Disposizioni di test di base. Le principali disposizioni della teoria classica dei test
Leggi anche
Cos'è il test
In conformità con IEEE STD 829-1983 Test - Questo è un processo per analizzare il software finalizzato a identificare le differenze tra le sue proprietà effettivamente esistenti e richieste (difetti) e di valutare le proprietà del software.
Secondo Gost R ISO IEC 12207-99 nel ciclo di vita del software, tra gli altri processi ausiliari di verifica, certificazione, analisi e audit congiunti e audit sono determinati. Il processo di verifica è il processo di determinare che i prodotti del software operano nel pieno rispetto dei requisiti o delle condizioni implementate nei lavori precedenti. Questo processo può includere analisi, verifica e test (test). Il processo di certificazione è il processo di determinazione della completezza della conformità dei requisiti stabiliti creati dal sistema o del prodotto software per essere il loro funzionario previsto. Il processo di analisi congiunta è il processo di valutazione degli stati e, se necessario, i risultati del lavoro (prodotti) sul progetto. Il processo di audit è il processo di determinazione della conformità con i requisiti, i piani e le condizioni del contratto. Nella quantità di questi processi e compensare ciò che è comunemente chiamato test.
I test si basano su procedure di prova con dati di ingresso specifici, condizioni iniziali e risultati previsti sviluppati per uno scopo specifico, come il controllo di un programma separato o verificare la conformità a un determinato requisito. Le procedure di prova possono controllare i vari aspetti del funzionamento del programma, dal corretto funzionamento di una funzione separata prima dell'adeguata implementazione dei requisiti aziendali.
Quando si esegue un progetto, è necessario tenere conto, in conformità con quali standard e i requisiti saranno testati dal prodotto. Quali strumenti saranno (se ci sono) vengono utilizzati per cercare e documentare i difetti trovati. Se ricordi di testare fin dall'inizio del progetto, il test del prodotto che è stato sviluppato non fornirà spiacevoli sorprese. Quindi, la qualità del prodotto è probabile che sia piuttosto elevata.
Ciclo e test di vita del prodotto
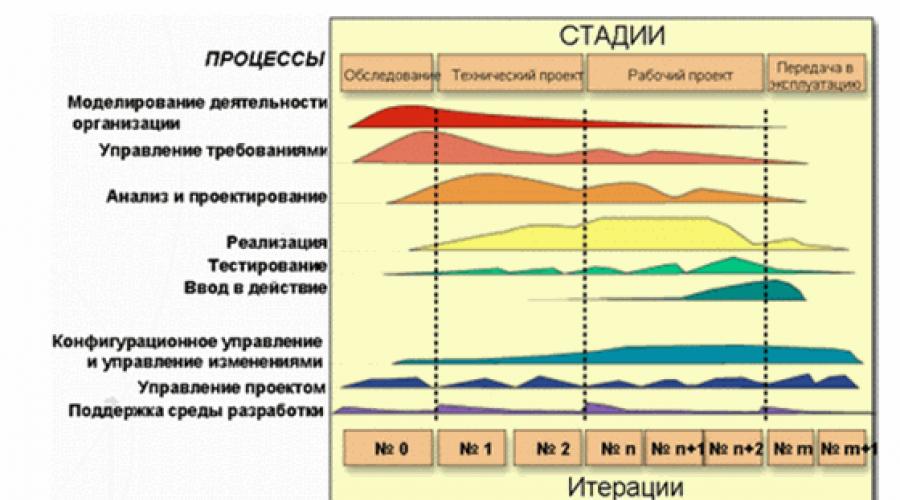
Nel nostro tempo, è utilizzato dai processi iterativi dello sviluppo del software, in particolare, la tecnologia RUP - Processo unificato razionale(Fig. 1). Quando si utilizza questo approccio, il test cessa di essere il processo "sul cucito", che funziona dopo che i programmatori hanno scritto tutto il codice necessario. Lavorare sui test inizia con la fase iniziale di identificazione dei requisiti per il prodotto futuro e si integra da vicino con le attività correnti. E fa nuove esigenze per i tester. Il loro ruolo non è semplicemente ridotto per identificare gli errori il più pienamente possibile e il prima possibile. Dovrebbero partecipare al processo generale di identificare ed eliminare i rischi più significativi del progetto. A tal fine, lo scopo dei test e dei metodi per il suo successo è determinato per ciascuna iterazione. E alla fine di ciascuna iterazione è determinato quanto questo obiettivo si ottiene se sono necessari ulteriori test e se non è necessario modificare i principi e gli strumenti di prova. A loro volta, ciascun difetto rilevato deve passare attraverso il proprio ciclo di vita.
Fico. 1. Ciclo di vita del prodotto su RUP
Il test viene solitamente effettuato da cicli, ciascuno dei quali ha un elenco specifico di attività e scopi. Il ciclo di prova può coincidere con iterazione o corrispondere alla sua parte specifica. In genere, il ciclo di prova viene eseguito per un assemblaggio di sistema specifico.
Il ciclo di vita del prodotto del software è costituito da una serie di iterazioni relativamente brevi (figura 2). Iterazione è un ciclo completo di sviluppo che conduce al rilascio del prodotto finale o parte della sua versione abbreviata, che si espande dalla iterazione all'iterazione in modo che, alla fine, diventando un sistema finito.
Ogni iterazione include, come regola, compiti di pianificazione del lavoro, analisi, progettazione, implementazione, test e valutazione dei risultati raggiunti. Tuttavia, i rapporti di questi compiti possono cambiare in modo significativo. In conformità con il rapporto tra vari compiti nelle iterazioni, sono raggruppati in fasi. Nella prima fase - l'inizio - l'attenzione principale è rivolta ai compiti di analisi. Nelle iterazioni del secondo sviluppo - lo sviluppo - l'attenzione è sulla progettazione e il test delle decisioni chiave del progetto. Nella terza fase - la costruzione è la quota più ampia di compiti di sviluppo e test. E nell'ultima fase - trasmissione - vengono risolti ai più alti compiti di test e trasferimento del sistema al cliente.

Fico. 2. Iterazioni del ciclo di vita del prodotto software
Ogni fase ha i propri obiettivi specifici nel ciclo di vita del prodotto ed è considerato fatto quando questi obiettivi sono raggiunti. Tutte le iterazioni, ad eccezione di possono essere, le iterazioni dell'inizio della fase sono completate creando la versione funzionante del sistema sviluppato.
Categorie di prova
I test differiscono in modo significativo in compiti risolti con il loro aiuto, e secondo la tecnica utilizzata.
| Categorie di prova | Descrizione Categorie | Tipi di test |
|---|---|---|
| Test attuali | Un insieme di test eseguiti per determinare le prestazioni delle nuove funzionalità aggiunte del sistema. |
|
| Test di regressione | Lo scopo dei test di regressione è verificare che l'aggiunta al sistema non abbia ridotto le sue capacità, cioè. Il test viene effettuato in base ai requisiti che sono già stati completati prima di aggiungere nuove funzionalità. |
|
Test di sottocategoria.
| Test di sottocategoria. | Descrizione del tipo di test | Test di sottospecie |
|---|---|---|
| Test di stress | Viene utilizzato per testare tutti senza eccezioni delle funzioni dell'applicazione. In questo caso, la sequenza di test della funzione non ha importanza. |
|
| Test cicli di business. | Viene utilizzato per testare le funzioni dell'applicazione nella sequenza della loro chiamata da parte dell'utente. Ad esempio, l'imitazione di tutte le azioni contabile per il 1 ° trimestre. |
|
| Test di stress |
Usato per il test Performance dell'applicazione. Lo scopo di questo test è determinare il quadro del funzionamento stabile dell'applicazione. Con questo test, tutte le funzioni disponibili sono chiamate. |
|
Tipi di test
Test dell'unità (Test modulari): questa specie implica il test dei singoli moduli di applicazione. Per ottenere il risultato massimo, il test viene eseguito simultaneamente con lo sviluppo dei moduli.
Test funzionale - Lo scopo di questo test è quello di garantire il corretto funzionamento dell'oggetto di test. Viene testato correttamente la navigazione di un oggetto, nonché l'input, l'elaborazione e l'output dei dati.
Test del database - Controllare le prestazioni del database con il normale funzionamento dell'applicazione, nei momenti di modalità sovraccarico e multiplayer.
Test dell'unità
Per OOP, la solita organizzazione dei test modulari è quella di testare i metodi di ciascuna classe, quindi la classe di ogni confezione I.T.D. A poco a poco, rivolgiamo a testare l'intero progetto e i test precedenti sono il tipo di regressione.
Nei compiti di output, i dati di test includono procedure di prova, dati di input, test di esecuzione del codice, output. Quanto segue è un tipo di documentazione di uscita.
Test funzionale
I test funzionali dell'oggetto di prova sono previsti ed eseguiti sulla base dei requisiti di prova specificati nella fase di definizione. I requisiti sono le regole aziendali, i grafici dell'uso del caso, le funzioni aziendali, nonché se ci siano grafici di attività. Lo scopo dei test funzionali è quello di verificare la conformità dei componenti grafici sviluppati requisiti stabiliti.
Questo tipo di test non può essere completamente automatizzato. Di conseguenza, è diviso in:
- Test automatici (verrà utilizzato nel caso in cui è possibile controllare le informazioni sull'output).
Scopo: test input, elaborazione e produzione di dati;
- Test manuali (in altri casi).
Scopo: prova la correttezza dell'esecuzione dei requisiti dell'utente.
È necessario eseguire (PLAY) ciascuno dei custodia per uso, utilizzando sia i valori fedele sia ovviamente errati, per confermare il corretto funzionamento, in base ai seguenti criteri:
- il prodotto risponde adeguatamente a tutti i dati inseriti (i risultati attesi vengono visualizzati in risposta ai dati correttamente inseriti);
- il prodotto risponde adeguatamente ai dati inseriti in modo errato (appaiono i messaggi di errore appropriati).
Test del database
Lo scopo di questo test è quello di assicurarsi che i metodi di accesso ai database siano affidabili, nella loro corretta esecuzione, senza interrompere l'integrità dei dati.
È necessario utilizzare in modo coerente il numero massimo possibile di ricorsi per il database. Viene utilizzato un approccio, in cui il test è compilato in modo tale da "caricare" la base con una sequenza, sia i valori fedeli che ovviamente errati. Viene determinata la risposta del database sulla voce di dati, gli intervalli di tempo della loro elaborazione sono stimati.
Capitolo 3. Risultati dei test di elaborazione statistica
La lavorazione statistica dei risultati del test consente da una parte, definitivamente definire i risultati dei soggetti, dall'altro - per valutare la qualità del test stesso, i compiti di prova, in particolare per valutare la sua affidabilità. Il problema dell'affidabilità è prestato molta attenzione nella teoria classica dei test. Questa teoria non ha perso la rilevanza e ora. Nonostante l'apparizione, le teorie più moderne, la teoria classica continua a mantenere la sua posizione.
3.1. Le principali disposizioni della teoria classica dei test
3.2. Risultati del test della matrice.
3.3. Presentazione grafica dei punti di test
3.4. Misure di tendenza centrale
3.5. DISTRIBUZIONE NORMALE
3.6. Test dei punti di test di dispersione
3.7. Matrice di correlazione
3.8. Affidabilità del test
3.9. Validità del test
LETTERATURA
Le principali disposizioni della teoria classica dei test
Il creatore della teoria classica dei test (teoria classica dei test mentali) è un noto psicologo britannico, l'autore dell'analisi dei fattori, sfida Edward Spearman (1863-1945) 1. È nato il 10 settembre 1863, e un quarto della sua vita è stato servito nell'esercito britannico. Per questo motivo, ha ricevuto il grado di dottore della filosofia solo all'età di 41 anni 2. Lo studio della tesi di PartSpirman è stato eseguito nel laboratorio di Lipsia della psicologia sperimentale sotto la guida di Wilhelm Wundt (Wilhelm Wundt). In quel periodo, Francis Galton (Francis Galton) è stata una forte influenza su Ch.pirman (Francis Galton) per testare l'intelligenza umana. Gli alunni PartSpirman erano R.cattell e D.Wechsler. Tra i suoi follower, a.anastasi, J. P. Guilford, P.vernon, C.Burt, A.Jensen può essere chiamato.
Un grande contributo allo sviluppo della teoria classica dei test fatti Louis Guttman, 1916-1987) 3.
Completamente e pieno di teoria classica dei test per la prima volta è esposto nell'opera fondamentale di Harold Gullixen (Gulliksen H., 1950) 4. Da allora, la teoria ha un po 'modificato, in particolare l'apparato matematico è stato migliorato. La teoria del test classica nella presentazione moderna è riportata nel libro Crocker L., Aligna J. (1986) 5. Dai ricercatori nazionali, per la prima volta, la descrizione di questa teoria è stata data v.avanesi (1989) 6. Nel lavoro della Chelyowkova M.b. (2002) 7 Fornisce informazioni sulla confermità statistica della qualità del test.
La teoria dei test classici si basa sulle seguenti cinque posizioni principali.
1. Il risultato di misurazione ottenuto empiricamente (X) è la somma dei veri risultati di misurazione (T) e degli errori di misurazione (E) 8:
X \u003d T + E (3.1.1)
I valori T ed E sono solitamente sconosciuti.
2. Il vero risultato della misurazione può essere espresso come aspettativa matematica E (x):
3. La correlazione di componenti veri e errati secondo un insieme di soggetti è zero, cioè, ρ te \u003d 0.
4. I componenti errati di due eventuali test non sono correlati:
5. I componenti errati di un test non sono correlati con i componenti vere di qualsiasi altro test:
Inoltre, la base della teoria classica dei test è due definizioni - test paralleli e equivalenti.
I test paralleli devono essere conformi ai requisiti (1-5), i veri componenti di un test (T 1) devono essere uguali ai propri componenti di un altro test (T 2) in ciascun campione dei test che rispondono a entrambi i test. Si presume che T 1 \u003d T 2 e, in aggiunta, siano uguali alla dispersione s 1 2 \u003d S 2 2.
I test equivalenti devono essere conformi all'intero requisito dei test paralleli con l'eccezione di uno: i veri componenti di un test non devono essere uguali ai veri componenti di un altro test parallelo, ma dovrebbero differire sulla stessa costante. a partire dal.
La condizione di equivalenza di due test è registrata nel seguente modulo:
dove c 12 è la costante delle differenze nei risultati del primo e del secondo test.
Sulla base delle disposizioni di cui sopra, la teoria dell'affidabilità del test è 9.10.
cioè, la dispersione dei punti di prova ottenuta è uguale alla somma delle dispersioni dei componenti veri e errati.
Riscrivo questa espressione come segue:
 (3.1.3)
(3.1.3)
Il lato destro di questa uguaglianza è l'affidabilità del test ( r.). Pertanto, l'affidabilità del test può essere scritta nella forma:
Sulla base di questa formula, ci sono state espressioni successive per trovare il fattore di affidabilità del test. L'affidabilità del test è la sua caratteristica cruciale. Se l'affidabilità è sconosciuta, i risultati del test non possono essere interpretati. L'affidabilità del test caratterizza la sua precisione come strumento di misura. Elevata affidabilità significa alta ripetibilità dei risultati dei test nelle stesse condizioni.
Nella classica teoria del test, il problema più importante è determinare il vero punto di test del soggetto (T). Il punto di test empirico (X) dipende da molte condizioni - il livello di difficoltà dei compiti, il livello di preparazione dei soggetti, il numero di compiti, le condizioni per la conduzione dei test, ecc. Nel gruppo di soggetti forti e ben addestrati, i risultati dei test saranno di solito migliori. rispetto al gruppo soggetti preparati debolmente. A tale riguardo, la questione della grandezza della difficoltà dei compiti sulla popolazione generale dei soggetti rimane aperta. Il problema risiede nel fatto che i dati empirici reali si ottengono su tutti i campioni casuali dei soggetti. Di norma, questi sono gruppi educativi, che sono molti studenti di interagire abbastanza fortemente tra loro nel processo di insegnamenti e studenti in condizioni che spesso non vengono ripetute per altri gruppi.
Trova s e. Dall'equazione (3.1.4)
![]()
Qui mostra esplicitamente la dipendenza della precisione della misurazione dal valore di deviazione standard. s x. e dall'affidabilità del test r..
Le aree di applicazione, gli obiettivi e le attività dei test sono variati, quindi i test sono stimati e spiegati in modi diversi. A volte i tester stessi sono difficili da spiegare quale test su "come è". C'è una confusione.
Per svelare questa confusione, Alexey Bariancers (pratica, allenatore e consulente nei test del software; una partenza dall'Istituto di programmazione del sistema dell'Accademia delle scienze russe) prevede la sua formazione sul test del video introduttivo sui principali test dei test.
Mi sembra che in questo rapporto, il docente potesse spiegare più adeguatamente e spiegabilmente "cosa sta testando" dal punto di vista dello scienziato e del programmatore. È strano che questo testo non sia ancora apparso su Habré.
Citiamo qui una residenza compressa di questo rapporto. Alla fine del testo ci sono collegamenti sulla versione completa, così come il video menzionato.
Le principali posizioni dei test
Cari colleghi,Innanzitutto, proviamo a capire cosa non lo è il test.
Test non sviluppo,
Anche se i tester sono in grado di programmare, compresi i test (test di automazione \u003d programmazione), può sviluppare alcuni programmi ausiliari (da soli).
Tuttavia, il test non è attività di sviluppo software.
Il test non è l'analisi,
E non raccogliere e analizzare i requisiti.
Sebbene, nel processo di test, a volte devi chiarire i requisiti, e a volte devi analizzarli. Ma questa attività non è il principale, piuttosto, è necessario fare solo se necessario.
Test non gestione,
Nonostante il fatto che in molte organizzazioni vi sia un ruolo del "test del test". Naturalmente, i tester devono essere gestiti. Ma in sé il test non è controllato.
Il test non è il coinvolgimento tecnico,
Tuttavia, i tester devono documentare i loro test e il loro lavoro.
I test non possono essere considerati alcuna di queste attività semplicemente perché nel processo di sviluppo (o analizzare i requisiti o la scrittura della documentazione per i suoi test) i tester stanno facendo tutto questo lavoro per te, non per qualcun altro.
Attività che significa solo quando è richiesta, cioè, i titolari di test dovrebbero produrre qualcosa "per l'esportazione". Cosa fanno "per l'esportazione"?
Difetti, descrizioni dei difetti o report di prova? Parzialmente è vero.
Ma questa non è tutta la verità.
Test di attività principali
È che offrono ai partecipanti al progetto per sviluppare il feedback negativo del software sulla qualità del prodotto software."Feedback negativo" non porta una tinta negativa, e non significa che i titolari di test fanno qualcosa di male, o che fanno qualcosa di brutto. È solo un termine tecnico che significa una cosa abbastanza semplice.
Ma questa cosa è molto significativa, e probabilmente l'unica componente più significativa delle attività dei tester.
C'è una scienza - "teoria del sistema". Definisce un tale concetto come "feedback".
"Feedback" è alcuni dati riportati all'input o in qualche parte dei dati, che dall'uscita rientrano all'input. Questo feedback può essere positivo e negativo.
E quello, e le altre varietà di feedback sono ugualmente importanti.
Nello sviluppo di sistemi software con feedback positivi, ovviamente, sono alcune informazioni che riceviamo dagli utenti finali. Queste sono richieste per alcune nuove funzionalità, questo aumento delle vendite (se produciamo un prodotto di qualità).
Il feedback negativo può anche provenire dagli utenti finali sotto forma di alcune recensioni negative. O lei può venire dai tester.
Viene fornito il feedback negativo precedente, la meno energia è necessaria per la modifica di questo segnale. Questo è il motivo per cui è necessario iniziare a iniziare il prima possibile, nelle prime fasi del progetto e fornire questo feedback e allo stadio di progettazione, e anche, forse prima, nella fase di raccolta e analizzare i requisiti.
A proposito, quindi la comprensione che i tester non sono responsabili per la qualità. Aiutano quelli che sono responsabili per lui.
Sinonimi di termine "test"
Dal punto di vista del fatto che il test è la fornitura di feedback negativi, l'abbreviazione QA famosa mondiale (inglese. Quality Assurance - Quality Assurance) Sinonimo per il termine "test" non è esattamente definitivamente.È impossibile considerare la garanzia della qualità semplice prestazione di feedback negativo, poiché la disposizione è alcune misure positive. Resta inteso che in questo caso stiamo fornendo qualità, in modo tempestivo prendiamo alcune misure in modo che la qualità dello sviluppo del software sia aumentata.
Ma "controllo qualità" - il controllo della qualità, può essere considerato in senso lato positivo sinonimo del termine "test", poiché il controllo di qualità è questo e c'è una fornitura di feedback in un'ampia varietà di varietà, in varie fasi del Progetto del programma.

A volte il test è inteso come qualche forma separata di controllo di qualità.
La confusione deriva dalla storia dei test. A tempi diversi, il termine "test" è stato destinato a varie azioni che possono essere divise in 2 classi di grandi dimensioni: esterno e interno.
Definizioni esterne
Definizioni che in momenti diversi sono stati assegnati Myers, Beyser, Kaner, descrivere il test solo dal punto di vista del suo significato esterno. Cioè, dal loro punto di vista, il test è un'attività che è destinata a qualcosa e non consiste in qualcosa. Tutte e tre queste definizioni possono essere generalizzate come feedback negativo.Definizioni interne
Queste sono le definizioni che vengono fornite nello standard della terminologia utilizzate nell'ingegneria del software, ad esempio, nello standard De Facto chiamato Swebok.Tali definizioni sono spiegate in modo costruttivo, che è le attività di prova, ma non forniscono alcuna idea che sia necessario testare il quale verranno utilizzati tutti i risultati della verifica della conformità tra il comportamento effettivo del comportamento effettivo del programma e del suo comportamento previsto.
test è
- controllare la conformità dei requisiti del programma
- effettuato osservando il suo lavoro
- in speciali situazioni create artificialmente scelte in un certo modo.

Schema di prova totale approssimativamente come segue:
- Il tester di input riceve un programma e / o un requisito.
- Fa qualcosa con loro, guarda il lavoro del programma in alcune situazioni sofisticate create da lui.
- All'output, riceve informazioni sulle corrispondenze e sulle incoerenze.
- Successivamente, queste informazioni vengono utilizzate per migliorare il programma già esistente. O al fine di modificare i requisiti per un altro programma.
Cos'è un test
- Questa è una situazione speciale e creata artificialmente scelta in un certo modo,
- e una descrizione di quali osservazioni del programma devono fare
- per verificare la sua conformità con alcuni requisiti.
Lo sviluppatore del test è impegnato nel fatto che proviene da un enorme test potenzialmente infinito di test scegliere un set limitato.
Bene, quindi possiamo concludere che il tester fa due cose nel processo di test.
1. In primo luogo, gestisce l'esecuzione del programma e crea queste situazioni più artificiali in cui controlliamo il comportamento del programma.
2.I, in secondo luogo, sta guardando il comportamento del programma e confronta ciò che vede con ciò che è previsto.
Se il tester automatizza i test, non osservò il comportamento del programma - delega questa attività a uno strumento speciale o un programma speciale che ha scritto. È lei che osserva, confronta il comportamento osservato con il previsto e il tester dà solo un risultato finale - se il comportamento osservato coincide con il previsto, o non coincide.
Qualsiasi programma è un meccanismo per l'elaborazione delle informazioni. La voce entra nell'ingresso in qualche forma, le informazioni di uscita in qualche altra forma. Allo stesso tempo, gli ingressi e le uscite del programma possono essere molto, possono essere diversi, ovvero un programma può avere diverse interfacce e queste interfacce potrebbero avere tipi diversi:
- Interfaccia utente (UI)
- Interfaccia software (API)
- Protocollo di rete
- File system.
- Condizione dell'ambiente
- Eventi
- abitudine
- grafico,
- testo
- a sbalzo,
- e discorso.
- in qualche modo crea situazioni artificiali,
- e controlla queste situazioni come comporta un programma.
Questo è il test.
Altre classificazioni dei tipi di test
Più spesso usato per dividere tre livelli, esso- test modulari
- test d'integrazione
- test del sistema.
Sotto il test del sistema si intende test a livello di interfaccia utente.
A volte vengono anche utilizzati altri termini, come "test dei componenti", ma preferisco assegnare questi tre, a causa del fatto che la separazione tecnologica dei test modulari e sistemici non ha molto senso. A livelli diversi, gli stessi strumenti possono essere utilizzati le stesse tecniche. Separazione condizionalmente.
La pratica mostra che gli strumenti che sono posizionati dal produttore come strumenti di prova modulari possono essere applicati con uguale successo e al livello di test dell'intera applicazione nel suo complesso.
E gli strumenti che testano l'intera applicazione nel suo complesso a livello di interfaccia utente a volte vogliono guardare, ad esempio, al database o causare una procedura memorizzata separata.
Cioè, la divisione in test sistemici e modulari è generalmente puramente condizionale, se parliamo da un punto di vista tecnico.
Vengono utilizzati gli stessi strumenti, e questo è normale, vengono utilizzate le stesse tecniche, ad ogni livello è possibile parlare di testare vari tipi.
Combinare:

Cioè, puoi parlare di test modulari di funzionalità.
Puoi parlare di test di funzionalità sistemica.
Puoi parlare di test modulari, ad esempio, efficienza.
Puoi parlare di test sistemici di efficienza.
Oppure consideriamo l'efficacia di alcuni algoritmi separati, o consideriamo l'efficacia dell'intero sistema nel suo complesso. Cioè, la separazione tecnologica per i test modulari e sistemici non ha molto senso. Poiché a diversi livelli, gli stessi strumenti possono essere utilizzati le stesse tecniche.
Infine, con test di integrazione, controlliamo se, come parte di un sistema, i moduli interagiscono correttamente l'uno con l'altro. Cioè, effettivamente eseguiamo gli stessi test del test del sistema, prestare ulteriormente attenzione a come i moduli interagiscono tra loro. Eseguire alcuni controlli aggiuntivi. Questa è l'unica differenza.
Proviamo ancora a cercare di capire la differenza tra test sistemici e modulari. Poiché questa separazione si trova abbastanza spesso, questa differenza deve essere.
E questa differenza si manifesta quando non eseguiamo una classificazione tecnologica, ma una classificazione da bersagli Test.
La classificazione per gli scopi è comodo da eseguire utilizzando la "Magic Square", originariamente inventata da Brian Marik e poi ha migliorato Erie Tannen.

In questa piazza magica, tutti i tipi di test si trovano su quattro quadranti, a seconda di ciò che l'attenzione è più focalizzata in questi test.
Verticalmente - Più alto è il tipo di test, più attenzione viene prestata ad alcune manifestazioni esterne del comportamento del programma, il più basso è, più prestano attenzione al proprio dispositivo tecnologico interno del programma.
Orizzontalmente - La sinistra I nostri test si trovano, più attenzione li paghiamo alla programmazione, più a destra sono, più attenzione paghiamo per test manuali e ricerca del programma da parte di una persona.
In particolare, in questo quadrato è possibile inserire facilmente tali termini come test di accettazione, test di accettazione, test modulari con precisione in quella comprensione in cui è più spesso utilizzato in letteratura. Questo è il test di basso livello con grande, con una quota travolgente della programmazione. Cioè, questi sono tutti i test sono programmati, completamente eseguiti automaticamente e l'attenzione è pagata principalmente al dispositivo interno del programma, sono le sue caratteristiche tecnologiche.
Nell'angolo in alto a destra, avremo prove a mano finalizzate al comportamento esterno del programma, in particolare, testando la facilità d'uso e nell'angolo in basso a destra, molto probabilmente è stato ispezionato da diverse proprietà non funzionali: prestazioni, sicurezza, e così via.
Quindi, in base alla classificazione da parte dei bersagli, riveliamo test modulari nel quadrante più alto e tutti gli altri quadranti sono test di sistema.
Grazie per l'attenzione.
nozioni di base della teoria dei test
Concetti di base della teoria dei test
La misurazione o il test effettuato per determinare lo stato o le abilità di un atleta è chiamato impasto .
Non tutte le misurazioni possono essere utilizzate come test, ma solo quelli che soddisfano i requisiti speciali. Questi includono:
1. La standardizzazione (procedura e condizioni di test dovrebbero essere le stesse in tutti i casi di applicazione del test);
2. Affidabilità;
3. Informativo;
4. La presenza del sistema di valutazione.
I test che soddisfano i requisiti di affidabilità e informatività sono chiamati sobota. o autentico (Greco. Modo autentico - affidabile).
Il processo di prova è chiamato test ; Il valore numerico ottenuto come risultato - risultati del test (o il risultato del test). Ad esempio, l'esecuzione di 100 m è un test, la procedura per eseguire l'occasione e il test di tempistica, il tempo della gara è il risultato del test.
I test basati su Attività Motor sono chiamati il motore o il motore . I risultati di loro possono essere i risultati dei motori (il tempo di passaggio della distanza, il numero di ripetizioni passò attraverso la distanza, ecc.), O indicatori fisiologici e biochimici.
A volte è usato non uno, ma diversi test che hanno un obiettivo singolo (ad esempio, una valutazione dello stato di un atleta nel periodo competitivo di formazione). Tale gruppo di test è chiamato complesso o testare la batteria .
Lo stesso test applicato allo stesso studio dovrebbe essere fornito nelle stesse condizioni dei risultati di coincidenza (a meno che non abbiano cambiato gli stessi studiati). Tuttavia, con la standardizzazione più rigorosa e le attrezzature accurate, i risultati dei test sono sempre in qualche modo vari. Ad esempio, la dinamometria risultante che ha appena mostrato il risultato di 215 kg nel test della dinamometria, con esecuzione ripetuta mostra solo 190 kg.
2. Affidabilità dei test e dei modi per determinare
Affidabilità Il test è chiamato il grado di coincidenza dei risultati durante la re-test delle stesse persone (o altri oggetti) nelle stesse condizioni.
La variazione dei risultati quando il re-test è chiamato interno individuale o all'interno del gruppo o intrasklass.
Quattro ragioni principali causano questa variazione:
1. Cambiare lo stato dello studiato (affaticamento, lavoro, apprendimento, cambio di motivazione, concentrazione di attenzione, ecc.).
2. Cambiamenti incontrollati in condizioni e attrezzature esterne (temperatura, vento, umidità, tensione nella rete elettrica, presenza di persone non autorizzate, ecc.), I.e. Tutto ciò combina il termine "errore di misurazione casuale".
3. Modifica dello stato di una persona che conduce o valuta il test (e, ovviamente, sostituire uno sperimentatore o giudicare ad altri).
4. L'imperfezione dell'impasto (ci sono tali test che sono consapevolmente scomodi. Ad esempio, se i test eseguono liberi lanci in un cestino di pallacanestro, anche un giocatore di basket che ha un'alta percentuale di colpi può essere scambiata accidentalmente per il primo lancio).
La principale differenza nella teoria dell'affidabilità del test sulla teoria degli errori di misurazione è che nella teoria degli errori, il valore misurato è considerato invariato, e nella teoria dei test di affidabilità si presume che si rivolgesse dalla misurazione della misurazione. Ad esempio, se è necessario misurare il risultato di un tentativo fatto in lunghezze di lunghezza da una pista, non può cambiare significativamente e nel tempo. Naturalmente, a causa delle cause casuali (ad esempio, tensione ineguale della roulette), è impossibile misurare questo risultato con una precisione ideale (dire fino a 0,0001 mm). Tuttavia, utilizzando uno strumento di misurazione più accurato (ad esempio, un misuratore laser), è possibile aumentare la precisione al livello richiesto. Allo stesso tempo, se il compito è quello di determinare la preparazione del ponticello in determinate fasi del ciclo di formazione annuale, la misurazione più accurata dei risultati indicati da loro poco aiuterà: dopo tutto, cambieranno dal tentativo di provare.
Per affrontare l'idea dei metodi utilizzati per giudicare l'affidabilità dei test, considera un esempio semplificato. Supponiamo di aver bisogno di confrontare i risultati dei salti di lunghezza da un posto in due atleti su due tentativi completati. Supponiamo che i risultati di ciascuno degli atleti variano a variare entro ± 10 cm dal valore medio e sono uguali, rispettivamente, 230 ± 10 cm (cioè 220 e 240 cm) e 280 ± 10 cm (cioè 270 e 290 cm). In questo caso, la conclusione, ovviamente, sarà completamente inequivocabile: il secondo atleta supera il primo (le differenze tra la media in 50 cm sono chiaramente superiori alle oscillazioni casuali di ± 10 cm). Se, con la stessa variazione infragruppo (± 10 cm), la differenza tra i valori medi dello studiata (variazione dell'intergruppo) sarà piccola, quindi sarà molto più difficile effettuare l'output. Supponiamo che i valori medi saranno circa pari a 220 cm (in un unico tentativo - 210, nell'altro - 230 cm) e 222 cm (212 e 232 cm). Allo stesso tempo, il primo studiato nel primo tentativo salta a 230 cm e il secondo è solo a 212 cm; E sembra che il primo sia essenzialmente più forte del secondo. Da questo esempio, si può vedere che il valore principale non è la sua variabilità intra-mercato, ma il suo rapporto con differenze di interclacia. La stessa variabilità intraclassica conferisce diversa affidabilità con pari differenze tra le classi (nel caso particolare tra gli studiti, la figura 14).
Fico. 14. Il rapporto tra variazione inter-e intra-classe con affidabilità alta (in alto) e bassa (inferiore):
brevi tratti verticali - dati dei tentativi individuali;
I risultati medi dei tre studiati.
La teoria dell'affidabilità del test procede dal fatto che il risultato di qualsiasi misurazione condotta sulla persona è la somma di due valori:
dove: - il cosiddetto risultato vero che vogliono aggiustare;
Un errore causato da cambiamenti incontrollabili nello stato del test e degli errori di misurazione casuale.
Sotto il vero risultato, il valore medio di X con un numero infinitamente elevato di osservazioni nelle stesse condizioni è (per questo, a X, hanno messo un segno).
Se gli errori sono casuali (la loro somma è zero, e in uguali tentativi non dipendono l'uno dall'altro), quindi dalle statistiche matematiche segue:
quelli. Registrato nell'esperimento della dispersione dei risultati è uguale alla quantità di dispersioni dei veri risultati e degli errori.
Coefficiente di affidabilità Il rapporto tra la vera dispersione alla dispersione è registrata nell'esperimento:

Oltre al coefficiente di affidabilità, ancora utilizzare indice di affidabilità:
che è considerato come un coefficiente di correlazione teorico dei valori dei test registrati con True.
Il concetto del vero risultato del test è l'astrazione (nell'esperienza è impossibile). Pertanto, devi usare metodi indiretti. Più preferito per valutare l'analisi della dispersione dell'affidabilità, seguita dal calcolo dei coefficienti di correlazione intracelati. L'analisi della dispersione consente di decomporre la variazione dei risultati dei test nei componenti dovuti all'influenza dei singoli fattori. Ad esempio, se registri i risultati nei risultati studiati in qualsiasi test, ripetendo questo test in giorni diversi e ogni giorno per fare diversi tentativi, cambiano periodicamente sperimentatori, allora ci saranno variazioni:
a) dal soggetto al soggetto;
b) da giorno in giorno;
c) dallo sperimentatore allo sperimentatore;
d) dal tentativo di provare.
L'analisi della dispersione consente di allocare e valutare queste varianti.
Pertanto, è necessario stimare l'affidabilità praticamente del test, in primo luogo, per eseguire un'analisi di dispersione, in secondo luogo, calcolare il coefficiente di correlazione intralass (rapporto di affidabilità).
Con due tentativi, il valore del coefficiente di correlazione intra-classe coincide praticamente con i valori del consueto coefficiente di correlazione tra i risultati del primo e del secondo tentativo. Pertanto, in tali situazioni, un coefficiente di correlazione convenzionale può essere utilizzato per valutare l'affidabilità (stima l'affidabilità di uno, non due tentativi).
Parlando sull'affidabilità dei test, è necessario distinguere la loro stabilità (riproducibilità), coerenza, equivalenza.
Sotto stabilità I test comprendono la riproducibilità dei risultati quando viene ripetuta dopo un certo momento nelle stesse condizioni. I test ripetuti sono solitamente chiamati retest.
Consistenza Il test è caratterizzato dall'indipendenza dei risultati dei test da qualità personali di una persona che conduce o di un test di valutazione.
Quando si sceglie un test da un certo numero di stessi test di tipo (ad esempio, uno sprint gestito da 30, 60 e 100 m) da forme parallele, il grado di coincidenza dei risultati è stimato. Calcolato tra la chiamata del coefficiente di correlazione dei risultati rapporto di equivalenza.
Se tutti i test inclusi in qualsiasi tipo di test sono altamente equivalenti, è chiamato omogenico. Questo complesso misure misura una delle proprietà della motilità umana (ad esempio, un complesso costituito da saltare dal luogo di lunghezza, in alto e triplo; è stimato il livello di sviluppo di qualità di sicurezza ad alta velocità). Se non ci sono test equivalenti nel complesso, cioè, i test inclusi in esso sono misurati proprietà diverse, quindi viene chiamata eterogeneo (Ad esempio, un complesso costituito da diventare dinamometria, saltare su Acalac, in esecuzione per 100 m).
L'affidabilità del test può essere aumentata in una certa misura da:
a) standardizzazione più rigorosa dei test;
b) aumentare il numero di tentativi;
c) aumentare il numero di periti (giudici, esperimenti) e migliorare la coerenza delle loro opinioni;
d) aumentare il numero di test equivalenti;
e) la migliore motivazione dello studiato.
Esempio 10.1.
Determinare l'affidabilità dei risultati di un triplo salto dal luogo nella valutazione della velocità e delle capacità di potenza degli atleti di sprint, se questi campioni sono come segue:
Decisione:
1. Applicare i risultati del test alla tabella di lavoro: 
2. Sosteniamo i risultati ottenuti nella formula di calcolo del coefficiente di rango di correlazione:

3. Definiamo il numero di gradi di libertà da parte della formula:
Produzione: Il valore di liquidazione risultante è quindi, con fiducia in 99% possiamo dire che il test a triplo salto è affidabile.
Il primo componente, la teoria dei test, contiene una descrizione dei modelli di elaborazione dati diagnostici statistici. Ecco i modelli di analisi delle risposte in attività di test e il modello di calcolo dei risultati totali dei test. Mellenberg (1980, 1990) lo ha definito "Psychometry". Teoria dei test classici, teoria dei test moderni (o analisi del modello delle risposte alle attività di prova - IRT) e modello
i campioni delle attività costituiscono i tre tipi più importanti di modelli di teoria del test. L'oggetto della psicodiagnostica è il primo due modelli.
Teoria dei test classici. Sulla base di questa teoria, sono stati sviluppati i test più intellettuali e personali. Il concetto centrale di questa teoria è il concetto di "affidabilità". In affidabilità è inteso come la coerenza dei risultati durante la rivalutazione. Nei manuali di riferimento, questo concetto è solitamente molto breve, e quindi viene data una descrizione dettagliata dell'apparato delle statistiche matematiche. In questo, introduttivo, capitolo presenteremo una descrizione compressa del valore principale del concetto noto. Nella teoria del test classico, affidabile è la ripetizione dei risultati di diverse procedure di misurazione (principalmente misurazioni con test). Il concetto di affidabilità comporta il calcolo dell'errore di misurazione. I risultati ottenuti durante il processo di test possono essere rappresentati come la somma del vero risultato e dell'errore di misurazione:
Xi \u003d ti.+ EJ.
dove Xi.- Valutazione dei risultati ottenuti, TI è un risultato vero e EJ.- Errore di misurazione.
La valutazione dei risultati ottenuti è, come regola, il numero di risposte corrette alle attività del test. Il vero risultato può essere visto come una vera valutazione in senso platonico (Gulliksen, 1950). Il concetto di risultati attesi è diffuso, cioè. Rappresentazioni di punti che possono essere ottenuti a seguito di un gran numero di ripetizioni di procedure di misurazione (Signore & Novich, 1968). Ma l'implementazione della stessa procedura di valutazione con una persona non è possibile. Pertanto, è necessario cercare altre soluzioni al problema (Witlin, 1988).
Nell'ambito del quadro di questo concetto, alcune assunzioni sono rese relative ai veri risultati e agli errori di misurazione. Quest'ultimo è accettato come un fattore indipendente, che, ovviamente, è un'assunzione ben fondata, poiché le fluttuazioni casuali nei risultati non danno i cellatili: r it \u003d 0.
Si presume che la correlazione tra i veri punteggi e gli errori di misurazione non esista: r ee \u003d 0.
L'errore totale è 0, perché Come una vera stima, il significato aritmetico è preso:
Queste ipotesi ci conducono a seguito di una determinata definizione di affidabilità come un rapporto del risultato reale a una dispersione o espressione comune: 1 meno la relazione, in cui il numero di errore di misurazione e nel denominatore - la dispersione generale:
 , O
, O 
Da questa definizione della formula di affidabilità, otteniamo quell'errore di dispersione S 2 (e)È uguale alla dispersione totale tra i casi (1 - r xx "); quindi, l'errore di misurazione standard è determinato dalla formula:
![]()
Dopo la sostanza teorica dell'affidabilità e dei suoi derivati, è necessario determinare l'indice di affidabilità di un test. Esistono procedure pratiche per valutare l'affidabilità del test, come l'utilizzo di moduli intercambiabili (test paralleli), dividendo attività in due parti, re-test e misurando la coerenza interna. Ogni directory contiene gli indici di costanza dei risultati dei test:
r xx '\u003d r (x 1, x 2)
dove r xx ' - coefficiente di stabilità e x 1. e x 2. - I risultati delle due dimensioni.
Il concetto di affidabilità delle forme intercambiabili è stata introdotta e sviluppata da Gullixen (1950). Questa procedura è piuttosto laboriosa, perché è correlata alla necessità di creare una serie parallela di compiti.
r xx '\u003d r (x 1, x 2)
dove r xx ' - Coefficiente di equivalenza e x 1. e x 2. - Due test paralleli.
La seguente procedura è la divisione del test principale in due parti A e B è più semplice da usare. Gli indicatori ottenuti su entrambe le parti del test sono correlati. Con l'aiuto della formula di Spearman-Brown, l'affidabilità del test nel suo complesso è stimata:
dove e b - due parti parallele del test.
Il seguente metodo è la definizione di coerenza interna delle attività di test. Questo metodo si basa sulla definizione di covariani di singoli compiti. SG - dispersione di un lavoro arbitrariamente selezionato e SGH - Covariance di due attività arbitrariamente selezionate. Il coefficiente più frequentemente usato per definire la coerenza interna è il "coefficiente alfa-alfa" di Kronbach. Anche la formula è usata Kr20 e λ-2(Lambda-2).
Nel classico concetto di affidabilità, vengono determinati errori di misurazione sia nel processo di test che nel processo di osservazioni. Le fonti di questi errori sono diverse: queste possono anche essere caratteristiche personali e caratteristiche delle condizioni di test e le attività di prova stesse. Esistono metodi specifici per il calcolo degli errori. Sappiamo che le nostre osservazioni possono essere errate, i nostri strumenti metodici sono imperfetti nello stesso modo in cui le persone stesse sono imperfette. (Come non ricordare Shakespeare: "Non sei affidabile, il cui nome è una persona"). Il fatto che nella misura classica dei test di errore di misurazione sia esplicibile e spiegata è un punto positivo importante.
La teoria del test classica ha una serie di caratteristiche essenziali che possono essere considerate come i suoi svantaggi. Alcune di queste caratteristiche sono annotate nei libri di riferimento, ma il loro significato (dal punto di vista quotidiano) è sottolineato di rado, come no e il fatto che dovrebbero essere considerati carenze dal punto di vista teorico o metodologico.
Primo. La teoria dei test classici e il concetto di affidabilità sono focalizzati sul calcolo degli indicatori totali dei test, che sono il risultato dell'aggiunta di stime ottenute in compiti separati. Quindi, quando si lavora
Secondo. Il fattore di affidabilità implica una valutazione della varianza degli indicatori misurati. Ne consegue che il fattore di affidabilità sarà inferiore se (con l'uguaglianza di altri indicatori) il campione è più omogeneo. Non esiste un singolo coefficiente di coerenza interna delle attività di test, questo coefficiente è sempre "contestuale". Crocker e Aldjina (1986), ad esempio, offrono una formula speciale "correzione per il campione omogeneo" destinato ai risultati più alti e più bassi ottenuti dai test. Per il diagnostico, è importante conoscere le caratteristiche delle variazioni nel set di campioni, altrimenti non sarà in grado di utilizzare i coefficienti della coerenza interna specificata nel manuale per questo test.
Terzo. Il fenomeno delle informazioni sull'indicatore aritmetico medio è una conseguenza logica del concetto classico di affidabilità. Se la valutazione nel test fluttua (cioè, non è abbastanza affidabile), è abbastanza possibile che quando la ripetizione della procedura, i soggetti aventi indicatori bassi riceveranno punti più alti e viceversa, i soggetti con indicatori elevati sono bassi. Questo artefatto delle procedure di misurazione non può essere scambiato per un vero cambiamento o manifestazione dei processi di sviluppo. Ma allo stesso tempo delimitarli non è facile, perché Non puoi mai eliminare la possibilità di cambiare durante lo sviluppo. Per completa sicurezza è necessario "confronto con il gruppo di controllo.
La quarta caratteristica dei test sviluppata in conformità con i principi della teoria classica è la presenza di dati normativi. La conoscenza delle regole di test consente al ricercatore di interpretare adeguatamente i risultati del test. Al di fuori della norma, le stime del test sono prive di significato. Lo sviluppo delle norme di test è un'impresa abbastanza costosa, poiché lo psicologo dovrebbe ricevere risultati del test su un campione rappresentativo.
2 J. Ter Laak
Se parliamo delle carenze del concetto classico di affidabilità, allora la dichiarazione di SIY TSMA è appropriata qui (1992, r. 123-125). Nota che la prima e più importante assunzione della teoria classica dei test è che i risultati dei test sono soggetti al principio dell'intervallo. Tuttavia, nessuna ricerca che conferma questa ipotesi non lo è. In effetti, è "misurazione su una regola arbitrariamente stabilita". Questa caratteristica mette la teoria classica dei test in una posizione meno favorevole rispetto alle scale di misurazione e, naturalmente, rispetto alla moderna teoria del test. Molti metodi di analisi dei dati (analisi della dispersione. Analisi della regressione, analisi della correlazione e analisi dei fattori) si basano sull'esistenza della scala dell'intervallo. Tuttavia, non ha una solida giustificazione. Considerare la scala dei veri risultati come una scala di valori di caratteristiche psicologiche (ad esempio, abilità aritmetiche, intelligence, neurotismo) possono essere presumibilmente presumibilmente.
La seconda osservazione riguarda i risultati dei test del test: questi non sono indicatori assoluti di una o di un'altra caratteristica psicologica dei test testati, devono essere considerati solo come i risultati dell'attuazione di un test. Due test possono richiedere lo studio delle stesse caratteristiche psicologiche (ad esempio, intelligenza, abilità verbali, estroversione), ma ciò non significa che questi due test siano equivalenti e possiedono le stesse capacità. Confronto degli indicatori di due persone che sono stati testati da diversi test, erroneamente. Lo stesso vale per il riempimento di due diversi test con un soggetto. La terza nota si riferisce al presupposto che l'errore di misurazione standard è lo stesso in relazione a qualsiasi livello delle capacità individuali misurate. Tuttavia, non vi è alcuna verifica empirica di questa ipotesi. Quindi, ad esempio, non vi è alcuna garanzia che ha testato con buone capacità matematiche quando si lavora con un test aritmetico relativamente semplice riceverà punti alti. In questo caso, una persona con abilità a basso o medio sarà molto apprezzata.
Nell'ambito della teoria del test corrente o della teoria delle risposte dell'analisi delle risposte nelle attività di test, una descrizione è descritta in un grande
il numero di modelli di possibili risposte degli intervistati. Questi modelli differiscono nelle loro ipotesi di fondazione, nonché i requisiti per i dati ottenuti. Il modello Rasha è spesso considerato un sinonimo per le teorie dell'analisi delle risposte nelle attività di test (1RT). In effetti, questo è solo uno dei modelli. La formula rappresentata in esso per descrivere la caratteristica curva del compito G è il seguente:

dove g.- un compito separato del test; ejr.- la funzione di esponenziali (dipendenza non lineare); δ (Delta) - il livello di difficoltà di dozzasso.
Altri compiti del test, per esempio h,ottieni anche le loro curve caratteristiche. Termini di condizione Δ h\u003e δ g (gsignifica che h.- Compito più difficile. Di conseguenza, per qualsiasi valore dell'indicatore Θ ("Theta" - Le proprietà latenti delle abilità del test) Probabilità di attività di successo h.di meno. Questo modello è chiamato rigoroso perché è ovvio che con un basso grado di gravità, la probabilità del compito è vicina a zero. In questo modello non c'è posto per indovinare e ipotesi. Per i compiti con le opzioni, non è necessario effettuare ipotesi sulla probabilità di successo. Inoltre, questo modello è severo nel senso che tutti i compiti del test devono avere la stessa capacità discriminatoria (elevata riflessione discriminatoria nella ripida della curva; qui è possibile costruire la scala Gut-Tman, secondo il quale a ciascuno Curva caratteristica, la probabilità dell'attività sta cambiando fino a 1). Per questo motivo, le condizioni non sono tutte le attività possono essere incluse nei test creati sulla base del modello Rasha.
Ci sono diverse opzioni per questo modello (ad esempio Birnbaura, 1968, vedi Lord & Novik). Rende l'esistenza di compiti con diversi discriminatori
capacità.
Dutch Explorer Mokken (1971) ha sviluppato due modelli per analizzare le risposte nei compiti del test, i cui requisiti non sono così rigorosi come nel modello della corsa, e quindi potrebbe essere più realistico. Come la condizione principale
vIYA Mokken propone la posizione che la curva caratteristica del compito deve seguire monotono, senza pause. Tutti i compiti del test allo stesso tempo sono finalizzati allo studio delle stesse caratteristiche psicologiche, che dovrebbero essere misurate nel.Qualsiasi forma di questa dipendenza è consentita fino a quando non si interruppe. Di conseguenza, la forma della curva caratteristica non è determinata da alcuna funzione specifica. Tale "Freedom" consente di utilizzare più attività di test e il livello di stima non è superiore al solito.
La metodologia dei modelli di risposte ai compiti del test (IRT) differisce dalla metodologia degli studi più sperimentali e di correlazione. Il modello matematico è progettato per studiare caratteristiche comportamentali, cognitive ed emotive, nonché fenomeni di sviluppo. Questi fenomeni in esame sono spesso limitati alle risposte ai compiti, che ha permesso a Mel-Lenberg (1990) di chiamare la teoria della teoria della mini-teoria "mini-teoria sul mini-comportamento". I risultati dello studio possono essere presentati in una certa misura come curve di coerenza, in particolare nei casi in cui le idee teoriche sulle caratteristiche studiate sono assenti. Fino ad ora, la nostra disposizione ha solo unità di test di intelligence, abilità e test personali creati sulla base di numerosi modelli di teoria dell'IRT. Le varianti del modello Rasha sono più spesso utilizzate nello sviluppo dei test di realizzazione (Verhelst, 1993), e il modello del Mockene è più adatto per i fenomeni di sviluppo (vedi anche Cap.6).
La risposta è testata sul compito del test è l'unità principale dei modelli IRT. Il tipo di risposta è determinato dal grado di gravità nelle caratteristiche studiate degli esseri umani. Tale caratteristica può essere, ad esempio, abilità aritmetiche o spaziali. Nella maggior parte dei casi, questo è uno o un altro aspetto dell'intelligenza, caratteristiche dei risultati o caratteristiche personali. Si presume che tra la posizione di questa particolare persona in una certa gamma della caratteristica e della probabilità di un'attuazione di successo di uno o di un altro compito, vi è una dipendenza non lineare. La non linearità di questa dipendenza da un certo senso è intuitiva. Frasi famose "Qualsiasi inizio è difficile" (lento
l'inizio lineare) e "Diventare Sacred non è così semplice", significa che ulteriori miglioramenti dopo il raggiungimento di un certo livello è difficile. La curva si avvicina lentamente, ma quasi non raggiunge mai il 100% del livello di successo.
Alcuni modelli piuttosto contraddicono la nostra comprensione intuitiva. Prendere un esempio del genere. Una persona con un indice caratteristico arbitrario di 1,5 ha una probabilità del 60% di successo durante l'esecuzione di un'attività. Questo contraddice la nostra comprensione intuitiva di tale situazione, perché può essere con successo con il compito, o non affrontarlo affatto. Prendi questo esempio: 100 volte una persona sta cercando di prendere un'altezza di 1m 50 cm. Il successo lo accompagna 60 volte, cioè. Ha una probabilità del 60% di successo.
Per valutare il grado di gravità, le caratteristiche devono almeno due compiti. Il modello Rasha assume la definizione della gravità delle caratteristiche, indipendentemente dalla difficoltà del compito. Contradisce anche la nostra comprensione intuitiva: supponiamo che una persona abbia una probabilità dell'80 percento di saltare sopra 1,30 m. In caso negativo, in accordo con la caratteristica curva dell'attività, ha una probabilità del 60 percento di saltare sopra 1,50 m e il 40 percento la probabilità Il salto sopra è 1,70 m. Di conseguenza, indipendentemente dal valore di una variabile indipendente (altezza), è possibile stimare la capacità di una persona di saltare in altezza.
Ci sono circa 50 modelli IRT (Goldstein & Wood, 1989). Ci sono molte funzioni non lineari che descrivono (spiegando) la probabilità di successo nell'esecuzione di un compito o un gruppo di compiti. I requisiti e le limitazioni di questi modelli sono diversi e queste differenze possono essere rilevate quando si confrontano il modello della corsa e la scala del Moccaen. I requisiti di questi modelli includono:
1) la necessità di determinare le caratteristiche studiate e la valutazione della posizione della persona nella gamma di questa funzione;
2) Valutazione dell'impostazione dei compiti;
3) Controlla i modelli specifici. Nella psicometria, sono state sviluppate molte procedure per verificare il modello.
In alcuni manuali di riferimento, la teoria dell'IRT è considerata come una forma di analisi dei compiti di prova (vedere, ad esempio,
Croker & Algina, J 986). È possibile, tuttavia, difendere il punto di vista che la teoria dell'IRT è una "mini teoria del mini-comportamento". I sostenitori della teoria dell'IRT si noti che se i concetti imperfetti (modelli) del livello medio-livello, allora ciò che si può dire su costrutti più complessi in psicologia?
Teoria del test classica e moderna. Le persone non possono confrontare le cose che sembrano quasi le stesse. (Forse un equivalente quotidiano della psicometria e consiste principalmente nel confrontare le persone per caratteristiche e scelte significative tra loro). Ciascuna delle teorie presentate - e la teoria degli errori di valutazione di misurazione e il modello matematico delle risposte ai compiti del test - ha i suoi sostenitori (Goldstein & Wood, 1986).
I modelli IRT non causano rimproveri nel fatto che è "Valutazione secondo le regole", a differenza della teoria classica dei test. Il modello IRT è focalizzato sull'analisi delle caratteristiche valutate. Le caratteristiche delle singole e delle caratteristiche dei compiti sono stimate dalle bilance (ordinali o intervalli). Inoltre, è possibile confrontare le prestazioni di diversi test finalizzati all'apprendimento delle caratteristiche simili. Infine, l'affidabilità di ineguali per ciascun valore sulla scala e gli indicatori medi sono solitamente più affidabili degli indicatori situati all'inizio e alla fine della scala. Così, i modelli IRT in relazioni teoriche sono preezionata. Ci sono anche differenze nell'uso pratico della teoria moderna dei test e della teoria classica (Sijstma, 1992, p. 127-130). La teoria moderna dei test è più complicata rispetto al classico, quindi è meno comunemente usato da non specialisti. Inoltre, IRT pone requisiti speciali per i compiti. Ciò significa che le attività devono essere escluse dal test se non soddisfano i requisiti del modello. Questa regola si applica inoltre a tali incarichi che facevano parte di test ampiamente utilizzati costruiti sui principi della teoria classica. Il test diventa più corto e quindi l'affidabilità è ridotta.
IRT offre modelli matematici per studiare i fenomeni veri. I modelli dovrebbero aiutarci a capire gli aspetti chiave di questi fenomeni. Tuttavia, la principale domanda teorica sta qui. I modelli possono essere considerati
approccio di Watikak allo studio della complessa realtà in cui viviamo. Ma il modello e la realtà non sono la stessa cosa. Secondo un look pessimistico, è possibile simulare solo un singolo (e moreant non il più interessante) tipi di comportamento. Puoi anche soddisfare la dichiarazione che la realtà non è soggetta a modellazione, perché Non obbedisce a una legge causale. Nel migliore dei casi, è possibile simulare fenomeni comportamentali individuali (ideali). C'è un altro, più ottimista, guarda la possibilità di modellare. La posizione di cui sopra blocca la possibilità di profonda comprensione della natura dei fenomeni del comportamento umano. L'uso di un particolare modello solleva alcune delle domande più fondamentali. A nostro avviso, non è dubbio che l'IRT sia il concetto di teoricamente e tecnicamente superiore alla teoria classica dei test.
Lo scopo pratico dei test, per qualsiasi base teorica, non sono creati, è quello di identificare criteri significativi e l'istituzione delle caratteristiche di determinati costrutti psicologici su di loro. Il modello IRT ha vantaggi e in questo senso? È possibile che i test creati sulla base di questo modello non forniscano previsioni più accurate rispetto ai test creati sulla base della teoria classica, ed è possibile che il loro contributo allo sviluppo di costrutti psicologici non sia più significativo. Le diagnosi preferiscono tali criteri che riguardano direttamente una persona separata, l'istituto o la comunità. Un modello, più perfetto in relazione scientifica, "Ipso Facto" * non definisce un criterio più adatto ed è una certa misura limitata nello spiegare i costrutti scientifici. Ovviamente, lo sviluppo dei test basato sulla teoria classica continuerà, ma allo stesso tempo verranno creati nuovi modelli IRT, estendendo allo studio di un numero maggiore di fenomeni psicologici.
Nella teoria del test classico, i concetti di "affidabilità" e "validità" sono distinti. I risultati di Teszeshai devono essere affidabili, cioè. I risultati del re-test iniziali e devono essere coordinati. Inoltre,
* ipso facto.(Vernice) - da per sé (circa Trans.).
i risultati devono essere liberi (per quanto possibile) dagli errori di valutazione. La presenza di validità è uno dei requisiti per i risultati ottenuti. In questo caso, l'affidabilità è considerata necessaria, ma non ancora una condizione sufficiente per la validità del test.
Il concetto di validità presuppone che i risultati ottenuti appartengono a qualsiasi cosa importante in relazioni pratiche o teoriche. Le conclusioni effettuate sulla base delle stime di test dovrebbero essere valide. Molto spesso parla di due tipi di validità: prognostico (criteri) e strutturale. Ci sono anche altri tipi di validità (cfr. 3). Inoltre, la validità può essere definita nel caso di quasi-esperimento (Campbell, 1976, cucinare & Shadish, 1994). Tuttavia, il tipo principale di validità è ancora la validità prognostica, in base alla quale è intesa come la capacità di prevedere qualcosa di significativo sul comportamento in futuro, nonché la possibilità di una comprensione più profonda di una o di un'altra proprietà psicologica o di qualità.
I tipi di validità presentati sono discussi in ciascuna directory e sono accompagnati da una descrizione dei metodi di analisi della validità del test. L'analisi del fattore è più adatta per determinare la convalida strutturale e le equazioni di regressione lineare vengono utilizzate per analizzare la validità prognostica. Queste o altre caratteristiche (prestazioni, efficienza terapia) possono essere previste sulla base di uno o più indicatori, mezzo scienziati quando si lavora con test intellettuali o personali. Tali tecniche di elaborazione dei dati, come correlazione, regressione, analisi della dispersione, analisi delle correlazioni parziali e dispersioni, servono a determinare la validità prognostica del test.
Descrive anche validità significativa. Si presume che tutte le attività e i compiti del test dovrebbero appartenere all'area specifica (proprietà mentali, comportamenti, ecc.). Il concetto di validità sostanziale caratterizza la corrispondenza di ciascun compito di test dell'area misurata. La validità sostanziale è talvolta considerata come parte dell'affidabilità o "generalizzata" (Cronbach, Glese, Nanda & Rajaratnam, 1972). tuttavia
anche la scelta dei compiti per i risultati dei risultati in una particolare area tematica è importante prestare attenzione alle regole per il compito nel test.
Nella classica teoria del test, affidabilità e validità sono considerati relativamente indipendenti l'uno dall'altro. Ma c'è un'altra comprensione del rapporto tra questi concetti. La teoria del test moderna si basa sull'uso dei modelli. I parametri sono stimati all'interno di un determinato modello. Se l'attività non soddisfa i requisiti del modello, entro il quadro di questo modello, è riconosciuto come non valido. La validazione strutturale è parte del controllo del modello stesso. Questa validazione si riferisce principalmente a verificare l'esistenza di una linea latente unidimensionale in studio con caratteristiche di scale noti. I gambetti saranno indubbiamente utilizzati per determinare i criteri corrispondenti e la loro correlazione è possibile con gli indicatori di altri costrutti per raccogliere informazioni sulla validità convergente e divergente del costrutto.
La psicodiagnosi è simile alla lingua descritta come l'unità di quattro componenti presentati a tre livelli. Il primo componente, la teoria dei test, simile alla sintassi, alla grammatica della lingua. Generazione della grammatica (generativa) è, da un lato, un modello spiritoso, dall'altro, il sistema subordinando le regole. Usando queste regole, complicate sono costruite sulla base di semplici proposte affettive. Allo stesso tempo, tuttavia, questo modello lascia a parte una descrizione di come è organizzato il processo di comunicazione (che viene trasmesso e ciò che è percepito), e con quale tipo di obiettivi è effettuato. Per capire ciò richiede una conoscenza aggiuntiva. Lo stesso si può dire della teoria dei test: è necessario in psicodiagnostica, ma non è in grado di spiegare quella psicodiagnosti e qual è il suo obiettivo.
1.3.2. Teorie psicologiche e costrutti psicologici
La psicodiagnostica è sempre una diagnosi di qualcosa di specifico: caratteristiche personali, comportamenti, pensiero, emozioni. I test sono destinati a valutare le differenze individuali. Ci sono diversi concetti
differenze individuali, ognuna delle quali ha le sue caratteristiche distintive. Se è riconosciuto che la psicodiagnostica non è limitata a una valutazione delle differenze individuali, quindi altre teorie sono essenziali per la psicodiagnostica. Un esempio è valutare le differenze nei processi di sviluppo mentale e nelle differenze nell'ambiente sociale. Sebbene la valutazione delle differenze individuali non sia un attributo indispensabile della psicodiagnostica, tuttavia ci sono alcune tradizioni di ricerca in questo settore. Le psicodiagnostiche sono iniziate con una valutazione delle differenze di intelligence. Il compito principale dei test era "determinare la trasmissione ereditaria del genio" (gallone) o la selezione dei bambini per la formazione (Binet, Simon). Misurare il coefficiente di intellettività ha ricevuto la comprensione teorica e lo sviluppo pratico nelle opere di Spirfernd (Regno Unito) e Terestone (USA). Raymond B.qottel ha reso questo simile alla valutazione delle caratteristiche personali. La psicodiagnostica diventa inestricabilmente legata con teorie e idee sulle differenze individuali nei risultati (valutazione dei limiti) e delle forme di comportamento (livello di funzionamento tipico). Questa tradizione continua a rimanere efficace oggi. Nell'insegnamento dei benefici sulla psicodiagnostica, le differenze nell'ambiente sociale sono molto meno valutate rispetto alla considerazione delle peculiarità dei processi di sviluppo stessi. Per questo, non ci sono spiegazioni ragionevoli. Da un lato, la diagnosi non è limitata a determinate teorie e concetti. D'altra parte, ha bisogno di teorie, poiché è proprio in essi un contenuto diagnostico (cioè "che" è diagnosticato). Ad esempio, l'intelligenza può anche essere considerata come una caratteristica generale e come base per una varietà di abilità indipendenti. Se la psicodiagnostica cerca di "lasciare" da una o un'altra teoria, la base di un processo psicodiagnostico diventa le idee del buon senso. Gli studi utilizzano vari modi per analizzare i dati, e la logica generale della ricerca determina la scelta di un modello matematico e determina la struttura dei concetti psicologici utilizzati. Tali metodi di statistica matematica
ki, come analisi della dispersione, analisi di regressione, analisi dei fattori, il conteggio delle correlazioni implica l'esistenza di dipendenze lineari. In caso di uso errato di questi metodi, "portano" la struttura ai dati ottenuti e i costrutti utilizzati.
Le idee sulle differenze nell'ambiente sociale e lo sviluppo della personalità non hanno quasi influenzato la psicodiagnostica. Nei libri di testo (vedi, ad esempio, Murphy & Davidshofer, 1988), viene considerata la teoria dei test classici e sono discussi i metodi pertinenti di elaborazione statistica, sono descritti i test noti, vengono descritti l'uso della psicodiagnostica nella pratica: nel Psicologia della gestione, nella selezione del personale, nel valutare le caratteristiche psicologiche della persona.
Le teorie delle differenze individuali (così come le idee sulle differenze tra l'ambiente sociale e lo sviluppo mentale) sono simili allo studio della semantica della lingua. Questo è lo studio ed l'entità e il contenuto e i valori. I valori sono strutturati in un certo modo (come costrutti psicologici), ad esempio, in similitudine o contrasto (analogia, convergenza, divergenza).
1.3.3. Test psicologici e altri mezzi metodologici
Il terzo componente del circuito proposto, procedure e mezzi metodologici mediante il quale le informazioni vengono raccolte sulle caratteristiche della personalità. Draza e Seitsma (1990, pag. 31) Dare i seguenti test di definizione: "Il test psicologico è considerato come una classificazione in base a un determinato sistema o come una procedura di misurazione che consente di effettuare un certo giudizio su uno o più empiricamente dedicato o caratteristiche teoricamente ragionevoli di una determinata persona di comportamento umano (per fotogrammi di una situazione di prova). Allo stesso tempo, la reazione degli intervistati è considerata su un certo numero di incentivi accuratamente selezionati e le risposte ricevute sono confrontate con gli standard di prova. "
Diagnostica richiede test e tecniche per la raccolta di informazioni affidabili, accurate e valide sulle funzionalità.
e caratteristiche caratteristiche della persona, del pensiero, delle emozioni e del comportamento umano. Oltre allo sviluppo di procedure di prova, questo componente include anche le seguenti domande: come vengono creati i test, come si seleziona e le attività sono selezionate, poiché il processo di test procede, quali sono i requisiti per le condizioni di test, poiché gli errori di misurazione sono preso in considerazione, i risultati dei test vengono conteggiati e interpretati.
Nel processo di sviluppo di test, strategie razionali ed empiriche differiscono. L'applicazione di una strategia razionale inizia con la definizione dei concetti di base (ad esempio, il concetto di intelligenza, estroversione), e in conformità con queste idee, i compiti del test sono formulati. Un esempio di tale strategia può essere il concetto di analisi degli aspetti (la teoria delle faccette) Guttman (1957, 1968, 1978). Innanzitutto, vengono determinati vari aspetti del costrutto principale, quindi le attività e le attività sono selezionate in modo tale che ciascuno di questi aspetti sia preso in considerazione. La seconda strategia è che i compiti sono selezionati su base empirica. Ad esempio, se un ricercatore cerca di creare una prova di interessi professionali, che consentirebbe la differenziazione dei medici di ingegneri, la procedura dovrebbe essere così. Entrambi i gruppi di intervistati devono rispondere a tutti i compiti del test, e tali articoli, nelle risposte alle quali vengono rilevate differenze statisticamente significative, sono incluse nella versione finale del test. Se, ad esempio, ci sono differenze tra i gruppi nelle risposte all'approvazione "Mi piace catturare il pesce", quindi questa affermazione diventa un elemento del test. La posizione principale di questo libro è che il test è associato a una teoria concettuale o tassonomica che definisce queste caratteristiche.
L'assegnazione del test è solitamente definita nelle istruzioni per il suo utilizzo. Il test deve essere standardizzato per consentire di stimare le differenze tra le persone e non tra le condizioni di prova. Ci sono, tuttavia, le deviazioni dalla standardizzazione nelle procedure chiamate "test dei confini delle possibilità" (testando i limiti) e "test dei potenziali test" test "(apprendimento dei potenziali test). In queste condizioni, il convenuto è l'assistenza nel processo.
test e quindi l'influenza di tale procedura per il risultato è stimata. I punti di conteggio per le risposte alle attività sono obiettivi, cioè. Viene eseguito in conformità con la procedura standard. L'interpretazione dei risultati ottenuti è anche rigorosamente definita ed è effettuata sulla base delle norme di test.
Il terzo componente della psicodiagnostica è test psicologici, strumenti, procedure - contiene determinati compiti, che sono le unità più basse della psicodiagnostica e in questo senso del compito sono simili alle lingue. Il numero di possibili combinazioni del gioco del telefono è limitato. Solo alcune strutture più fondetiche possono formare parole e proposte per garantire informazioni all'ascoltatore. Anche etest Attività: Solo in una certa combinazione l'uno con l'altro, possono diventare un mezzo efficace per valutare il costrutto corrispondente.