Fondamenti matematici della teoria del test design. Caratteristiche dei test di controllo nell'educazione fisica
Leggi anche
Descrizione della presentazione per singole slide:
1 diapositiva
Descrizione della diapositiva:
2 diapositive
Descrizione della diapositiva:
È consuetudine chiamare qualità fisiche innate (geneticamente ereditate) qualità morfologiche e funzionali, grazie alle quali è possibile l'attività umana fisica (espressa materialmente), che riceve la sua piena manifestazione nell'attività motoria intenzionale. Le principali qualità fisiche includono forza, velocità, resistenza, flessibilità, agilità.
3 diapositive
Descrizione della diapositiva:
Le capacità motorie sono caratteristiche individuali che determinano il livello delle capacità motorie di una persona (V. I. Lyakh, 1996). La base delle capacità motorie di una persona è costituita da qualità fisiche e la forma di manifestazione sono le capacità e le capacità motorie. Le abilità motorie includono potenza, alta velocità, velocità-potenza, capacità di coordinazione motoria, resistenza generale e specifica
4 diapositive
Descrizione della diapositiva:
Schema di sistematizzazione delle capacità fisiche (motorie) Abilità fisiche (motorie) Condizionamento (energetico) Potenza Combinazioni di capacità di condizionamento Resistenza Velocità Flessibilità Coordinazione (informativa) CS relativo a gruppi separati di azioni motorie, CS speciale CS specifico Combinazioni di abilità coordinative Combinazioni delle capacità di condizionamento e coordinazione
5 diapositive
Descrizione della diapositiva:
OTTENERE INFORMAZIONI ACCURATE SUL LIVELLO DI SVILUPPO DELLA CAPACITÀ MOTORIA / alto, medio, basso / È POSSIBILE CON L'AIUTO DI TEST / o esercizi di controllo /.
6 diapositive
Descrizione della diapositiva:
Con l'aiuto di test di controllo (test), è possibile rivelare gli indicatori assoluti (espliciti) e relativi (nascosti, latenti) di queste abilità. Gli indici assoluti caratterizzano il livello di sviluppo di alcune capacità motorie senza tener conto della loro influenza reciproca. Gli indicatori relativi consentono di giudicare la manifestazione delle capacità motorie, tenendo conto di questa influenza.
7 diapositiva
Descrizione della diapositiva:
Le suddette capacità fisiche possono essere presentate come esistenti potenzialmente, cioè prima dell'inizio di qualsiasi attività o attività motoria (possono essere chiamate capacità potenziali) e come manifestarsi nella realtà all'inizio (anche durante l'esecuzione di test motori) e in il processo di esecuzione di queste attività (capacità fisiche effettive).
8 diapositive
Descrizione della diapositiva:
Con un certo grado di convenzione si può parlare di capacità fisiche ELEMENTARI e capacità fisiche COMPLESSE
9 diapositiva
Descrizione della diapositiva:
I RISULTATI DELLA RICERCA PERMETTONO DI DISTINGUERE LE SEGUENTI CAPACITÀ FISICHE SPECIALI SPECIFICHE GENERALI COP
10 diapositive
Descrizione della diapositiva:
Le abilità fisiche speciali si riferiscono a gruppi omogenei di azioni o attività motorie integrali: corsa, esercizi acrobatici e ginnici su attrezzo, azioni motorie di lancio, giochi sportivi (pallacanestro, pallavolo).
11 diapositiva
Descrizione della diapositiva:
Le manifestazioni specifiche delle capacità fisiche possono essere definite come i componenti che costituiscono la loro struttura interna.
12 diapositive
Descrizione della diapositiva:
Pertanto, le componenti principali delle capacità coordinative di una persona sono: la capacità di orientare, bilanciare, rispondere, differenziare i parametri dei movimenti; capacità di ritmo, riorganizzazione delle azioni motorie, stabilità vestibolare, rilassamento muscolare volontario. Queste abilità sono specifiche.
13 diapositive
Descrizione della diapositiva:
I componenti principali della struttura delle abilità di velocità sono considerati la velocità di risposta, la velocità di un singolo movimento, la frequenza dei movimenti e la velocità manifestata nelle azioni motorie integrali.
14 diapositive
Descrizione della diapositiva:
Le manifestazioni delle abilità di forza includono: forza statica (isometrica), forza dinamica (isotonica) - forza esplosiva, che assorbe gli urti.
15 diapositive
Descrizione della diapositiva:
La struttura della resistenza è molto complessa: aerobica, che richiede fonti di ossigeno di scomposizione energetica per la sua manifestazione; anaerobico (fonti di energia glicolitica, creatina fosfato - senza la partecipazione di ossigeno); resistenza di vari gruppi muscolari in posizioni statiche - resistenza statica; resistenza in esercizi dinamici eseguiti a una velocità del 20-90% del massimo.
16 diapositive
Descrizione della diapositiva:
Meno complesse sono le manifestazioni (forme) di flessibilità, dove si distingue la flessibilità attiva e quella passiva.
17 diapositiva
Descrizione della diapositiva:
Le capacità fisiche generali dovrebbero essere intese come le capacità potenziali e realizzate di una persona, che determinano la sua prontezza per l'attuazione riuscita di azioni motorie, diverse per origine e significato. Le abilità fisiche speciali sono le capacità di una persona che determinano la sua prontezza per l'attuazione riuscita di azioni motorie simili per origine e significato. Pertanto, i test forniscono informazioni, prima di tutto, sul grado di formazione di abilità fisiche speciali e specifiche (velocità, coordinazione, forza, resistenza, flessibilità).
18 diapositive
Descrizione della diapositiva:
Le abilità fisiche speciali sono le capacità di una persona che determinano la sua prontezza per l'attuazione di successo di azioni motorie simili per origine e significato. Pertanto, i test forniscono informazioni, prima di tutto, sul grado di formazione di abilità fisiche speciali e specifiche (velocità, coordinazione, forza, resistenza, flessibilità).
19 diapositiva
Descrizione della diapositiva:
I compiti del test sono identificare i livelli di sviluppo delle capacità di condizionamento e coordinazione, per valutare la qualità della prontezza tecnica e tattica. Sulla base dei risultati del test, è possibile: confrontare la preparazione sia dei singoli studenti che di interi gruppi che vivono in diverse regioni e paesi; condurre una selezione sportiva per praticare uno sport particolare, per partecipare a competizioni; effettuare in larga misura un controllo oggettivo sull'istruzione (formazione) degli scolari e dei giovani atleti; identificare i vantaggi e gli svantaggi degli strumenti utilizzati, dei metodi di insegnamento e delle forme di organizzazione delle lezioni; infine, sostanziare le norme (età, individuo) di idoneità fisica dei bambini e degli adolescenti.
20 diapositive
Descrizione della diapositiva:
Insieme ai compiti di cui sopra nella pratica dei diversi paesi, i compiti del test sono ridotti ai seguenti: insegnare agli scolari stessi a determinare il livello della loro idoneità fisica e pianificare i necessari complessi di esercizi fisici; stimolare gli studenti a migliorare ulteriormente la loro condizione fisica (forma); conoscere non tanto il livello iniziale di sviluppo della capacità motoria quanto il suo cambiamento in un certo tempo; stimolare gli studenti che hanno raggiunto risultati elevati, ma non tanto per un livello elevato, quanto per l'aumento pianificato dei risultati personali.
21 diapositiva
Descrizione della diapositiva:
Un test è una misurazione o un test effettuato per determinare l'abilità o la condizione di una persona.
22 diapositiva
Descrizione della diapositiva:
Solo quei test (campioni) che soddisfano requisiti speciali possono essere utilizzati come test: deve essere determinato lo scopo dell'applicazione di qualsiasi test (o test); dovrebbero essere sviluppati un metodo di misurazione e una procedura di prova standardizzati; è necessario determinare l'affidabilità e il contenuto informativo dei test; i risultati dei test possono essere riportati nel sistema di classificazione appropriato
23 diapositiva
Descrizione della diapositiva:
Test. Test. Risultato del test Il sistema di utilizzo dei test in base al compito da svolgere, organizzazione delle condizioni, esecuzione di test per soggetti, valutazione e analisi dei risultati è chiamato test. Il valore numerico ottenuto nel corso delle misurazioni è il risultato del test (test).
24 diapositive
Descrizione della diapositiva:
I test utilizzati nella cultura fisica si basano su azioni motorie (esercizi fisici, compiti motori). Questi test sono chiamati test motori o motori.
25 diapositive
Descrizione della diapositiva:
È nota la classificazione delle prove secondo la loro struttura e secondo le loro indicazioni predominanti si distinguono prove singole e complesse. Un singolo test viene utilizzato per misurare e valutare un attributo (capacità di coordinazione o condizionamento).
26 diapositiva
Descrizione della diapositiva:
27 diapositive
Descrizione della diapositiva:
Con l'aiuto di un test complesso, vengono valutate diverse caratteristiche o componenti di abilità diverse o uguali. per esempio, un salto da un luogo (con un'onda delle braccia, senza un'onda delle braccia, ad una data altezza).
28 diapositive
Descrizione della diapositiva:
29 diapositive
Descrizione della diapositiva:
I TEST possono essere test di condizionamento per valutare la capacità di forza per valutare la resistenza; valutare le capacità di velocità; per valutare la flessibilità, test di coordinazione per valutare le abilità di coordinazione relative a gruppi indipendenti separati di azioni motorie, che misurano abilità di coordinazione speciali; valutare specifiche capacità di coordinazione - capacità di equilibrio, orientamento nello spazio, risposta, differenziazione dei parametri di movimento, ritmo, ristrutturazione delle azioni motorie, coordinazione (comunicazione), stabilità vestibolare, rilassamento muscolare volontario).
30 diapositive
Descrizione della diapositiva:
Ogni classificazione è una sorta di linee guida per la selezione (o creazione) del tipo di test più rilevanti per gli obiettivi del test.
31 diapositiva
Descrizione della diapositiva:
CRITERI DELLA GENTILEZZA DELLE PROVE MOTORIE Il concetto di "prova motoria" raggiunge il suo scopo quando il test soddisfa i criteri di base pertinenti: affidabilità, stabilità, equivalenza, obiettività, contenuto informativo (validità), nonché criteri aggiuntivi: standardizzazione, comparabilità ed economia. I test che soddisfano i requisiti di affidabilità e contenuto informativo sono chiamati di buona qualità o autentici (affidabili).
32 diapositive
Descrizione della diapositiva:
L'affidabilità del test è intesa come il grado di accuratezza con cui valuta una certa capacità motoria, indipendentemente dalle esigenze di chi la valuta. L'affidabilità si manifesta nel grado di coincidenza dei risultati quando si ritestano le stesse persone nelle stesse condizioni; è la stabilità o la consistenza del risultato del test di un individuo quando viene ripetuto l'esercizio di controllo. In altre parole, il bambino nel gruppo di quelli esaminati in base ai risultati di test ripetuti (ad esempio indicatori di salto, tempo di corsa, distanza di lancio) mantiene costantemente il suo posto di rango. L'affidabilità del test viene determinata utilizzando la correlazione e l'analisi statistica calcolando il fattore di affidabilità. Allo stesso tempo, vengono utilizzati vari metodi, in base ai quali viene giudicata l'affidabilità del test.
33 diapositiva
Descrizione della diapositiva:
La stabilità del test si basa sul rapporto tra il primo e il secondo tentativo, ripetuto dopo un certo tempo nelle stesse condizioni dallo stesso sperimentatore. Il modo per ripetere il test per determinare l'affidabilità è chiamato ripetizione del test. La stabilità del test dipende dal tipo di test, dall'età e dal sesso dei soggetti, dall'intervallo di tempo tra il test e il nuovo test. Ad esempio, gli indici dei test di condizionamento o dei tratti morfologici a brevi intervalli di tempo sono più stabili dei risultati dei test di coordinazione; per i bambini più grandi i risultati sono più stabili rispetto ai bambini più piccoli. Il nuovo test viene solitamente eseguito entro e non oltre una settimana. A intervalli più lunghi (ad esempio, dopo un mese), la stabilità anche di test come la corsa di 1000 metri o il salto in lungo da un luogo diventa notevolmente inferiore.
34 diapositiva
Descrizione della diapositiva:
Equivalenza del test L'equivalenza del test è la correlazione del risultato del test con i risultati di altri test dello stesso tipo. Ad esempio, quando è necessario scegliere quale test rispecchia più adeguatamente le capacità di velocità: correre a metri 30, 50, 60 o 100. L'attitudine a prove equivalenti (omogenee) dipende da molte ragioni. Se è necessario aumentare l'affidabilità delle stime o delle conclusioni dello studio, è consigliabile utilizzare due o più test equivalenti. E se l'obiettivo è creare una batteria che contenga un minimo di test, allora dovrebbe essere utilizzato solo uno dei test equivalenti. Una tale batteria, come notato, è eterogenea, poiché i test in essa inclusi misurano diverse capacità motorie. Esempi di una batteria eterogenea di test sono 30 m di corsa, trazioni alla sbarra, piegamento in avanti, 1000 m di corsa.
35 diapositiva
Descrizione della diapositiva:
L'affidabilità dei test è determinata anche confrontando i punteggi medi dei tentativi pari e dispari inclusi nel test. Ad esempio, la media dei lanci al bersaglio da 1, 3, 5, 7 e 9 tentativi viene confrontata con la media dei lanci al bersaglio da 2, 4, 6, 8 e 10 tentativi. Questo metodo di valutazione dell'affidabilità è chiamato metodo del raddoppio o divisione. Viene utilizzato principalmente nella valutazione delle capacità di coordinazione e nel caso in cui il numero di tentativi che costituiscono il risultato del test non sia inferiore a sei.
36 diapositive
Descrizione della diapositiva:
Oggettività (coerenza) del test Per obiettività (coerenza) del test si intende il grado di coerenza dei risultati ottenuti sulle stesse materie da sperimentatori diversi (docenti, giudici, esperti). Per aumentare l'obiettività del test, è necessario rispettare le condizioni standard di test: tempo, luogo, condizioni meteorologiche del test; materiale unificato e supporto hardware; fattori psicofisiologici (volume e intensità del carico, motivazione); presentazione delle informazioni (formulazione verbale precisa del problema del test, spiegazione e dimostrazione). Questa è la cosiddetta obiettività del test. Si parla anche di oggettività interpretativa, riferendosi al grado di indipendenza dell'interpretazione dei risultati dei test da parte di diversi sperimentatori.
37 diapositiva
Descrizione della diapositiva:
In generale, come notano gli esperti, l'affidabilità dei test può essere migliorata in vari modi: mediante una più rigorosa standardizzazione dei test, un aumento del numero di tentativi, una migliore motivazione dei soggetti, un aumento del numero dei valutatori (giudici, esperti), un aumento della coerenza delle loro opinioni e un aumento del numero di test equivalenti. Non ci sono valori fissi per gli indicatori di affidabilità dei test. Nella maggior parte dei casi, utilizzano le seguenti raccomandazioni: 0,95 - 0,99 - eccellente affidabilità; 0,90 - 0,94 - buono; 0,80 - 0,89 - accettabile; 0,70 - 0,79 - cattivo; 0,60 - 0,69 - dubbio per valutazioni individuali, il test è adatto solo per caratterizzare un gruppo di soggetti.
38 diapositive
Descrizione della diapositiva:
L'informatività di un test è il grado di accuratezza con cui misura un'abilità o abilità motoria valutata. Nella letteratura straniera (e domestica), invece della parola "informatività", viene utilizzato il termine "validità" (dall'inglese Validità-validità, validità, legalità). Infatti, parlando di contenuto informativo, il ricercatore risponde a due domande: cosa misura questo particolare test (batteria di test) e qual è il grado di accuratezza della misurazione. Esistono diversi tipi di validità: logica (significativa), empirica (basata su dati sperimentali) e predittiva.
39 diapositiva
Descrizione della diapositiva:
Importanti criteri di test aggiuntivi, come notato, sono la standardizzazione, la comparabilità e l'efficacia dei costi. L'essenza della standardizzazione è che sulla base dei risultati dei test è possibile creare norme di particolare importanza per la pratica. La comparabilità dei test è la capacità di confrontare i risultati ottenuti da una o più forme di test paralleli (omogenei). In termini pratici, l'uso di test motori comparabili riduce la probabilità che, a seguito dell'uso regolare dello stesso test, non venga valutato solo e non tanto il livello di abilità, quanto il grado di abilità. I risultati dei test confrontati simultaneamente aumentano l'affidabilità delle conclusioni. L'essenza dell'economia come criterio della bontà del test è che il test non richiede molto tempo, grandi costi materiali e la partecipazione di molti assistenti.
40 diapositive
Descrizione della diapositiva:
ORGANIZZAZIONE DELLA VERIFICA DELLA PREPARAZIONE DEI BAMBINI IN ETÀ SCOLASTICA Il secondo problema importante della verifica delle capacità motorie (ricordiamo che il primo è la selezione dei test informativi, è l'organizzazione della loro applicazione. test I tempi dei test sono coerenti con il curriculum scolastico, che prevede per il doppio test obbligatorio di idoneità fisica degli studenti.
41 diapositiva
Descrizione della diapositiva:
La conoscenza dei cambiamenti annuali nello sviluppo delle capacità motorie dei bambini consente all'insegnante di apportare adeguamenti appropriati al processo di cultura fisica per il prossimo anno accademico. Tuttavia, l'insegnante deve e può condurre test più frequenti, condurre il cosiddetto controllo operativo. È consigliabile farlo per determinare, ad esempio, i cambiamenti nel livello di velocità, forza e resistenza sotto l'influenza delle lezioni di atletica leggera durante il primo trimestre. A tal fine, l'insegnante può utilizzare test per valutare le capacità di coordinazione dei bambini all'inizio e alla fine della padronanza del materiale del programma, ad esempio nei giochi sportivi, per identificare i cambiamenti negli indicatori dello sviluppo di queste abilità .
42 diapositiva
Descrizione della diapositiva:
Va tenuto presente che la varietà di problemi pedagogici da risolvere non consente di fornire all'insegnante una metodologia di test unificata, le stesse regole per lo svolgimento dei test e la valutazione dei risultati dei test. Ciò richiede che gli sperimentatori (insegnanti) dimostrino indipendenza nella risoluzione dei problemi teorici, metodologici e organizzativi dei test. Il test nella lezione deve essere collegato al suo contenuto. In altre parole, la prova o le prove applicate, fatte salve le corrispondenti prescrizioni (rispetto al metodo di ricerca), dovrebbero essere organicamente incluse nell'esercizio fisico pianificato. Se, ad esempio, i bambini devono determinare il livello di sviluppo delle capacità di velocità o resistenza, i test necessari dovrebbero essere pianificati in quella parte della lezione in cui verranno risolti i compiti di sviluppo delle capacità fisiche corrispondenti.
43 diapositiva
Descrizione della diapositiva:
La frequenza dei test è in gran parte determinata dal tasso di sviluppo di specifiche capacità fisiche, età-sesso e caratteristiche individuali del loro sviluppo. Ad esempio, per ottenere un aumento significativo della velocità, della resistenza o della forza, sono necessari diversi mesi di esercizio fisico regolare (allenamento). Allo stesso tempo, per ottenere un aumento affidabile della flessibilità o delle capacità di coordinazione individuale, sono necessari solo 4-12 allenamenti. È possibile ottenere un miglioramento della qualità fisica se si parte da zero in un periodo di tempo più breve. E per migliorare la stessa qualità, quando è in un bambino di alto livello, ci vuole più tempo. A questo proposito, l'insegnante dovrebbe approfondire le caratteristiche dello sviluppo e del miglioramento delle diverse capacità motorie nei bambini di età e sesso diversi.
44 diapositiva
Descrizione della diapositiva:
Nel valutare l'idoneità fisica generale dei bambini, è possibile utilizzare un'ampia varietà di batterie di test, la cui scelta dipende dalle specifiche attività di test e dalla disponibilità delle condizioni necessarie. Tuttavia, poiché i risultati dei test ottenuti possono essere valutati solo per confronto, è consigliabile scegliere test ampiamente rappresentati nella teoria e nella pratica dell'educazione fisica dei bambini. Ad esempio, affidati a quelli consigliati nel programma FC. Per confrontare il livello generale di forma fisica di uno studente o di un gruppo di studenti utilizzando una serie di test, si ricorre alla traduzione dei risultati dei test in punti o punti. La modifica della somma dei punti durante i test ripetuti consente di giudicare i progressi sia di un singolo bambino che di un gruppo di bambini.
49 diapositiva
Descrizione della diapositiva:
Un aspetto importante del test è il problema della scelta di un test per valutare una specifica capacità fisica e la forma fisica generale.
50 diapositive
Descrizione della diapositiva:
Consigli pratici e consigli. IMPORTANTE: determinare (selezionare) una batteria (o un insieme) di test necessari con una dichiarazione dettagliata di tutti i dettagli della loro condotta; Impostare il tempo di prova (meglio - 2-3 settimane di settembre - 1a prova, 2-3 settimane di maggio - 2a prova); In conformità con la raccomandazione, determinare con precisione l'età dei bambini il giorno del test e il loro genere; Sviluppare protocolli uniformi per la registrazione dei dati (possibilmente basati sull'uso dell'ICT); Determinare la cerchia degli assistenti ed eseguire la procedura di test stessa; Esegui immediatamente l'elaborazione matematica dei dati del test - calcolando i principali parametri statistici (media aritmetica, errore medio aritmetico, deviazione standard, coefficiente di variazione e valutando l'affidabilità delle differenze tra indicatori di media aritmetica, ad esempio classi parallele dello stesso e diverse scuole di ragazzi della stessa età e sesso); Una delle fasi significative del lavoro può essere la traduzione dei risultati dei test in punti o punti. Con test regolari (2 volte l'anno, per diversi anni), questo permetterà all'insegnante di avere un'idea dell'andamento dei risultati.
51 diapositive
Descrizione della diapositiva:
Mosca "Illuminismo" 2007 Il libro contiene i test motori più comuni per valutare le capacità di condizionamento e coordinazione degli studenti. Il manuale prevede un approccio individuale di un insegnante di educazione fisica a ogni studente specifico, tenendo conto della sua età e del suo fisico.
Concetti di base della teoria dei test.
Una misurazione o un test effettuato per determinare la condizione o l'abilità di un atleta è chiamato test. Qualsiasi test include la misurazione. Ma non tutti i cambiamenti sono un test. La procedura di misurazione o test è chiamata test.
Un test basato su compiti motori è chiamato test motorio. Ci sono tre gruppi di test di movimento:
- 1. Esercizi di controllo, eseguendo i quali l'atleta riceve il compito di mostrare il massimo risultato.
- 2. Test funzionali standard, durante i quali il compito, che è lo stesso per tutti, è dosato o dalla quantità di lavoro svolto, o dalla quantità di turni fisiologici.
- 3. Test funzionali massimi, durante i quali l'atleta deve mostrare il massimo risultato.
I test di alta qualità richiedono la conoscenza della teoria della misurazione.
Concetti di base della teoria della misura.
La misurazione è l'identificazione della corrispondenza tra il fenomeno in esame, da un lato, ei numeri, dall'altro.
Le basi della teoria della misura sono tre concetti: scale di misura, unità di misura e precisione di misura.
Scale di misura.
Una scala di misurazione è la legge in base alla quale un valore numerico viene assegnato a un risultato misurato man mano che aumenta o diminuisce. Consideriamo alcune delle scale utilizzate nello sport.
Scala dei nomi (scala nominale).
Questa è la più semplice di tutte le scale. In esso, i numeri fungono da etichette e servono a rilevare e distinguere gli oggetti oggetto di studio (ad esempio, la numerazione dei giocatori di una squadra di calcio). I numeri che compongono la scala dei nomi possono essere modificati con metas. Non ci sono relazioni più-meno su questa scala, quindi alcune persone pensano che la scala dei nomi non dovrebbe essere considerata una misura. Quando si utilizza la scala dei nomi, è possibile eseguire solo alcune operazioni matematiche. Ad esempio, i suoi numeri non possono essere aggiunti o sottratti, ma puoi contare quante volte (quanto spesso) si verifica un determinato numero.
Scala degli ordini.
Ci sono sport in cui il risultato di un atleta è determinato solo dal posto occupato nella competizione (ad esempio, le arti marziali). Dopo tali competizioni, è chiaro quale degli atleti è più forte e quale è più debole. Ma quanto più forte o più debole, non si può dire. Se tre atleti hanno ottenuto rispettivamente il primo, il secondo e il terzo posto, allora quali sono le differenze nella loro sportività rimane poco chiaro: il secondo atleta potrebbe essere quasi uguale al primo, o potrebbe essere più debole di lui ed essere quasi lo stesso con il terzo. I posti occupati nella scala d'ordine sono chiamati ranghi e la scala stessa è chiamata rango o non metrico. In tale scala, i suoi numeri costitutivi sono ordinati per ranghi (cioè posti occupati), ma gli intervalli tra loro non possono essere misurati con precisione. In contrasto con la scala dei nomi, la scala dell'ordine consente non solo di stabilire il fatto dell'uguaglianza o della disuguaglianza degli oggetti misurati, ma anche di determinare la natura della disuguaglianza sotto forma di giudizi: "più - meno", "meglio - peggio", ecc.
Usando scale di ordine, puoi misurare indicatori qualitativi che non hanno una misura quantitativa rigorosa. Queste scale sono particolarmente utilizzate nelle discipline umanistiche: pedagogia, psicologia, sociologia.
Più operazioni matematiche possono essere applicate ai ranghi della scala d'ordine che ai numeri della scala di denominazione.
Scala dell'intervallo.
È una scala in cui i numeri non sono solo ordinati per rango, ma anche separati da intervalli specifici. Una caratteristica che lo distingue dalla scala delle relazioni descritta di seguito è che il punto zero è scelto arbitrariamente. Gli esempi includono il tempo del calendario (l'inizio della cronologia in diversi calendari è stato impostato per ragioni casuali), l'angolo articolare (l'angolo nell'articolazione del gomito con l'estensione completa dell'avambraccio può essere considerato zero o 180 °), la temperatura, l'energia potenziale del carico sollevato, potenziale del campo elettrico, ecc. dr.
I risultati delle misurazioni sulla scala degli intervalli possono essere elaborati con tutti i metodi matematici, ad eccezione del calcolo dei rapporti. Queste scale di intervalli danno una risposta alla domanda: "quanto di più", ma non consentono di affermare che un valore del valore misurato sia tante volte maggiore o minore di un altro. Ad esempio, se la temperatura è aumentata da 10 a 20 C, non si può dire che sia diventata due volte più calda.
Scala delle relazioni.
Questa scala differisce dalla scala degli intervalli solo in quanto definisce rigorosamente la posizione del punto zero. Per questo motivo, la scala dei rapporti non impone alcuna restrizione all'apparato matematico utilizzato per elaborare i risultati delle osservazioni.
Negli sport, la scala delle relazioni misura distanza, forza, velocità e dozzine di altre variabili. La scala delle relazioni misura anche quei valori che si formano come differenza tra i numeri contati sulla scala degli intervalli. Quindi, il tempo del calendario viene contato su una scala di intervalli e intervalli di tempo - su una scala di relazioni. Quando si utilizza la scala dei rapporti (e solo in questo caso!), La misurazione di qualsiasi quantità è ridotta alla determinazione sperimentale del rapporto di questa quantità con un'altra quantità simile, presa come unità. Misurando la lunghezza del salto, scopriamo quante volte questa lunghezza è maggiore della lunghezza di un altro corpo, presa come unità di lunghezza (righello del metro in un caso particolare); pesando il bilanciere, determiniamo il rapporto tra la sua massa e la massa di un altro corpo: un "chilogrammo" di peso unitario, ecc. Se ci limitiamo solo all'uso delle scale di relazione, allora possiamo dare un'altra definizione (più stretta, particolare) di misura: misurare una qualsiasi quantità significa trovare empiricamente la sua relazione con l'unità di misura corrispondente.
Unità di misura.
Affinché i risultati di misurazioni diverse possano essere confrontati tra loro, devono essere espressi nelle stesse unità. Nel 1960, alla Conferenza generale internazionale sui pesi e le misure, fu adottato il Sistema internazionale di unità, che fu abbreviato in SI (dalle lettere iniziali delle parole Sistema internazionale). Attualmente, l'applicazione preferita di questo sistema è stata stabilita in tutti i campi della scienza e della tecnologia, nell'economia nazionale e nell'insegnamento.
SI attualmente comprende sette unità di base indipendenti (vedi tabella 2.1.)
Tabella 1.1.
Le unità di altre grandezze fisiche sono derivate da queste unità di base come derivati. Le unità derivate sono determinate sulla base di formule che collegano grandezze fisiche. Ad esempio, l'unità di lunghezza (metro) e l'unità di tempo (secondo) sono le unità di base e l'unità di velocità (metro al secondo) è la derivata.
Oltre a quelle principali, in SI sono evidenziate due unità aggiuntive: radiante - un'unità di un angolo piatto e steradiante - un'unità di un angolo solido (angolo nello spazio).
Precisione delle misurazioni.
Nessuna misurazione può essere eseguita con precisione assoluta. Il risultato della misurazione contiene inevitabilmente un errore, la cui entità è minore, più accurato è il metodo di misurazione e il dispositivo di misurazione. Ad esempio, utilizzando un righello normale con divisioni millimetriche, non è possibile misurare la lunghezza con una precisione di 0,01 mm.
Errore di base e aggiuntivo.
L'errore di base è l'errore di un metodo di misurazione o di uno strumento di misurazione che si verifica in normali condizioni di utilizzo.
L'errore aggiuntivo è l'errore del dispositivo di misurazione causato dalla deviazione delle sue condizioni operative dal normale. È chiaro che i dispositivi progettati per funzionare a temperatura ambiente daranno letture imprecise se vengono utilizzati in estate allo stadio sotto il sole cocente o in inverno al freddo. Errori di misura possono verificarsi quando la tensione di rete o di alimentazione a batteria è al di sotto del normale o di valore non costante.
Errori assoluti e relativi.
Il valore E = A - Ao, pari alla differenza tra la lettura del dispositivo di misura (A) e il vero valore della grandezza misurata (Ao), è chiamato errore di misura assoluto. Viene misurato nelle stesse unità del valore misurato stesso.
In pratica, spesso è conveniente utilizzare non un errore assoluto, ma relativo. L'errore di misurazione relativo è di due tipi: reale e ridotto. L'errore relativo effettivo è il rapporto tra l'errore assoluto e il valore vero della quantità misurata:
A D = --------- * 100%
L'errore relativo ridotto è il rapporto tra l'errore assoluto e il valore massimo possibile della grandezza misurata:
Ap = ---------- * 100%
Errori sistematici e casuali.
Sistematico è un errore, il cui valore non cambia da misurazione a misurazione. A causa di questa peculiarità, l'errore sistematico spesso può essere previsto in anticipo o, in casi estremi, rilevato ed eliminato al termine del processo di misurazione.
Il modo per eliminare l'errore sistematico dipende principalmente dalla sua natura. Gli errori sistematici di misurazione possono essere suddivisi in tre gruppi:
errori di origine nota e valore noto;
errori di origine nota, ma di entità sconosciuta;
errori di origine sconosciuta e di valore sconosciuto. I più innocui sono gli errori del primo gruppo. Si eliminano facilmente
introducendo opportune correzioni al risultato della misurazione.
Il secondo gruppo comprende, prima di tutto, gli errori associati all'imperfezione del metodo di misurazione e dell'attrezzatura di misurazione. Ad esempio, l'errore nel misurare le prestazioni fisiche utilizzando una maschera per inalare l'aria espirata: la maschera rende difficile la respirazione, e l'atleta dimostra naturalmente una prestazione fisica sottovalutata rispetto a quella reale misurata senza maschera. L'entità di questo errore non può essere prevista in anticipo: dipende dalle capacità individuali dell'atleta e dal suo stato di salute al momento dello studio.
Un altro esempio di errore sistematico di questo gruppo è l'errore associato all'imperfezione dell'apparecchiatura, quando il dispositivo di misurazione sopravvaluta o sottovaluta deliberatamente il vero valore del valore misurato, ma l'entità dell'errore è sconosciuta.
Gli errori del terzo gruppo sono i più pericolosi, il loro aspetto è associato sia all'imperfezione del metodo di misurazione sia alle caratteristiche dell'oggetto di misurazione: l'atleta.
Errori casuali sorgono sotto l'influenza di vari fattori che non possono essere previsti in anticipo o presi in considerazione con precisione. Gli errori accidentali non possono essere eliminati in linea di principio. Tuttavia, utilizzando i metodi della statistica matematica, è possibile stimare l'entità dell'errore casuale e tenerne conto durante l'interpretazione dei risultati della misurazione. I risultati delle misurazioni non possono essere considerati affidabili senza un'elaborazione statistica.
Cos'è il test?
In conformità con IEEE Std 829-1983 testè un processo di analisi del software volto a identificare le differenze tra le sue proprietà effettivamente esistenti e quelle richieste (difetto) ea valutare le proprietà del software.
Secondo GOST R ISO IEC 12207-99, nel ciclo di vita del software, tra gli altri, vengono identificati processi ausiliari di verifica, certificazione, analisi congiunta e audit. Il processo di verifica è il processo per determinare che i prodotti software funzionano nel pieno rispetto dei requisiti o delle condizioni implementate nel lavoro precedente. Questo processo può includere analisi, verifica e test (test). Il processo di attestazione è il processo per determinare la completezza della conformità dei requisiti stabiliti, il sistema creato o il prodotto software con il loro scopo funzionale. Il processo di revisione collaborativa è il processo di valutazione degli stati e, se necessario, dei risultati del lavoro (prodotti) sul progetto. Il processo di audit è il processo per determinare la conformità ai requisiti, ai piani e ai termini del contratto. Questi processi si sommano a ciò che viene comunemente definito test.
I test si basano su procedure di test con input specifici, condizioni iniziali e risultati attesi progettati per uno scopo specifico, come testare un singolo programma o verificare la conformità a un requisito specifico. Le procedure di test possono testare vari aspetti delle prestazioni di un programma, dal corretto funzionamento di una singola funzione all'adeguato adempimento dei requisiti aziendali.
Quando si esegue un progetto, è necessario considerare in base a quali standard e requisiti verrà testato il prodotto. Quali strumenti saranno (se presenti) essere utilizzati per trovare e documentare i difetti riscontrati. Se ricordi di aver testato fin dall'inizio del progetto, testare il prodotto in fase di sviluppo non porterà spiacevoli sorprese. Ciò significa che è probabile che la qualità del prodotto sia piuttosto elevata.
Ciclo di vita del prodotto e test
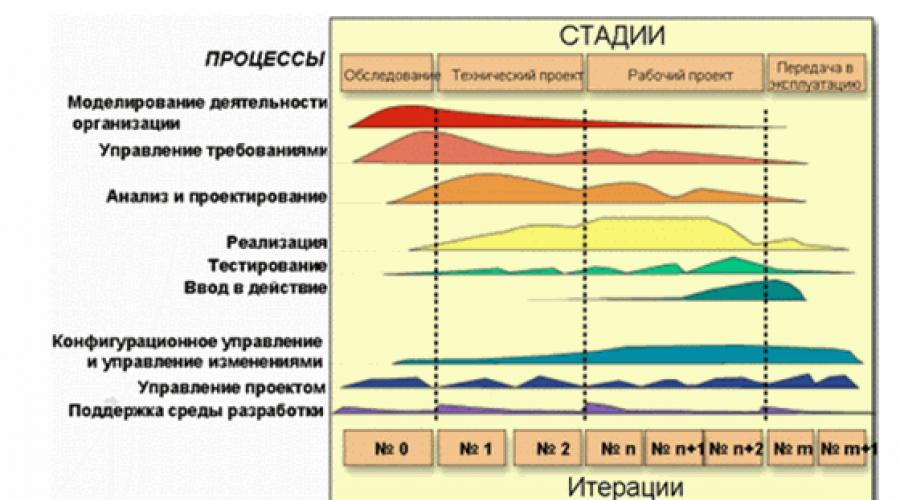
Sempre più, nel nostro tempo, vengono utilizzati processi di sviluppo software iterativi, in particolare la tecnologia RUP - Processo unificato razionale(Fig. 1). Quando si utilizza questo approccio, il test cessa di essere un processo predefinito che inizia dopo che i programmatori hanno scritto tutto il codice necessario. Il lavoro sui test inizia dalla fase iniziale di identificazione dei requisiti per un prodotto futuro ed è strettamente integrato con le attività attuali. E questo pone nuove esigenze ai tester. Il loro ruolo non si limita semplicemente a identificare gli errori nel modo più completo e tempestivo possibile. Dovrebbero essere coinvolti nel processo complessivo di identificazione ed eliminazione dei rischi più significativi del progetto. Per fare ciò, per ogni iterazione, vengono determinati un obiettivo del test e i metodi per raggiungerlo. E alla fine di ogni iterazione, viene determinato in che misura questo obiettivo è stato raggiunto, se sono necessari ulteriori test e se è necessario modificare i principi e gli strumenti per condurre i test. A sua volta, ogni difetto rilevato deve attraversare il proprio ciclo di vita.
Riso. 1. Ciclo di vita del prodotto secondo RUP
I test vengono solitamente eseguiti in cicli, ciascuno con un elenco specifico di attività e obiettivi. Il ciclo di test può coincidere con un'iterazione o corrispondere a una parte specifica di essa. In genere, il ciclo di test viene condotto per una build specifica del sistema.
Il ciclo di vita di un prodotto software consiste in una serie di iterazioni relativamente brevi (Fig. 2). L'iterazione è un ciclo di sviluppo completo che porta al rilascio di un prodotto finale o di una sua versione ridotta, che si espande di iterazione in iterazione fino a diventare un sistema completo.
Ogni iterazione include, di regola, compiti di pianificazione del lavoro, analisi, progettazione, implementazione, test e valutazione dei risultati raggiunti. Tuttavia, la relazione tra queste attività può variare in modo significativo. In accordo con il rapporto tra i vari compiti nell'iterazione, sono raggruppati in fasi. La prima fase - Inception - si concentra sui compiti di analisi. Le iterazioni della seconda fase - Sviluppo - si concentrano sulla progettazione e sul test di soluzioni progettuali chiave. La terza fase - Build - ha la maggior parte delle attività di sviluppo e test. E nell'ultima fase - Trasferimento - i compiti di test e trasferimento del sistema al Cliente sono risolti nella massima misura.

Riso. 2. Iterazioni del ciclo di vita del prodotto software
Ogni fase ha i propri obiettivi specifici nel ciclo di vita del prodotto ed è considerata completa quando questi obiettivi vengono raggiunti. Tutte le iterazioni, tranne, forse, le iterazioni della fase di Start, vengono completate con la creazione di una versione funzionante del sistema in sviluppo.
Categorie di test
I test differiscono in modo significativo nei compiti che vengono risolti con il loro aiuto e nella tecnica utilizzata.
| Categorie di test | Descrizione della categoria | Tipi di test |
|---|---|---|
| Test in corso | Una serie di test eseguiti per determinare l'integrità delle nuove funzionalità di sistema aggiunte. |
|
| Test di regressione | Lo scopo del test di regressione è verificare che le aggiunte al sistema non abbiano diminuito le sue capacità, ad es. i test vengono eseguiti in base ai requisiti già soddisfatti prima dell'aggiunta di nuove funzionalità. |
|
Sottocategorie di test
| Sottocategorie di test | Descrizione del tipo di test | Sottotipi di test |
|---|---|---|
| Test da sforzo | Viene utilizzato per testare tutte le funzioni dell'applicazione senza eccezioni. In questo caso, la sequenza delle funzioni di test non ha importanza. |
|
| Test del ciclo economico | Viene utilizzato per testare le funzioni dell'applicazione nella sequenza in cui vengono chiamate dall'utente. Ad esempio, imitazione di tutte le azioni di un contabile per 1 trimestre. |
|
| Test da sforzo |
Usato per i test Prestazioni dell'applicazione. Lo scopo di questo test è determinare la struttura per il funzionamento stabile dell'applicazione. Durante questo test, vengono chiamate tutte le funzioni disponibili. |
|
Tipi di test
Test dell'unità (test unitari): questo tipo prevede il test di singoli moduli applicativi. Per ottenere il massimo risultato, i test vengono eseguiti contemporaneamente allo sviluppo dei moduli.
Test funzionali - Lo scopo di questo test è garantire che l'elemento di prova funzioni correttamente. Viene verificata la correttezza della navigazione attraverso l'oggetto, così come l'input, l'elaborazione e l'output dei dati.
Test del database - verifica dell'operatività del database durante il normale funzionamento dell'applicazione, nei momenti di sovraccarico e in modalità multiutente.
Test dell'unità
Per l'OOP, la consueta organizzazione dei test unitari consiste nel testare i metodi di ciascuna classe, quindi la classe di ciascun pacchetto e così via. Gradualmente, si passa al test dell'intero progetto e i test precedenti sono test di regressione.
La documentazione di output di questi test include procedure di test, dati di input, codice che esegue il test e dati di output. Quella che segue è una vista della documentazione di output.
Test funzionali
Il test funzionale dell'oggetto in prova è pianificato ed eseguito sulla base dei requisiti di test specificati durante la fase di definizione dei requisiti. I requisiti sono regole aziendali, diagrammi dei casi d'uso, funzioni aziendali e, se disponibili, diagrammi di attività. Lo scopo dei test funzionali è verificare che i componenti grafici sviluppati soddisfino i requisiti specificati.
Questo tipo di test non può essere completamente automatizzato. Si suddivide quindi in:
- Test automatizzato (da utilizzare nel caso in cui l'output possa essere verificato).
Finalità: testare l'input, l'elaborazione e l'output dei dati;
- Test manuale (in altri casi).
Scopo: viene verificata la correttezza dell'adempimento dei requisiti dell'utente.
È necessario eseguire (riprodurre) ciascuno dei casi d'uso, utilizzando sia valori corretti che volutamente errati, per confermare il corretto funzionamento, secondo i seguenti criteri:
- il prodotto risponde adeguatamente a tutti i dati di input (i risultati attesi vengono visualizzati in risposta ai dati inseriti correttamente);
- il prodotto risponde adeguatamente ai dati inseriti in modo errato (appaiono messaggi di errore corrispondenti).
Test del database
Lo scopo di questo test è assicurarsi che i metodi di accesso al database siano affidabili, eseguiti correttamente, senza compromettere l'integrità dei dati.
È necessario utilizzare in modo coerente il maggior numero possibile di chiamate al database. Viene utilizzato un approccio in cui il test è composto in modo tale da "caricare" la base con una sequenza sia di valori corretti che di valori volutamente errati. Viene determinata la risposta del database all'input dei dati e vengono stimati gli intervalli di tempo per la loro elaborazione.
Viene chiamata una misurazione o un test effettuato per determinare la condizione o l'abilità di un atleta Impasto... Non tutte le misurazioni possono essere utilizzate come test, ma solo quelle che soddisfano requisiti speciali: standard, disponibilità di un sistema di valutazione, affidabilità, contenuto informativo, obiettività. Vengono chiamati i test che soddisfano i requisiti di affidabilità, contenuto informativo e obiettività solido.
Il processo di test si chiama test, e i valori numerici ottenuti come risultato della misurazione sono Risultato del test.
Vengono chiamati test basati su compiti motori il motore o il motore... Si distinguono tre gruppi di test motori a seconda del compito che il soggetto deve affrontare.
Varietà di test motori
|
Nome del test |
Assegnazione all'atleta |
Risultato del test | |
|
Esercizio di controllo |
Risultati motori |
1500 m di corsa, tempo di corsa |
|
|
Test funzionali standard |
Uguale per tutti, dosato: 1) in base alla mole di lavoro svolto; 2) dall'entità dei cambiamenti fisiologici |
Indicatori fisiologici o biochimici al lavoro standard Indicatori motori a una grandezza standard dei cambiamenti fisiologici |
Registrazione della frequenza cardiaca al lavoro standard 1000 kgm/min Velocità di corsa alla frequenza cardiaca 160 battiti/min |
|
Massime prove funzionali |
Mostra il massimo risultato |
Parametri fisiologici o biochimici |
Determinazione del debito massimo di ossigeno o del consumo massimo di ossigeno |
A volte non uno, ma diversi test vengono utilizzati con un unico obiettivo finale. Questo gruppo di test è chiamato batteria di test.
È noto che anche con la standardizzazione più rigorosa e l'attrezzatura precisa, i risultati dei test variano sempre leggermente. Pertanto, una delle condizioni importanti per la selezione di buoni test è la loro affidabilità.
Affidabilità del testè il grado di coincidenza dei risultati quando le stesse persone vengono testate di nuovo nelle stesse condizioni. Ci sono quattro ragioni principali per la variazione intra-individuale o intra-gruppo nei risultati del test:
cambiamenti nello stato dei soggetti (affaticamento, cambiamento nella motivazione, ecc.); cambiamenti incontrollati nelle condizioni esterne e nelle attrezzature;
cambiamento nello stato della persona che conduce o valuta il test (benessere, sostituzione dello sperimentatore, ecc.);
imperfezione del test (ad esempio, test deliberatamente imperfetti e inaffidabili - tiri liberi nel canestro prima del primo errore, ecc.).
Il criterio di affidabilità del test può essere fattore di affidabilità, calcolato come rapporto tra la varianza vera e la varianza registrata nell'esperimento: r = vero s 2 / registrato s 2, dove il valore vero è inteso come la varianza ottenuta con un numero infinito di osservazioni nelle stesse condizioni; la varianza registrata è derivata da studi sperimentali. In altre parole, il coefficiente di affidabilità è semplicemente la frazione della variazione reale nella variazione registrata nell'esperienza.
Oltre a questo coefficiente, usano anche indice di affidabilità, che è considerato come il coefficiente teorico di correlazione o relazione tra i valori registrati e quelli veri dello stesso test. Questo metodo è più comune come criterio per valutare la qualità (affidabilità) del test.
Una delle caratteristiche dell'affidabilità del test è la sua equivalenza, che riflette il grado di coincidenza dei risultati di test della stessa qualità (ad esempio fisici) da test diversi. L'attitudine a verificare l'equivalenza dipende dal compito specifico. Da un lato, se due o più test sono equivalenti, il loro uso combinato aumenta l'attendibilità delle stime; d'altra parte, sembra possibile applicare un solo test equivalente, che semplificherà il test.
Se tutti i test in qualsiasi batteria di test sono altamente equivalenti, vengono chiamati omogeneo(ad esempio, per valutare la qualità del salto, si deve presumere che il salto in lungo, in alto, triplo sarà omogeneo). Al contrario, se non ci sono test equivalenti nel complesso (come, ad esempio, per valutare l'idoneità fisica generale), allora tutti i test inclusi in esso misurano proprietà diverse, ad es. essenzialmente il complesso è eterogeneo.
L'affidabilità dei test può essere migliorata in una certa misura da:
standardizzazione dei test più rigorosa;
aumentare il numero di tentativi;
aumentare il numero dei valutatori e aumentare la coerenza delle loro opinioni;
aumentare il numero di prove equivalenti;
migliore motivazione dei soggetti.
Obiettività del test c'è un caso speciale di affidabilità, ad es. indipendenza dei risultati del test dalla persona che esegue il test.
Informatività del testÈ il grado di accuratezza con cui misura la proprietà (qualità dell'atleta) per cui viene utilizzato. In casi diversi, gli stessi test possono avere contenuti informativi diversi. La questione dell'informatività del test si scompone in due particolari quesiti:
Cosa cambia questo test? Come misura esattamente?
Ad esempio, è possibile giudicare la prontezza dei fondisti con un indicatore come l'IPC e, in caso affermativo, con quale grado di precisione? Questo test può essere utilizzato nel processo di monitoraggio?
Se il test viene utilizzato per determinare la condizione di un atleta al momento dell'esame, allora si parla di diagnostico informatività del test. Se, sulla base dei risultati del test, vogliono trarre una conclusione sulla possibile prestazione futura dell'atleta, parlano di predittivo informatività. Il test può essere informativo diagnostico, ma non prognostico, e viceversa.
Il grado di contenuto informativo può essere caratterizzato quantitativamente - sulla base di dati sperimentali (il cosiddetto empirico informatività) e qualitativamente - sulla base di un'analisi significativa della situazione ( logico informatività). Sebbene nel lavoro pratico, l'analisi logica o significativa dovrebbe sempre precedere quella matematica. L'indicatore dell'informatività del test è il coefficiente di correlazione calcolato per la dipendenza del criterio dal risultato del test, e viceversa (l'indicatore viene preso come criterio, riflettendo ovviamente la proprietà che si andrà a misurare utilizzando il test).
In caso di contenuto informativo insufficiente di qualsiasi test, ricorrono all'utilizzo di una batteria di test. Tuttavia, quest'ultimo, anche con criteri di separazione elevati per il contenuto informativo (a giudicare dai coefficienti di correlazione), non consente di ottenere un solo numero. Qui può venire in soccorso un metodo più complesso di statistica matematica - analisi fattoriale. Che ti permette di determinare quanti e quali test lavorano insieme su un particolare fattore e qual è il grado del loro contributo a ciascun fattore. E poi è già facile selezionare i test (o le loro combinazioni) che valutano più accuratamente i singoli fattori.
|
1 Che cosa si chiama un test? | |
|
2 Che cos'è il test? |
Quantificazione della qualità o della condizione di un atleta Misurazione o test per determinare la condizione o la condizione di un atleta Processo di test di abilità che quantifica la qualità o la condizione di un atleta Nessuna definizione richiesta |
|
3 Cosa si chiama risultato del test? |
Quantificazione della qualità o della condizione di un atleta Misurazione o test per determinare la condizione o la condizione di un atleta Processo di test di abilità che quantifica la qualità o la condizione di un atleta Nessuna definizione richiesta |
|
4 Che tipo di test fa correndo 100 metri? | |
|
5 Che tipo di test fa dinamometria manuale? |
Esercizio di controllo Test funzionale Test funzionale massimo |
|
6 A che tipo di test appartiene il campione? IPC? |
Esercizio di controllo Test funzionale Test funzionale massimo |
|
7 Che tipo di test fa corsa di tre minuti sotto il metronomo? |
Esercizio di controllo Test funzionale Test funzionale massimo |
|
8 Che tipo di test fa il numero massimo di pull-up sulla barra? |
Esercizio di controllo Test funzionale Test funzionale massimo |
|
9 In quale caso un test è considerato informativo? | |
|
10 Quando un test è considerato affidabile? |
La capacità del test di riprodurre i risultati quando viene riesaminato La capacità del test di misurare la qualità dell'atleta di interesse Indipendenza dei risultati del test dalla persona che esegue il test |
|
11 Quando il test è considerato oggettivo? |
La capacità del test di riprodurre i risultati quando viene riesaminato La capacità del test di misurare la qualità dell'atleta di interesse Indipendenza dei risultati del test dalla persona che esegue il test |
|
12 Quale criterio è necessario per valutare il test del contenuto informativo? | |
|
13 Quale criterio è necessario per valutare un test di affidabilità? |
Test t di Student F-Test di Fisher Coefficiente di correlazione Coefficiente di determinazione Varianza |
|
14 Quale criterio è necessario per valutare il test di obiettività? |
Test t di Student F-Test di Fisher Coefficiente di correlazione Coefficiente di determinazione Varianza |
|
15 Come si chiama l'informatività del test, se viene utilizzato per valutare il grado di allenamento di un atleta? | |
|
16 Da quale informatività degli esercizi di controllo è guidato l'allenatore quando seleziona i bambini per la sua sezione sportiva? |
Diagnostica logica predittiva empirica |
|
17 L'analisi di correlazione è necessaria per valutare l'informatività dei test? | |
|
18 L'analisi fattoriale è necessaria per valutare l'informatività dei test? | |
|
19 È possibile valutare l'affidabilità di un test utilizzando l'analisi di correlazione? | |
|
20 È possibile valutare l'oggettività del test utilizzando l'analisi di correlazione? | |
|
21 I test progettati per valutare la forma fisica generale saranno equivalenti? | |
|
22 Quando si misura la stessa qualità con test diversi, vengono utilizzati i test ... |
Progettati per misurare la stessa qualità Avere un'alta correlazione tra loro Avere una bassa correlazione tra loro |
FONDAMENTI DI TEORIA DELLA VALUTAZIONE
Per valutare le prestazioni atletiche, vengono spesso utilizzate tabelle di punteggio speciali. Lo scopo di tali tabelle è convertire il risultato sportivo mostrato (espresso in misure oggettive) in punti condizionali. La legge di convertire i risultati sportivi in punti si chiama scala di valutazione... La scala può essere specificata come espressione matematica, tabella o grafico. Esistono 4 tipi principali di scale utilizzate nello sport e nell'educazione fisica.
Scale proporzionali
Scale di regressione
Scale progressive.
Scale proporzionali implicano l'accumulo di un uguale numero di punti per un uguale aumento dei risultati (ad esempio, per ogni 0,1 s di miglioramento del risultato nella gara dei 100 m, vengono assegnati 20 punti). Tali scale sono utilizzate nel pentathlon moderno, nel pattinaggio di velocità, nello sci, nella combinata nordica, nel biathlon e in altri sport.
Scale di regressione implicano la maturazione, a parità di incremento del risultato all'aumentare dei risultati sportivi, di un numero di punti sempre minore (ad esempio, per un miglioramento del risultato in 100 m che passano da 15, 0 a 14,9 s, si sommano 20 punti, e per 0,1 s nell'intervallo 10,0-9,9 s - solo 15 punti).
Scale progressive. Qui, più alto è il risultato sportivo, più punti aumenta il suo miglioramento è stimato (ad esempio, vengono aggiunti 10 punti per un miglioramento del tempo di corsa da 15,0 a 14,9 s e 100 punti da 10,0 a 9,9 s). Le scale progressive sono utilizzate nel nuoto, in alcuni tipi di atletica leggera e nel sollevamento pesi.
Squame sigmoidee sono raramente utilizzati negli sport, ma sono ampiamente utilizzati nella valutazione della forma fisica (ad esempio, ecco come appare la scala degli standard di forma fisica della popolazione statunitense). Su queste scale, i miglioramenti delle prestazioni nelle zone a prestazioni molto basse e molto alte sono incoraggiate con parsimonia; il maggior numero di punti viene guadagnato dall'aumento dei risultati nella zona di realizzazione centrale.
Gli obiettivi principali della valutazione sono:
confrontare diversi risultati nello stesso compito;
confrontare i risultati in diversi compiti;
definire norme.
La norma nella metrologia sportiva, viene chiamato il valore limite del risultato, che funge da base per l'attribuzione di un atleta a uno dei gruppi di classificazione. Esistono tre tipi di norme: comparativa, individuale e dovuta.
Norme comparate si basano sul confronto di persone appartenenti alla stessa popolazione. Ad esempio, dividendo le persone in sottogruppi in base al grado di resistenza (alta, media, bassa) o reattività (iperreattiva, normoreattiva, iporeattiva) all'ipossia.
Diversi gradi di valutazione e norme
|
Percentuale di soggetti di prova |
Norme in scala |
||||||||
|
Verbale |
in punti |
percentile |
|||||||
|
Molto basso |
Sotto M - 2 | ||||||||
|
Da M - 2 a M - 1 | |||||||||
|
Sotto la media |
Da M-1 a M-0,5 | ||||||||
|
Da M – 0,5 a M + 0,5 | |||||||||
|
Sopra la media |
Da M + 0,5 a M + 1 | ||||||||
|
Da M + 1 a M + 2 | |||||||||
|
Molto alto |
Sopra M + 2 | ||||||||
Queste norme caratterizzano solo il successo comparativo dei soggetti in una data popolazione, ma non dicono nulla sulla popolazione nel suo insieme (o in media). Pertanto, i tassi di benchmarking dovrebbero essere confrontati con i dati di altre popolazioni e utilizzati insieme a tassi individuali e corretti.
Norme individuali sulla base di un confronto delle prestazioni dello stesso atleta in stati diversi. Ad esempio, in molti sport non esiste alcuna relazione tra il proprio peso corporeo e le prestazioni atletiche. Ogni atleta ha un peso individualmente ottimale corrispondente allo stato di forma sportiva. Questa velocità può essere controllata in diverse fasi dell'allenamento sportivo.
Norme dovute basato sull'analisi di ciò che una persona dovrebbe essere in grado di affrontare con successo i compiti che la vita gli pone davanti. Un esempio di ciò possono essere gli standard dei singoli complessi per l'allenamento fisico, i valori corretti di VC, metabolismo basale, peso corporeo e altezza, ecc.
|
1 È possibile misurare direttamente la qualità della resistenza? | |
|
2 È possibile misurare direttamente la qualità della velocità? | |
|
3 È possibile misurare direttamente la qualità della manualità? | |
|
4 È possibile misurare direttamente la qualità della flessibilità? | |
|
5 È possibile misurare direttamente la forza dei singoli muscoli? | |
|
6 La valutazione può essere espressa in una caratteristica qualitativa (buono, soddisfacente, cattivo, credito, ecc.)? | |
|
7 C'è differenza tra una scala di misurazione e una scala di valutazione? | |
|
8 Che cos'è una scala di valutazione? |
Sistema di misurazione dei risultati sportivi La legge di conversione dei risultati sportivi in punti Sistema di valutazione delle norme |
|
9 La bilancia presuppone la maturazione di un pari numero di punti a parità di incremento dei risultati. Esso … | |
|
10 Per lo stesso aumento del risultato, viene assegnato un numero inferiore di punti all'aumentare dei risultati sportivi. Esso … |
Scala progressiva Scala regressiva Scala proporzionale Scala sigmoide |
|
11 Più alto è il risultato sportivo, più punti aumentano si stima il suo miglioramento. Esso … |
Scala progressiva Scala regressiva Scala proporzionale Scala sigmoide |
|
12 Il miglioramento delle prestazioni nelle aree a prestazioni molto basse e molto elevate è incoraggiato con parsimonia; il maggior numero di punti viene guadagnato dall'aumento dei risultati nella zona di realizzazione centrale. Esso … |
Scala progressiva Scala regressiva Scala proporzionale Scala sigmoide |
|
13 Le norme basate sul confronto di persone appartenenti alla stessa popolazione sono chiamate ... | |
|
14 Le norme basate sul confronto delle prestazioni dello stesso atleta in stati diversi sono chiamate ... |
Standard individuali Standard dovuti Standard comparativi |
|
15 Le norme basate sull'analisi di ciò che una persona dovrebbe essere in grado di fare per far fronte ai compiti assegnatigli sono chiamate ... |
Standard individuali Standard dovuti Standard comparativi |
CONCETTI FONDAMENTALI DI QUALIMETRIA
Qualimetria(Latino qualitas - qualità, metron - misura) studia e sviluppa metodi quantitativi per la valutazione delle caratteristiche qualitative.
La qualimetria si basa su diversi presupposti:
Qualsiasi qualità può essere misurata;
La qualità dipende da una serie di proprietà che formano un "albero della qualità" (ad esempio, l'albero della qualità dell'esercizio nel pattinaggio artistico è costituito da tre livelli: superiore, medio, inferiore);
Ogni proprietà è definita da due numeri: indice relativo e peso; la somma dei pesi delle proprietà ad ogni livello è uguale a uno (o 100%).
Le tecniche metodologiche della qualimetria si dividono in due gruppi:
Euristico (intuitivo) basato su valutazioni di esperti e questionari;
Strumentale.
Esperto si chiama preventivo ottenuto chiedendo i pareri di specialisti. Esempi tipici di competenza: giudizio in ginnastica e pattinaggio artistico, competizione per il miglior lavoro scientifico, ecc.
L'esame comprende le seguenti fasi principali: la formazione del suo obiettivo, la selezione degli esperti, la scelta della metodologia, l'indagine e l'elaborazione delle informazioni ricevute, compresa la valutazione della coerenza delle valutazioni dei singoli esperti. Durante l'esame, il grado di coerenza delle opinioni degli esperti è di grande importanza, valutato dal valore coefficiente di correlazione di rango(in caso di più esperti). Va notato che la correlazione di rango è alla base della soluzione di molti problemi di qualimetria, poiché consente calcoli matematici con caratteristiche qualitative.
In pratica, un indicatore delle qualifiche di un esperto è spesso la deviazione delle sue valutazioni dalle valutazioni medie di un gruppo di esperti.
interrogare si chiama il metodo di raccolta delle opinioni attraverso la compilazione di questionari. Il questionario, insieme all'intervista e alla conversazione, fa riferimento ai metodi di indagine. A differenza delle interviste e delle conversazioni, l'indagine del questionario presuppone risposte scritte della persona che compila il questionario - l'intervistato - a un sistema di domande standardizzate. Ti permette di studiare i motivi del comportamento, le intenzioni, le opinioni, ecc.
Con l'ausilio di questionari è possibile risolvere molti problemi pratici nello sport: valutazione dello stato psicologico di un atleta; il suo atteggiamento nei confronti della natura e dell'orientamento delle sessioni di formazione; relazioni interpersonali nel team; propria valutazione della prontezza tecnica e tattica; valutazione della dieta e molti altri.
|
1 Cosa studia la qualimetria? |
Studio della qualità dei test Studio delle proprietà qualitative del tratto Studio e sviluppo di metodi quantitativi per valutare la qualità |
|
2 Metodi matematici utilizzati nella qualimetria? |
Correlazione a coppie Correlazione di rango Analisi della varianza |
|
3 Quali metodi vengono utilizzati per valutare il livello delle prestazioni? | |
|
4 Quali metodi vengono utilizzati per valutare la diversità degli elementi tecnici? |
Metodo del questionario Metodo delle valutazioni degli esperti Metodo non specificato |
|
5 Quali metodi vengono utilizzati per valutare la complessità degli elementi tecnici? |
Metodo del questionario Metodo delle valutazioni degli esperti Metodo non specificato |
|
6 Quali metodi vengono utilizzati per valutare lo stato psicologico di un atleta? |
Metodo del questionario Metodo delle valutazioni degli esperti Metodo non specificato |
La prima componente, la teoria dei test, contiene una descrizione dei modelli statistici per l'elaborazione dei dati diagnostici. Contiene modelli per l'analisi delle risposte negli elementi del test e modelli per il calcolo dei risultati totali del test. Mellenberg (1980, 1990) lo chiamò "psicometria". Teoria dei test classica, teoria dei test moderna (o modello di analisi delle risposte agli elementi del test - IRT) e modello
gli elementi campione costituiscono i tre tipi più importanti di modelli di teoria dei test. Il tema della psicodiagnostica sono i primi due modelli.
Teoria classica dei test. La maggior parte dei test di intelligenza e di personalità sono stati sviluppati sulla base di questa teoria. Il concetto centrale di questa teoria è il concetto di "affidabilità". L'affidabilità si riferisce alla coerenza dei risultati quando rivalutati. Nei libri di riferimento, questo concetto viene solitamente presentato molto brevemente, quindi viene fornita una descrizione dettagliata dell'apparato della statistica matematica. In questo capitolo introduttivo, presenteremo una sintetica descrizione del significato principale del concetto osservato. Nella teoria classica dei test, l'affidabilità è intesa come la ripetibilità dei risultati di più procedure di misurazione (principalmente misurazioni mediante test). L'affidabilità implica il calcolo dell'errore di misurazione. I risultati ottenuti durante il processo di test possono essere presentati come la somma del risultato vero e dell'errore di misurazione:
Xi = Ti+ j
dove Xiè la valutazione dei risultati ottenuti, Ti è il vero risultato, e j- errore di misurazione.
La valutazione dei risultati ottenuti è, di regola, il numero di risposte corrette ai compiti del test. Il vero risultato può essere visto come una stima vera in senso platonico (Gulliksen, 1950). Il concetto di risultati attesi è molto diffuso, es. idee sui punti che possono essere ottenuti come risultato di un gran numero di ripetizioni di procedure di misurazione (Lord & Novich, 1968). Ma non è possibile effettuare la stessa procedura di valutazione con una persona. Pertanto, è necessario cercare altre soluzioni al problema (Witlman, 1988).
All'interno di questo concetto, vengono fatte alcune ipotesi sui risultati reali e sugli errori di misurazione. Questi ultimi sono presi come un fattore indipendente, il che, ovviamente, è un'ipotesi ben fondata, poiché fluttuazioni casuali nei risultati non danno covarianze: r EE = 0.
Si presume che non vi sia alcuna correlazione tra punteggi reali ed errori di misurazione: r EE = 0.
L'errore totale è 0, perché la media aritmetica è assunta come stima vera:
Queste ipotesi alla fine ci portano alla ben nota definizione di affidabilità come il rapporto tra il risultato vero e la varianza totale o l'espressione: 1 meno il rapporto, nel cui numeratore è l'errore di misurazione, e nel denominatore - la varianza totale :
 , O
, O 
Da questa formula per determinare l'affidabilità si ottiene che la varianza dell'errore S 2 (E)è uguale alla varianza totale nel numero di casi (1 - r XX "); quindi, l'errore standard di misurazione è determinato dalla formula:
![]()
Dopo la prova teorica dell'affidabilità e dei suoi derivati, è necessario determinare l'indice di affidabilità di un particolare test. Esistono procedure pratiche per valutare l'affidabilità dei test, come l'utilizzo di moduli intercambiabili (test paralleli), la suddivisione degli elementi in due, la ripetizione del test e la misurazione della coerenza interna. Ogni riferimento contiene indici della costanza dei risultati dei test:
r XX '= r (x 1, x 2)
dove r XX ' è il coefficiente di stabilità, e x 1 e x 2 - i risultati di due misurazioni.
Il concetto di affidabilità delle forme intercambiabili è stato introdotto e sviluppato da Gulliksen (1950). Questa procedura è piuttosto laboriosa, poiché è associata alla necessità di creare una serie parallela di attività.
r XX '= r (x 1, x 2)
dove r XX ' è il coefficiente di equivalenza, e x 1 e x 2 - due prove parallele.
La procedura successiva - dividere il test principale in due parti A e B - è più facile da usare. Gli indicatori ottenuti per entrambe le parti del test sono correlati. Utilizzando la formula di Spearman-Brown, l'affidabilità del test nel suo insieme viene valutata:
dove A e B sono due parti parallele del test.
Il metodo successivo consiste nel determinare la coerenza interna degli elementi di prova. Questo metodo si basa sulla determinazione della covarianza dei singoli elementi. Sg è la varianza di un elemento selezionato casualmente e Sgh è la covarianza di due elementi selezionati casualmente. Il coefficiente più comunemente usato per determinare la consistenza interna è il coefficiente alfa di Cronbach. Viene utilizzata anche la formula KP20 e λ-2(lambda-2).
Nel concetto classico di affidabilità, vengono determinati gli errori di misurazione che si verificano sia durante il test che durante l'osservazione. Le fonti di questi errori sono diverse: possono essere tratti della personalità, le specifiche delle condizioni di test e le stesse attività di test. Esistono metodi specifici per il calcolo degli errori. Sappiamo che le nostre osservazioni possono essere sbagliate, i nostri strumenti metodologici sono imperfetti, così come le persone stesse sono imperfette. (Come non ricordare Shakespeare: "Sei inaffidabile, il cui nome è uomo"). Il fatto che nella teoria dei test classica gli errori di misurazione siano spiegati e spiegati è un importante punto positivo.
La teoria dei test classica ha una serie di caratteristiche significative che possono essere considerate le sue carenze. Alcune di queste caratteristiche sono annotate nei testi di riferimento, ma la loro importanza (dal punto di vista quotidiano) è raramente sottolineata, così come non si nota che, da un punto di vista teorico o metodologico, siano da considerarsi carenze.
Primo. La teoria classica dei test e il concetto di affidabilità sono focalizzati sul calcolo degli indicatori di test totali, che sono il risultato della somma delle stime ottenute in compiti separati. Quindi, quando si lavora
Secondo. Il fattore di affidabilità presuppone una stima dell'entità della diffusione degli indicatori misurati. Ne consegue che il coefficiente di attendibilità sarà inferiore se (a parità di altri indicatori) il campione è più omogeneo. Non esiste un unico coefficiente di consistenza interna degli elementi di prova, questo coefficiente è sempre "contestuale". Crocker e Aljina (1986), ad esempio, propongono una speciale formula di "correzione omogenea del campione" progettata per i punteggi più alti e più bassi ottenuti da coloro che si sottopongono al test. È importante che il diagnostico conosca le caratteristiche delle variazioni nel campione, altrimenti non potrà utilizzare i coefficienti di consistenza interna specificati nel manuale per questo test.
Terzo. Il fenomeno della riduzione alla media aritmetica è una logica conseguenza del concetto classico di attendibilità. Se il punteggio del test fluttua (cioè, non è abbastanza affidabile), è possibile che quando la procedura viene ripetuta, i soggetti con punteggi bassi riceveranno punteggi più alti e, viceversa, i soggetti con punteggi alti riceveranno punteggi bassi. Questo artefatto della procedura di misurazione non può essere scambiato per un vero cambiamento o manifestazione di processi di sviluppo. Ma allo stesso tempo, non è facile distinguerli, tk. la possibilità di cambiamento nel corso dello sviluppo non può mai essere esclusa. Per una completa fiducia, è necessario "confrontare con il gruppo di controllo.
La quarta caratteristica dei test progettati secondo i principi della teoria classica è la disponibilità di dati normativi. La conoscenza delle norme del test consente al ricercatore di interpretare adeguatamente i risultati del test. Al di fuori della norma, i punteggi dei test sono privi di significato. Lo sviluppo di norme di test è un'impresa piuttosto costosa, poiché uno psicologo deve ottenere risultati di test su un campione rappresentativo.
2 Ya ter Laak
Se parliamo delle carenze del concetto classico di affidabilità, allora è opportuno citare l'affermazione di Si-tsma (1992, pp. 123-125). Egli osserva che il primo e più importante presupposto della teoria dei test classici è che i risultati dei test obbediscono al principio dell'intervallo. Tuttavia, non ci sono studi a sostegno di questa ipotesi. In sostanza, questa è una "misura secondo una regola arbitrariamente stabilita". Questa caratteristica pone la teoria classica dei test in una posizione meno favorevole rispetto alle scale di misurazione degli atteggiamenti e, ovviamente, rispetto alla moderna teoria dei test. Molti metodi di analisi dei dati (analisi della varianza, analisi di regressione, analisi di correlazione e analisi fattoriale) si basano sul presupposto dell'esistenza di una scala a intervalli. Tuttavia, non ha solide basi. Si può solo assumere la scala dei risultati veri come una scala di valori delle caratteristiche psicologiche (ad esempio capacità aritmetiche, intelligenza, nevroticismo).
La seconda osservazione riguarda il fatto che i risultati del test non sono indicatori assoluti dell'una o dell'altra caratteristica psicologica della persona testata, dovrebbero essere considerati solo come i risultati dell'esecuzione di questo o quel test. Due test possono pretendere di studiare le stesse caratteristiche psicologiche (ad esempio, intelligenza, capacità verbale, estroversione), ma ciò non significa che i due test siano equivalenti e abbiano le stesse capacità. Il confronto delle prestazioni di due persone testate con test diversi non è corretto. Lo stesso vale per il completamento di due prove diverse da parte dello stesso soggetto. La terza osservazione si riferisce al presupposto che l'errore standard di misurazione è lo stesso per qualsiasi livello di capacità misurabile dell'individuo. Tuttavia, non esiste un test empirico per questa ipotesi. Quindi, per esempio, non c'è alcuna garanzia che un candidato con una buona capacità matematica otterrà punteggi alti quando lavora con un test aritmetico relativamente semplice. In questo caso, è più probabile che una persona con abilità basse o medie riceva una valutazione alta.
Nel quadro della moderna teoria dei test o della teoria dell'analisi delle risposte, gli elementi del test contengono una descrizione di un grande
il numero di modelli di possibili risposte degli intervistati. Questi modelli differiscono nelle ipotesi sottostanti, nonché nei requisiti in relazione ai dati ottenuti. Il modello Rush è spesso visto come sinonimo di teorie di analisi delle risposte alle domande del test (1RT). In realtà, questo è solo uno dei modelli. La formula presentata in esso per descrivere la curva caratteristica per l'impostazione di g è la seguente:

dove G- un compito di prova separato; esp- funzione esponenziale (dipendenza non lineare); δ ("Delta") - il livello di difficoltà del test.
Altri elementi di prova come h, ottenere anche le proprie curve caratteristiche. Soddisfazione della condizione δ h> δ g (g significa che h- un compito più difficile. Pertanto, per qualsiasi valore dell'indicatore Θ ("Theta" - proprietà latenti delle abilità dei partecipanti al test) probabilità di completamento con successo del compito h più piccoli. Questo modello è chiamato rigoroso perché è ovvio che con un basso grado di espressione del tratto, la probabilità di portare a termine il compito è prossima allo zero. Non c'è spazio per congetture o congetture in questo modello. Per gli incarichi con opzioni, non è necessario fare supposizioni sulla probabilità di successo. Inoltre, questo modello è rigoroso nel senso che tutti gli elementi di prova devono avere la stessa capacità discriminativa (l'elevata discriminazione si riflette nella pendenza della curva; qui è possibile costruire la scala di Guttmann, secondo la quale in ogni punto della curva caratteristica la probabilità di portare a termine un compito varia da 0 a 1). A causa di questa condizione, non tutte le assegnazioni possono essere incluse nei test basati sul modello Rush.
Esistono diverse varianti di questo modello (ad esempio Birnbaura, 1968, See Lord & Novik). Consente l'esistenza di compiti con diverse discriminanti
capacità.
Il ricercatore olandese Mokken (1971) ha sviluppato due modelli per analizzare le risposte negli item del test, i cui requisiti non sono così rigorosi come nel modello Rush e quindi, forse, sono più realistici. Come condizione principale
Viya Mokken propone la posizione che la curva caratteristica del compito dovrebbe seguire in modo monotono, senza interruzioni. Allo stesso tempo, tutte le attività di test sono finalizzate allo studio delle stesse caratteristiche psicologiche, che dovrebbero essere misurate v. Qualsiasi forma di questa dipendenza è consentita purché non si interrompa. Pertanto, la forma della curva caratteristica non è determinata da alcuna funzione specifica. Questa "libertà" ti consente di utilizzare più elementi nel test e il livello di valutazione non è superiore al solito.
La metodologia dei modelli di risposta agli elementi di prova (IRT) differisce dalla metodologia della maggior parte degli studi sperimentali e di correlazione. Il modello matematico è progettato per studiare le caratteristiche comportamentali, cognitive, emotive, nonché i fenomeni di sviluppo. Questi fenomeni in esame sono spesso limitati alle risposte ai compiti, il che ha portato Mellenberg (1990) a riferirsi all'IRT come a una "mini-teoria del mini-comportamento". I risultati dello studio possono in una certa misura essere presentati come curve di concordanza, specialmente nei casi in cui non esiste una comprensione teorica delle caratteristiche studiate. Fino ad ora, abbiamo a nostra disposizione solo alcuni test di intelligenza, abilità e personalità, creati sulla base di numerosi modelli della teoria IRT. Varianti del modello di Rush sono più comunemente usate nella progettazione dei test di rendimento (Verhelst, 1993), mentre i modelli di Mocken sono più adatti ai fenomeni di sviluppo (vedi anche Capitolo 6).
La risposta del candidato agli elementi del test è l'unità di base dei modelli IRT. Il tipo di risposta è determinato dalla gravità della caratteristica studiata in una persona. Tale caratteristica può essere, ad esempio, l'abilità aritmetica o spaziale. Nella maggior parte dei casi, questo è l'uno o l'altro aspetto dell'intelligenza, delle caratteristiche di realizzazione o dei tratti della personalità. Si presume che vi sia una relazione non lineare tra la posizione di questa particolare persona in un certo intervallo della caratteristica studiata e la probabilità di completamento con successo di un particolare compito. La non linearità di questa relazione è, in un certo senso, intuitiva. Frasi famose "Ogni inizio è difficile" (lento
inizio lineare) e “Farsi santi non è così facile” significano che un ulteriore miglioramento dopo aver raggiunto un certo livello è difficile. La curva si avvicina lentamente, ma non raggiunge quasi mai una percentuale di successo del 100%.
Alcuni modelli hanno maggiori probabilità di contraddire la nostra comprensione intuitiva. Prendiamo questo esempio. Una persona con un indice di gravità di una caratteristica arbitraria pari a 1,5 ha una probabilità del 60% di successo nell'attività. Ciò contraddice la nostra comprensione intuitiva di questa situazione, perché puoi far fronte con successo al compito o non affrontarlo affatto. Prendiamo questo esempio: 100 volte una persona cerca di prendere un'altezza di 1 m 50 cm Il successo lo accompagna 60 volte, ad es. ha una percentuale di successo del 60%.
Per valutare la gravità della caratteristica, sono necessarie almeno due attività. Il modello Rush assume la determinazione della gravità delle caratteristiche, indipendentemente dalla difficoltà del compito. Ciò contraddice anche la nostra comprensione intuitiva: supponiamo che una persona abbia una probabilità dell'80% di saltare sopra 1,30 m. In tal caso, secondo la curva caratteristica dei compiti, ha una probabilità del 60% di saltare sopra 1,50 m e un 40% di probabilità di saltare più in alto di 1,70 M. Pertanto, indipendentemente dal valore della variabile indipendente (altezza), è possibile valutare la capacità di una persona di saltare in altezza.
Esistono circa 50 modelli IRT (Goldstein & Wood, 1989) Ci sono molte funzioni non lineari che descrivono (spiegano) la probabilità di successo in un compito o in un gruppo di compiti. I requisiti e le limitazioni di questi modelli sono diversi e queste differenze possono essere trovate confrontando il modello Rush e la scala Mocken. I requisiti di questi modelli includono:
1) la necessità di determinare le caratteristiche studiate e valutare la posizione di una persona nell'ambito di questo tratto;
2) valutazione della sequenza dei compiti;
3) verifica di modelli specifici. In psicometria, sono state sviluppate molte procedure per testare un modello.
In alcuni libri di riferimento, la teoria dell'IRT è considerata una forma di analisi degli elementi di prova (vedi, ad esempio,
Croker & Algina, J 986). È possibile, tuttavia, sostenere che la teoria dell'IRT sia una "mini-teoria del mini-comportamento". I sostenitori della teoria dell'IRT notano che se i concetti di livello medio (modelli) sono imperfetti, allora che dire dei costrutti più complessi in psicologia?
Teoria dei test classica e moderna. Le persone non possono fare a meno di confrontare cose che sembrano quasi uguali. (Forse l'equivalente quotidiano della psicometria consiste principalmente nel confrontare le persone secondo caratteristiche significative e scegliere tra di esse). Ognuna delle teorie presentate - sia la teoria della misurazione degli errori di stima che il modello matematico delle risposte agli item del test - ha i suoi sostenitori (Goldstein & Wood, 1986).
Ai modelli IRT non viene rimproverato di essere "basati su regole", in contrasto con la teoria dei test classica. Il modello IRT è focalizzato sull'analisi delle caratteristiche valutate. Le caratteristiche della personalità e le caratteristiche del compito sono valutate utilizzando le scale (ordinale o intervallo). Inoltre, è possibile confrontare gli indicatori di performance di diversi test volti a studiare caratteristiche simili. Infine, l'affidabilità non è la stessa per ogni valore sulla scala e le medie sono generalmente più affidabili di quelle all'inizio e alla fine della scala. Pertanto, i modelli IRT sembrano essere più avanzati in teoria. Ci sono anche differenze nell'uso pratico della moderna teoria dei test e della teoria classica (Sijstma, 1992, pp. 127-130). La moderna teoria dei test è più complessa della teoria dei test classica, quindi è meno comunemente usata dai non specialisti. Inoltre, l'IRT ha requisiti speciali per gli incarichi. Ciò significa che gli elementi dovrebbero essere esclusi dal test se non soddisfano i requisiti del modello. Questa regola si applica ulteriormente a quei compiti che facevano parte dei test ampiamente utilizzati, costruiti secondo i principi della teoria classica. Il test diventa più breve e quindi meno affidabile.
IRT offre modelli matematici per lo studio dei fenomeni del mondo reale. I modelli dovrebbero aiutarci a comprendere gli aspetti chiave di questi fenomeni. Tuttavia, qui c'è una domanda teorica di base. I modelli possono essere considerati
come approccio allo studio della complessa realtà in cui viviamo. Ma modello e realtà non sono la stessa cosa. Secondo la visione pessimistica, è possibile modellare solo comportamenti isolati (e, per di più, non i più interessanti). Puoi anche trovare l'affermazione che la realtà non è affatto soggetta a modelli, perché obbedisce non solo alle leggi di causa ed effetto. Nella migliore delle ipotesi, è possibile modellare fenomeni comportamentali individuali (ideali). C'è un'altra visione più ottimistica delle possibilità della modellazione. La posizione di cui sopra blocca la possibilità di una profonda comprensione della natura dei fenomeni del comportamento umano. L'applicazione di questo o quel modello solleva alcune questioni generali e fondamentali. A nostro avviso, non c'è dubbio che l'IRT sia un concetto teoricamente e tecnicamente superiore alla teoria classica dei test.
Lo scopo pratico dei test, qualunque sia la base teorica che vengono creati, è definire criteri significativi e stabilire, sulla base di essi, le caratteristiche di determinati costrutti psicologici. Il modello IRT presenta vantaggi anche in questo senso? È possibile che i test basati su questo modello non forniscano una previsione più accurata rispetto ai test basati sulla teoria classica ed è possibile che il loro contributo allo sviluppo di costrutti psicologici non sia più significativo. I diagnostici preferiscono i criteri che sono direttamente rilevanti per un individuo, un'istituzione o una comunità. Un modello più scientificamente avanzato “ipso facto” * non definisce un criterio più appropriato ed è alquanto limitato nello spiegare i costrutti scientifici. È ovvio che continuerà lo sviluppo di test basati sulla teoria classica, ma allo stesso tempo verranno creati nuovi modelli IRT, estendendosi allo studio di un numero maggiore di fenomeni psicologici.
Nella teoria classica dei test si distinguono i concetti di "affidabilità" e "validità". I risultati dei test dovrebbero essere affidabili, ad es. i risultati dell'iniziale e del nuovo test dovrebbero essere coerenti. Oltretutto,
* ipso facto(vernice) - da solo (circa trad.).
i risultati dovrebbero essere esenti (per quanto possibile) da errori di stima. La presenza di validità è uno dei requisiti per i risultati ottenuti. In questo caso, l'affidabilità è considerata una condizione necessaria, ma non ancora sufficiente per la validità del test.
La validità presuppone che i risultati ottenuti siano relativi a qualcosa di importanza pratica o teorica. Le conclusioni tratte dai punteggi dei test devono essere valide. Molto spesso parlano di due tipi di validità: predittiva (criterio) e costruttiva. Esistono anche altri tipi di validità (vedi capitolo 3). Inoltre, la validità può essere determinata nel caso di quasi-esperimenti (Cook & Campbell, 1976, Cook & Shadish, 1994). Tuttavia, il principale tipo di validità è ancora la validità predittiva, intesa come la capacità di prevedere qualcosa di significativo sul comportamento in futuro dal risultato del test, nonché la possibilità di una comprensione più profonda di una particolare proprietà o qualità psicologica.
I tipi di validità presentati sono discussi in ciascuna guida e sono accompagnati da una descrizione dei metodi per analizzare la validità del test. L'analisi fattoriale è più adatta per determinare la convalida del costrutto e le equazioni di regressione lineare vengono utilizzate per analizzare la validità predittiva. Queste o quelle caratteristiche (rendimento scolastico, efficacia della terapia) possono essere previste sulla base di uno o più indicatori, ottenuti lavorando con test intellettuali o di personalità. Le tecniche di elaborazione dei dati come la correlazione, la regressione, l'analisi della varianza, l'analisi delle correlazioni parziali e delle varianze vengono utilizzate per determinare la validità predittiva di un test.
Spesso viene descritta anche la validità del contenuto. Si presume che tutti i compiti e i compiti del test dovrebbero appartenere a un'area specifica (proprietà mentali, comportamento, ecc.). Il concetto di validità significativa caratterizza la corrispondenza di ogni compito di prova all'area misurata. La validità del contenuto è talvolta vista come parte della robustezza o della "generalizzabilità" (Cronbach, Gleser, Nanda & Rajaratnam, 1972). Tuttavia, con
Quando si scelgono gli elementi per i test di rendimento in una specifica area disciplinare, è anche importante prestare attenzione alle regole per l'inclusione degli elementi nel test.
Nella teoria dei test classica, affidabilità e validità sono considerate in modo relativamente indipendente l'una dall'altra. Ma c'è anche un'altra comprensione della relazione tra questi concetti. La moderna teoria dei test si basa sull'applicazione di modelli. I parametri vengono valutati all'interno di un determinato modello. Se l'attività non soddisfa i requisiti del modello, nell'ambito di questo modello viene riconosciuta come non valida. La convalida del costrutto fa parte della convalida del modello stesso. Tale validazione si riferisce principalmente alla verifica dell'esistenza di un tratto latente unidimensionale oggetto di indagine con caratteristiche di scala note. I punteggi di scala possono senza dubbio essere utilizzati per determinare i criteri appropriati e la loro correlazione con gli indicatori di altri costrutti è possibile raccogliere informazioni sulla validità convergente e divergente del costrutto.
La psicodiagnostica è analoga al linguaggio, descritto come l'unità di quattro componenti, rappresentate a tre livelli. La prima componente, la teoria dei test, è analoga alla sintassi, la grammatica della lingua. La grammatica generativa (generativa) è, da un lato, un modello ingegnoso, dall'altro, un sistema che obbedisce alle regole. Con l'aiuto di queste regole, quelle complesse sono costruite sulla base di semplici frasi affermative. Allo stesso tempo, però, questo modello tralascia la descrizione di come è organizzato il processo di comunicazione (cosa si trasmette e cosa si percepisce), e per quali finalità viene realizzato. Per capirlo, sono necessarie ulteriori conoscenze. Lo stesso si può dire della teoria dei test: è necessaria in psicodiagnostica, ma non è in grado di spiegare cosa fa lo psicodiagnostico e quali sono i suoi obiettivi.
1.3.2. Teorie psicologiche e costrutti psicologici
La psicodiagnostica è sempre una diagnosi di qualcosa di specifico: caratteristiche personali, comportamento, pensiero, emozioni. I test sono progettati per misurare le differenze individuali. Ci sono diversi concetti
differenze individuali, ognuna delle quali ha le sue caratteristiche distintive. Se si riconosce che la psicodiagnostica non si limita solo alla valutazione delle differenze individuali, allora anche altre teorie acquistano un significato essenziale per la psicodiagnostica. Un esempio è la valutazione delle differenze nei processi di sviluppo mentale e delle differenze nell'ambiente sociale. Sebbene la valutazione delle differenze individuali non sia un attributo indispensabile della psicodiagnostica, esistono tuttavia alcune tradizioni di ricerca in quest'area. La psicodiagnostica è iniziata con una valutazione delle differenze di intelligenza. Il compito principale dei test era "determinare la trasmissione ereditaria del genio" (Gallon) o la selezione dei bambini per l'addestramento (Binet, Simon). La misurazione del quoziente di intelligenza ha ricevuto comprensione teorica e sviluppo pratico nelle opere di Spearman (Gran Bretagna) e Thurstone (USA). Raymond B. Kettel ha fatto una cosa simile per valutare i tratti della personalità. La psicodiagnostica diventa indissolubilmente legata a teorie e idee sulle differenze individuali nei risultati (valutazione delle possibilità estreme) e nelle forme di comportamento (livello di funzionamento tipico). Questa tradizione continua ad essere efficace oggi. Nei libri di testo di psicodiagnostica, le differenze nell'ambiente sociale sono valutate molto meno spesso rispetto alla considerazione delle caratteristiche degli stessi processi di sviluppo. Non c'è una spiegazione ragionevole per questo. Da un lato, la diagnostica non si limita a teorie e concetti specifici. D'altra parte, ha bisogno di teorie, poiché è in esse che viene determinato il contenuto diagnosticato (cioè "cosa" viene diagnosticato). Quindi, ad esempio, l'intelligenza può essere considerata sia come una caratteristica generale, sia come base per molte abilità indipendenti. Se la psicodiagnostica cerca di "allontanarsi" da una teoria o da un'altra, allora le idee di buon senso diventano la base del processo psicodiagnostico. Nella ricerca vengono utilizzati vari metodi di analisi dei dati e la logica generale della ricerca determina la scelta di un particolare modello matematico e determina la struttura dei concetti psicologici utilizzati. Tali metodi di statistica matematica
ki, in quanto analisi della varianza, analisi di regressione, analisi fattoriale, calcolo delle correlazioni presuppongono l'esistenza di dipendenze lineari. In caso di applicazione errata di questi metodi, "portano" la loro struttura nei dati ricevuti e nei costrutti utilizzati.
Le idee sulle differenze nell'ambiente sociale e sullo sviluppo della personalità non avevano quasi alcun effetto sulla psicodiagnostica. I libri di testo (vedi, ad esempio, Murphy e Davidshofer, 1988) considerano la teoria classica dei test e discutono i metodi appropriati di elaborazione statistica, descrivono test ben noti, considerano l'uso della psicodiagnostica nella pratica: nella psicologia manageriale, nella selezione del personale, nella valutazione delle caratteristiche psicologiche di una persona...
Le teorie delle differenze individuali (così come le idee sulle differenze tra ambiente sociale e sviluppo mentale) sono simili allo studio della semantica del linguaggio. Questo è lo studio dell'essenza, del contenuto e del significato. I significati sono strutturati in un certo modo (come i costrutti psicologici), ad esempio, per somiglianza o contrasto (analogia, convergenza, divergenza).
1.3.3. Test psicologici e altri strumenti metodologici
Il terzo componente dello schema proposto sono test, procedure e strumenti metodologici, con l'aiuto dei quali vengono raccolte informazioni sulle caratteristiche della personalità. Draene e Siitsma (1990, p. 31) danno la seguente definizione di test: “Un test psicologico è considerato come una classificazione secondo un certo sistema o come una procedura di misurazione che consente di esprimere un certo giudizio su uno o più empiricamente caratteristiche selezionate o teoricamente comprovate di un particolare aspetto del comportamento umano (per il quadro della situazione di prova). Allo stesso tempo, viene considerata la risposta degli intervistati a un certo numero di stimoli accuratamente selezionati e le risposte ricevute vengono confrontate con le norme del test ”.
La diagnostica richiede test e tecniche per raccogliere informazioni affidabili, accurate e valide sulle funzionalità
e tratti della personalità, pensiero, emozioni e comportamento di una persona. Oltre allo sviluppo delle procedure di test, questo componente include anche le seguenti domande: come vengono creati i test, come vengono formulati e selezionati i compiti, come procede il processo di test, quali sono i requisiti per le condizioni di test, come vengono presi in considerazione gli errori di misurazione, come i risultati del test vengono calcolati e interpretati.
Nel processo di sviluppo dei test, si distinguono strategie razionali ed empiriche. L'applicazione di una strategia razionale inizia con la definizione dei concetti di base (ad esempio i concetti di intelligenza, estroversione) e, in accordo con queste idee, vengono formulati i compiti di prova. Un esempio di tale strategia è il concetto di Guttman della teoria delle sfaccettature (1957, 1968, 1978). Innanzitutto, vengono determinati vari aspetti dei costrutti di base, quindi vengono selezionati compiti e attività in modo tale che ciascuno di questi aspetti venga preso in considerazione. La seconda strategia consiste nel selezionare i compiti su base empirica. Ad esempio, se un ricercatore cerca di creare un test di interessi professionali che differenzi i medici dagli ingegneri, la procedura dovrebbe essere questa. Entrambi i gruppi di intervistati devono rispondere a tutti gli elementi del test e gli elementi nelle risposte per i quali si riscontrano differenze statisticamente significative sono inclusi nella versione finale del test. Se, ad esempio, ci sono differenze tra i gruppi nelle risposte a un'affermazione “Amo pescare”, allora quell'affermazione diventa un elemento del test. Il punto principale di questo libro è che il test è legato alla teoria concettuale o tassonomica che definisce queste caratteristiche.
Lo scopo del test è solitamente specificato nelle istruzioni per l'uso. Il test deve essere standardizzato in modo che possa misurare le differenze tra le persone e non tra le condizioni di test. Ci sono, tuttavia, deviazioni dalla standardizzazione nelle procedure chiamate test dei limiti e test del potenziale di apprendimento. In queste condizioni, il convenuto è assistito nel processo
testare e quindi valutare l'effetto di tale procedura sul risultato. Il punteggio per le risposte alle attività è obiettivo, ad es. effettuata secondo la procedura standard. Anche l'interpretazione dei risultati ottenuti è rigorosamente definita ed effettuata sulla base di norme di prova.
La terza componente della psicodiagnostica - test psicologici, strumenti, procedure - contiene alcuni compiti, che sono le unità più piccole della psicodiagnostica e, in questo senso, i compiti sono simili ai fonemi del linguaggio. Il numero di possibili combinazioni di fonemi è limitato. Solo alcune strutture fonemiche possono formare parole e frasi che forniscono informazioni all'ascoltatore. Anche e compiti di test: solo in una certa combinazione tra loro possono diventare un mezzo efficace per valutare il costrutto corrispondente.