (warsztaty laboratoryjne) - Astana, Foliant, 2008 4. Simonovich S.v. Informatyka, Piotr, 2003 5. Vorobyov n.n. Teoria gier dla ekonomistów - Cybernetyka. - m.: Science, 1985 (podręcznik elektroniczny) 6. Alesinskaya t.v. Metody i modele ekonomiczne i matematyczne. - Tagan Rog, 2002 (podręcznik elektroniczny) 7. Gershgnorn A.S. Programowanie matematyczne i jego zastosowanie w obliczeniach ekonomicznych. -M. Gospodarka, 1968. dodatkowo 1. Darbinyan M.m. Rezerwy towarów w handlu i ich optymalizacji. - M. Gospodarka, 1978 2. Johnston d.Zh. Metody ekonomiczne. - M.: Finanse i statystyki, 1960 3. Epishin Yu.g. Metody ekonomiczne i matematyczne i planowanie współpracy konsumenckiej. - M.: Gospodarka, 1975 4. Zhitnikov S.a., Birzhanova Z.n., Ashirbekova B.M. Metody i modele ekonomiczne i matematyczne: samouczek. - Karaganda, Publisher Ku, 1998 5. Zamkov O.O., Tolstopyenko A.v., Cheremnyy Yu.n. Metody matematyczne w gospodarce. - m.: DIS, 1997 6. Ivanilov Yu.P., Lotov A.v. Metody matematyczne w gospodarce. - M.: Science, 1979 7. Kalinina V.N., Pankin A.v. Statystyki matematyczne. M.: 1998. 8. Kumaev V.a. Gospodarka matematyczna. M., 1998. 9. Kremer N.SH., Putko B.a., Trishin I.m., Friedman M.n. Badanie operacji w gospodarce. Tutorial - M.: Banki i giełdy, Uniti, 1997 10. Spirin A.a:, Fomin G.P. Metody i modele gospodarcze i matematyczne w handlu. - M.: Ekonomia, 1998 Załącznik 1 Tabela 4.1.
Tabela 4.2.
Czynniki Standardowy błąd t-Statistics. Skrzyżowanie Y. 0 Tabela 4.3. Zawarcie pozostałości
Pozostałość do wniosku Obserwacja Przewidywano y. Tabela 4.6.
Właściwość sprawdzona Używane statystyki nazwa wartość Niezależność d-kryterium niewystarczający Wypadek Kryteria punktów obrotowych adiquitat. Normalność Kryterium RS. adiquitat. Średnia \u003d 0? student statystyki T adiquitat. Wniosek: Model statystyk nieodpowiedni Tabela 4.7.
Przewidywano y. Tabela 4.9. Prognoza tabeli 
Figura 4 przedstawia charakterystykę rozkładu gamma, a także wykres funkcji gęstości dla różnych wartości tych cech.  Jest to dystrybucja posiadająca asymetryczny wygląd. Zajmuje pozycję pośrednią między wykładniczym a normalnym. Gęstość prawdopodobieństwa rozkładu na eolland wydaje się formuła:
Jest to dystrybucja posiadająca asymetryczny wygląd. Zajmuje pozycję pośrednią między wykładniczym a normalnym. Gęstość prawdopodobieństwa rozkładu na eolland wydaje się formuła:
Figura 5 przedstawia charakterystykę dystrybucji trójkątnej i wykres funkcji gęstości prawdopodobieństwa.
Jeśli rozważymy zależność jednej z cech systemu η v (x I) jako funkcja tylko jednej zmiennej x I. (Rys. 7), a następnie w ustalonych wartościach x I. Otrzymamy różne wartości η v (x I)
. 
Figa
.8
Bagażnik
formularz
Microsoft Developer Studio.

Rys. 9 Wykres opóźnienia w węźle "Konto rozliczeniowe".
Wyślij dobrą pracę w bazie wiedzy jest proste. Użyj poniższego formularza
Podobne dokumenty

 ,
, ![]() .
.
![]() ,
,
![]()
 ,
, ![]()
![]()
![]() gdzie
gdzie ![]()
![]() równa 1,12.
równa 1,12. gdzie
gdzie
![]() (Znajdź z tabeli 4.1)
(Znajdź z tabeli 4.1)

