Studio aggregato e selettivo generale. Fiducia statistica
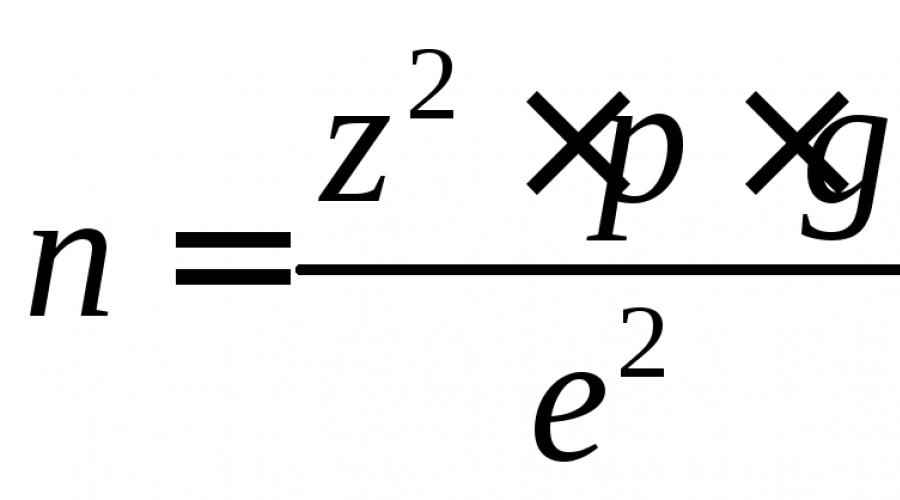
Leggi anche
La procedura per la stesura di un piano di esempio include Soluzione sequenziale dei tre compiti seguenti:
Determinazione dell'oggetto dello studio;
Determinazione della struttura di campionamento;
Determinazione del campionamento.
Generalmente, ricerca di marketing dell'oggetto. È una combinazione di oggetti di osservazione, che consumatori, dipendenti aziendali, intermediari, ecc. Possono essere giocati. Se questa totalità è così piccola che il team di ricerca ha il lavoro necessario, le capacità finanziarie e temporanee per stabilire un contatto con ciascuno dei suoi elementi, è abbastanza realistico svolgere uno studio continuo dell'intera popolazione. In questo caso, definendo l'oggetto dello studio, è possibile procedere alla seguente procedura (la scelta del metodo di raccolta dei dati, lo strumento di ricerca e il metodo di comunicazione con il pubblico).
Tuttavia, in pratica non è molto spesso possibile o appropriato svolgere uno studio continuo dell'intera popolazione. Per fare ciò, potrebbero esserci i seguenti motivi:
L'incapacità di stabilire un contatto con alcuni elementi della totalità;
Costi irragionevolmente grandi per condurre uno studio solido o la disponibilità di restrizioni finanziarie che non consentono una solida ricerca;
Scadenze suggerite stanziate per la ricerca a causa di una perdita con la pertinenza delle informazioni o di altri motivi e che non consentono la raccolta, la sistematizzazione e l'analisi di dati ampi per l'intera totalità.
Pertanto, gli aggregati grandi e dispersi sono spesso studiati dal campionamento, in base ai quali, come è noto, una parte dell'aggregato è intesa per personificare la totalità nel suo complesso.
La precisione con cui il campione riflette la totalità nel suo complesso dipende da strutture e dimensioni del campionamento.
Distinguere due approcci alla struttura del campionamento - probabilistico e deterministico.
Approccio probabilistico alla struttura di campionamento Si presume che qualsiasi elemento dell'aggregato possa essere selezionato con una probabilità (non zero). Esistono vari tipi di campioni in base alla teoria delle probabilità (tipico, nidificazione, ecc.). La pratica più semplice e comune è un semplice campione casuale, in cui ogni elemento dell'aggregato ha una scelta pari per lo studio.
Un campione probabilistico è più accurato, consente al ricercatore di stimare il grado di affidabilità dei dati raccolti da lui, anche se è più difficile e più costoso del deterministico.
Approccio deterministico alla struttura del campione Suppone che la scelta degli elementi del set sia effettuata con metodi basati su considerazioni di convenienza o sulla soluzione del ricercatore o su gruppi contingenti.
per considerazioni convenienzaConsiste nella scelta di eventuali elementi dell'aggregato in base alla semplicità di contattare il contatto con loro. L'imperfezione di questo metodo è dovuta alla bassa rappresentatività del campione ottenuto, perché Elementi confortevoli di aggregazione per il ricercatore non possono essere rappresentanti sufficientemente caratteristici dell'aggregato dovuto alla selezione non casuale e irragionevole.
Tuttavia, d'altra parte, la semplicità, l'efficienza e l'efficienza dello studio condotta da questo metodo ha acquisito abbastanza diffuso nella pratica e, soprattutto, quando conducono studi preliminari volti a chiarire i principali problemi.
Metodo di formazione del campionamento basato sulla decisione del ricercatoreConsiste nella scelta degli elementi dell'aggregato, che, a suo parere, sono i suoi caratteristici rappresentanti. Questo metodo è più perfetto del precedente, poiché si basa sull'orientamento sui caratteristici rappresentanti del talento in studio, sebbene selezionato sulla base delle rappresentazioni soggettive dei ricercatori a riguardo.
Il metodo di campionamento basato su standard contingentiConsiste nella scelta degli elementi caratteristici dell'aggregato in conformità con le caratteristiche dell'aggregato ottenuto in precedenza. Queste caratteristiche possono essere ottenute conducendo studi preliminari e, in contrasto con il metodo precedente, non sopportare una natura soggettiva. Pertanto, questo metodo è più perfetto, consente di ottenere set selettivi di non meno rappresentativo dei campioni probabilistici con costi significativamente meno sorveglianza.
Scegliere la struttura del campione (approccio alla sua formazione, il tipo di formazione probabilistica o rotolante del campione deterministico), il ricercatore dovrà determinare il volume, I.e. Il numero di elementi dell'aggregato selettivo.
Volume di campionamento Determina l'accuratezza delle informazioniottenuto a seguito della sua ricerca, nonché dei costi necessari per condurre ricerche. La dimensione del campione dipende Dal livello di omogeneità o varietà di oggetti studiati.
Maggiore è la dimensione del campione, maggiore è la sua accuratezza e più costi per il suo sondaggio. Con un approccio probabilistico alla struttura del campionamento, il suo volume può essere determinato utilizzando formule statistiche ben note, in base ai requisiti specificati per la sua precisione.
In pratica, diversi approcci sono utilizzati per definire il campionamento:
1. Approccio arbitrario Basato sull'uso delle "regole del pollice". Ad esempio, non è necessario che il campione debba essere il 5% della totalità per ottenere risultati accurati. Questo approccio è semplice e facile da eseguire, ma non è possibile stabilire l'accuratezza dei risultati ottenuti. Con una totalità sufficientemente grande, può anche essere molto costoso.
La dimensione del campione può essere stabilita sulla base di alcune condizioni predeterminate. Ad esempio, il cliente della ricerca di marketing sa che durante lo studio dell'opinione pubblica, il campione è solitamente 1000-1200 persone, quindi raccomanda al ricercatore di aderire a questa figura. Nel caso in cui gli studi annuali si tengono su un mercato, quindi in ogni anno utilizza il campione dello stesso volume. A differenza del primo approccio, una logica ben nota viene utilizzata qui nel determinare il volume del campione, che, tuttavia, è molto vulnerabile.
Ad esempio, quando si conducono determinati studi, la precisione può essere richiesta meno rispetto a quando si studia l'opinione pubblica e il totale di una totalità può essere molte volte meno rispetto a quando si studia l'opinione pubblica. Pertanto, questo approccio non tiene conto delle circostanze attuali e potrebbe essere piuttosto costoso.
In alcuni casi, come argomento principale, quando si determina il volume del campione, viene utilizzato il costo del sondaggio. Pertanto, il bilancio della ricerca di marketing prevede determinati sondaggi che non possono essere superati. Ovviamente, il valore delle informazioni ricevute non viene preso in considerazione. Tuttavia, in alcuni casi, un piccolo campione può dare risultati abbastanza accurati.
Sembra ragionevole tenere conto dei costi non in modo assoluto, ma in relazione all'utilità delle informazioni ottenute a causa dei sondaggi condotti. Il cliente e il ricercatore dovrebbero prendere in considerazione vari volumi di campioni e metodi di raccolta dei dati, i costi, tenere conto di altri fattori
2. La dimensione del campione sul livello di intervallo riservato di un errore valido, Ciò che, come già accennato, è dato dall'elegante precisione delle generalizzazioni definitive: da aumentato a approssimativo. Tuttavia, ci sono in mente i cosiddetti errori casuali associati alla natura di eventuali errori statistici. Sono calcolati come errori della rappresentatività dei campioni probabilistici.
V.I. Paniotto cita i seguenti calcoli del campione rappresentativo con le autorizzazioni dell'errore del 5% (tabella 4.2).
Tabella 4.2.
Tabella dei campioni calcolata
Per una combinazione di oltre 100.000 campioni è 400 unità. Se tengo presente il gruppo generale del numero da 5 mila e altro, quindi, secondo i calcoli dello stesso autore, è possibile specificare i valori dell'errore effettivo del campione, a seconda del suo volume, che è molto IMPORTANTE Per noi, ricordando che il valore dell'errore valido dipende dalla ricerca di scopo e dallo opzionale dovrebbe avvicinarsi al livello del 5%.
Tabella 4.3.
Tabella calcolata
|
Campionamento, se il generale aggregato 5000 | ||||||||
|
Errore effettivo in questo volume del campione,% |
Insieme a errori casuali e sistematici sono possibili. Dipendono dall'organizzazione di un esame selettivo. Queste sono una varietà di offset di campionamento verso uno dei poli del parametro selettivo.
3. Campionamento basato sull'analisi statistica . Questo approccio si basa sulla determinazione del campionamento minimo in base a determinati requisiti per l'affidabilità e l'affidabilità dei risultati ottenuti. Viene anche utilizzato nell'analisi dei risultati ottenuti per i singoli sottogruppi formati come parte della selezione sul pavimento, dell'età, del livello dell'istruzione, ecc. I requisiti per l'affidabilità e l'accuratezza dei risultati per i singoli sottogruppi dettano determinati requisiti per le dimensioni del campione nel suo complesso.
L'approccio più teoricamente motivato e corretto per determinare il volume del campione si basa sul calcolo degli intervalli affidabili. Il concetto di variazione caratterizza la grandezza delle risposte errate (simili) di intervistati a una determinata domanda. In un piano più rigoroso, la variazione dei valori di qualsiasi segno in un set è chiamato la differenza nei suoi valori da diverse unità di questo set nello stesso periodo o orario. Le risposte per le domande del sondaggio sono solitamente rappresentate sotto forma di una curva di distribuzione (Fig. 4.1). Con un'elevata somiglianza, le risposte stanno parlando di bassa variazione (curva di distribuzione stretta) e con somiglianze somiglianze somiglianze - circa un'elevata variazione (ampia curva di distribuzione).
Come misura della variazione, viene solitamente presa una deviazione quadratica media, che caratterizza la distanza media dalla valutazione media delle risposte di ciascun rispondente a una determinata domanda.
Piccola variazione
Variazione elevata
Fico. 4.1. Curve di variazione e distribuzione
Poiché tutte le soluzioni di marketing sono accettate in incertezza, questa circostanza è consigliabile prendere in considerazione quando si determina la dimensione del campione. Poiché la definizione dei valori studiati per un set in uno stretto viene effettuato sulla base di statistiche selettive, è necessario impostare l'intervallo (intervallo di confidenza), il che dovrebbe essere stimato per una totalità nel suo complesso, e il errore della loro definizione.
L'intervallo di confidenza è la gamma, i cui punti estremi corrispondono a una certa percentuale di alcune risposte ad alcune domande. L'intervallo di confidenza è strettamente associato a una deviazione quadratica media dell'attributo studiato nella popolazione generale: più, più è più ampio l'intervallo di confidenza dovrebbe essere per includere una certa percentuale di risposte.
L'intervallo di confidenza, uguale a o 95% o del 99%, è standard durante la conduzione della ricerca di marketing. Nessuna società conduce la ricerca di marketing formando diversi campioni. E le statistiche matematiche consentono di ottenere alcune informazioni sulla distribuzione selettiva, possedere solo dati sulle variazioni di un singolo campione.
L'indicatore della valutazione della valutazione, il vero per un set nel suo insieme, dalla valutazione che dovrebbe essere un campione tipico, è un errore quadratico medio. Inoltre, più il campionamento, più piccolo è l'errore. L'elevato valore della variazione determina l'alto valore dell'errore e viceversa.
Quando ci sono solo due opzioni per la domanda assegnata, espressa come percentuale (viene utilizzata una misura percentuale), la dimensione del campione è determinata dalla seguente formula:

dove n è la dimensione del campione; Z è la deviazione normalizzata, determinata sulla base del livello scelto di fiducia; P - Variazione trovata per il campionamento; G - (100-P); Errore e-consentito.
Nel determinare l'indicatore della variazione di un determinato set, in primo luogo, è consigliabile condurre un'analisi preliminare qualitativa della combustione studiata, innanzitutto stabilire la somiglianza delle unità di aggregazione nelle relazioni demografiche, sociali e altre relazioni di interesse per il ricercatore. È possibile condurre uno studio pilota, l'uso dei risultati di tali studi condotti in passato. Quando si utilizza una misura percentuale della variabilità viene presi in considerazione che la variabilità massima è raggiunta per P \u003d 50%, il che è il caso peggiore. Inoltre, questo indicatore radicalmente non influisce sulla dimensione del campione. Viene inoltre presa in considerazione il parere della ricerca del cliente sul volume del campionamento.
È possibile definire le dimensioni del campione in base all'uso dei valori medi e non sui valori percentuali.

dove è una deviazione quadratica secondaria.
In pratica, se il campione è formato di nuovo e sondaggi simili non sono stati eseguiti, allora s non è noto. In questo caso, è consigliabile impostare l'errore di E nelle frazioni della deviazione standard. La formula calcolata viene convertita e acquisisce il seguente modulo:
 dove
dove  .
.
Sopra c'era una conversazione sugli aggregati di dimensioni molto grandi. Tuttavia, in alcuni casi, l'aggregato non è grande. Di solito, se il campione è inferiore al 5% dell'aggregato, l'aggregato è considerato grande e i calcoli sono effettuati in base alle norme di cui sopra. Se la dimensione del campione supera il 5% dell'aggregato, quest'ultimo è considerato piccolo e la formula di cui sopra è introdotta da un coefficiente di correzione.
La dimensione del campione in questo caso è definita come segue:
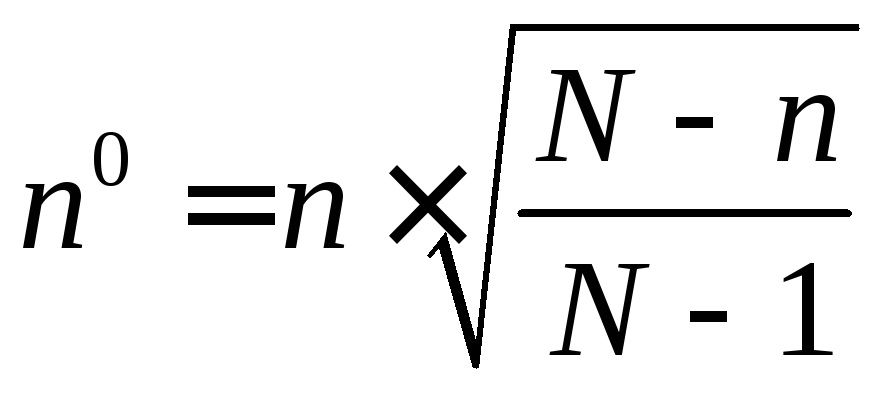 ,
,
dove n è la dimensione del campione per un piccolo aggregato; N 0 - la dimensione del campione calcolata secondo le formule sopra indicate; N è il volume della popolazione generale.
Ovviamente, l'uso di campioni più piccoli porterà al risparmio di tempo e al denaro.
Le formule sopra indicate per il calcolo delle dimensioni del campione si basano sull'assunzione che tutte le regole di formazione del campione sono state osservate e l'unico errore del campione è un errore dovuto al suo volume. Tuttavia, va ricordato che la dimensione del campione determina l'accuratezza dei risultati ottenuti, ma non la loro rappresentatività.
Quest'ultimo è determinato dal metodo di campionamento. Tutte le formule per il calcolo delle dimensioni dei campioni suggeriscono che la rappresentatività è garantita utilizzando corrette procedure di campionamento probabilistiche corrette.
Il volume, il campione è determinato dagli obiettivi analitici, degli obiettivi dello studio e della sua rappresentatività è l'installazione di destinazione del programma. È il programma che stabilisce l'immagine della popolazione generale necessaria per il campionamento. Se sarà tutta la popolazione o le sue speciali formazioni strutturali, tutti gli elementi dell'oggetto sono studiati o solo assegnati in base al programma specificato dei criteri, la popolazione generale è tutte le unità definite nel programma Object.
Durante un approccio deterministico alla struttura del campione, in generale, non è possibile che sia possibile determinare con precisione il suo volume in conformità con il criterio specificato per l'affidabilità delle informazioni ricevute. In questo caso, la dimensione del campione può essere determinata empirica. L'attività della ricerca di marketing all'estero può servire come linea guida. Quindi, quando si esaminano gli acquirenti, è garantita l'alta precisione del campione, anche se il suo volume non supera l'1% dell'intero set durante la conduzione di sondaggi per i clienti di medie e grandi imprese di vendita, il numero di intervistati (volume di campionamento) è di solito fluttuato da 500 a 1000 persone.
Il valore della procedura per la selezione del metodo di raccolta delle informazioni primarie e gli strumenti dello studio è che i risultati di questa selezione sono definiti sia l'affidabilità che la precisione delle informazioni da ottenere e la durata e il costo elevato del suo collezione.
Piano:
1. Compiti delle statistiche matematiche.
2. Tipi di campioni.
3. Metodi di campionamento.
4. Distribuzione di campionamento statistico.
5. Funzione di distribuzione empirica.
6. Poligono e istogramma.
7. Caratteristiche numeriche della serie variazionale.
8. Stime statistiche dei parametri di distribuzione.
9. Stime di intervalli dei parametri di distribuzione.
1. Compiti e metodi di statistica matematica
Statistiche matematiche - Questa è una sezione di matematica dedicata ai metodi per la raccolta, l'analisi e l'elaborazione dei risultati dei dati di osservazione statistica per scopi scientifici e pratici.
Lascia che sia necessario studiare la totalità degli oggetti omogenei relativi ad una caratteristica qualitativa o quantitativa che caratterizza questi oggetti. Ad esempio, se c'è una parte delle parti, lo standard della parte può essere una caratteristica di alta qualità e la dimensione quantitativa della parte è la parte quantitativa.
A volte viene eseguito uno studio solido, cioè. Esaminare ogni oggetto rispetto alla funzione desiderata. In pratica, un solido esame viene applicato raramente. Ad esempio, se la totalità contiene un numero molto elevato di oggetti, allora è fisicamente impossibile effettuare un solido esame. Se un sondaggio oggetto è associato alla sua distruzione o richiede costi materiali di grandi dimensioni, non ha senso condurre un solido esame. In tali casi, un numero limitato di oggetti (totalità selettiva) sono selezionati a caso dall'intero set e lo sfruttano.
Il compito principale delle statistiche matematiche è quello di studiare l'intera combinazione di dati selettivi, a seconda del set di scopo, I.e. Studio delle proprietà probabilistiche della totalità: la legge della distribuzione, delle caratteristiche numeriche, ecc. Per prendere decisioni di gestione in condizioni di incertezza.
2. Tipi di campioni
Aggregazione generale - Questa è una combinazione di oggetti da cui viene eseguito il campione.
Aggregazione selettiva (campione) - Questa è una combinazione di oggetti selezionati a caso.
Volume di aggregato. - Questo è il numero di oggetti di questa totalità. Il volume della popolazione generale è indicatoN, selettivo - n.
Esempio:
Se sono selezionati 1000 parti per un sondaggio di 100 parti, il volume della popolazione generaleN. \u003d 1000 e campionamenton \u003d 100.
Singolo campionamento È possibile eseguire in due modi: dopo che l'oggetto è selezionato e osservato sopra, può essere restituito o non restituito alla popolazione generale. Così I campioni sono suddivisi in ripetuti e riputtiti.
Ripetuto Chiamata campioneA quale oggetto selezionato (prima della selezione del prossimo) viene restituito alla popolazione generale.
Captive.chiamata campionea cui l'oggetto selezionato nell'aggregato generale non è rimborsabile.
In pratica, di solito usano una selezione casuale di cadavere.
Affinché i dati di esempio, è stato possibile giudicare con sicurezza del segno del generale aggregato che sia interessato al segno, è necessario che gli oggetti di campionamento lo rappresentino correttamente. Il campione deve rappresentare correttamente le proporzioni della popolazione generale. Il campione dovrebbe essere rappresentante (rappresentante).
In virtù della legge di grandi numeri, si può sostenere che il campione sarà rappresentativo se è casuale.
Se il volume dell'aggregato generale è abbastanza grande, e il campione è solo una parte minore di questa totalità, la differenza tra i campioni di ri-e non repulsive viene cancellato; Nel caso limitante, quando è considerato un set generale infinito, e il campione ha un volume finito, questa distinzione scompare.
Esempio:
Nella rivista American "Revisione letteraria", con l'aiuto di metodi statistici, uno studio è stato condotto da proiezioni riguardanti l'esito delle prossime elezioni del presidente degli Stati Uniti nel 1936. I candidati per questo post erano fd. Roosevelt e A. M. Landon. Le directory degli abbonati telefoniche sono state prese come fonte per il gruppo generale di americani studiati. Di questi, 4 milioni di indirizzi sono stati scelti a caso., Per il quale gli editori della rivista hanno inviato cartoline con una richiesta di esprimere il loro atteggiamento nei confronti dei candidati per la presidenza. Elaborazione dei risultati del sondaggio, la rivista ha pubblicato una previsione sociologica che Landon vincerà le prossime elezioni con un grande vantaggio. E ... Ero sbagliato: Roosevelt ha vinto la vittoria.
Questo esempio può essere visto come un esempio di un campione non rappresentative. Il fatto è che negli Stati Uniti nella prima metà del ventesimo secolo, i telefoni avevano solo una ricchezza di una parte della popolazione che ha sostenuto le opinioni del Landon.
3. Metodi di selezione
In pratica, vengono applicati vari metodi di selezione, che possono essere suddivisi in 2 tipi:
1. La selezione non richiede lo smembramento della popolazione generale di parte (a) semplice incursione casuale; b) ripetuto casuale semplice).
2. La selezione in cui l'aggregato generale è diviso in parti. (ma) selezione tipica; b) selezione meccanica; nel) seriale selezione).
Semplicemente casuale chiamato tali. selezionein cui gli oggetti vengono recuperati secondo una delle intera popolazione generale (a caso).
Tipico Chiamata selezioneIn quali oggetti non sono selezionati dall'intera popolazione generale, ma da ciascuna delle sue parti "tipiche". Ad esempio, se la parte viene effettuata su più macchine, la selezione non viene prodotta dall'intera totalità di parti prodotte da tutte le macchine, e dai prodotti di ciascuna macchina separatamente. Poiché tale selezione viene utilizzata quando gli indicatori di prova variano notevolmente in varie parti "tipiche" della popolazione generale.
Meccanicochiamata selezione, in cui il set generale "meccanico" è diviso in così tanti gruppi poiché gli oggetti dovrebbero essere inclusi nel campione e un oggetto viene prelevato da ciascun gruppo. Ad esempio, se è necessario selezionare il 20% delle parti realizzate dalla macchina, quindi viene presa ogni 5 ° parte; Se si desidera selezionare i dettagli del 5%, ogni 20, ecc. A volte tale selezione potrebbe non fornire la rappresentatività del campione (se viene selezionato ogni rullo di scarico del 20, e immediatamente dopo la selezione, la taglierina viene sostituita, tutti i rulli vengono catturati dalle frese azzerata.
Seriale Chiamata selezioneIn quali oggetti sono selezionati dalla popolazione generale non uno per uno, ma la "serie", che è sottoposta a un solido esame. Ad esempio, se i prodotti sono fabbricati un grande gruppo di macchine utensili, solo solo più macchine sono soggette a un solido esame.
In pratica, viene spesso utilizzata una selezione combinata, che combina i metodi di cui sopra.
4. Distribuzione statistica del campione
Lascia che un campione sia stato estratto dalla popolazione generale e dal valore x 1- Una volta, x 2 -n 2 volte, ... x k - n k volte. n \u003d. n 1 + N 2 + ... + N K è la dimensione del campione. Valori osservatichiamato opzionie la sequenza dell'opzione registrata nell'ordine crescente varietà vicino. Numerichiamato frequenze (frequenze assolute)e la loro relazione con le dimensioni del campione- frequenze relative o probabilità statistiche.
Se la quantità della variante è grande o il campione è realizzato da un set generale continuo, la serie variazionale non è compilata da valori di punti separati, ma a intervalli dei valori della popolazione generale. Questa serie variazionale è chiamata intervallo.La lunghezza degli intervalli dovrebbe essere uguale.
Distribuzione statistica del campione Chiamato un elenco di opzioni e frequenze corrispondenti o frequenze relative.
La distribuzione statistica può anche essere specificata come una sequenza di intervalli e corrispondente alle loro frequenze (importi in frequenza in questo intervallo di valori)
La gamma di frequenze di variazione del punto può essere presentata dalla tabella:
| X I. |
x 1. |
x 2. |
… |
X k. |
| N I. |
N 1. |
N 2. |
… |
N k. |
Allo stesso modo, è possibile inviare una serie variazionale di punti di frequenze relative.
E:
Esempio:
Il numero di lettere in qualche testo X era uguale a 1000. Il primo incontro del "I", la seconda lettera "e", la terza e la lettera "A", il quarto "Yu". Quindi le lettere "O", "E", "u", "e", "s".
Beviamo i luoghi che occupano rispettivamente nell'alfabeto, abbiamo: 33, 10, 1, 32, 16, 6, 21, 31, 29.
Dopo aver ordinato questi numeri, ascendendo, otteniamo una serie variazionale: 1, 6, 10, 16, 21, 29, 31, 32, 33.
Le frequenze dell'aspetto delle lettere nel testo: "A" - 75, "E" -87, "e" - 75, "O" - 110, "Y" - 25, "S" - 8, "E" - 3 "" - 7, "I" - 22.
Facciamo una gamma di frequenze variazionali del punto:
Esempio:
La distribuzione di frequenze del volume di campionamento è impostatan \u003d 20.
Effettua una gamma variazionale di punti di frequenze relative.
| X I. |
2 |
6 |
12 |
| N I. |
3 |
10 |
7 |
Decisione:
Trova frequenze relative:
| X I. |
2 |
6 |
12 |
| W I. |
0,15 |
0,5 |
0,35 |
Quando si costruisce una distribuzione dell'intervallo, ci sono le regole del numero di intervalli o della grandezza di ciascun intervallo. Il criterio qui è il rapporto ottimale: con un aumento del numero di intervalli, la rappresentatività è migliorata, ma la quantità di dati e del tempo relativa alla loro lavorazione aumenta. Differenza x max - X min tra i più grandi e i valori più piccoli sono chiamati ruota campioni.
Per contare il numero di intervallik. Di solito usato la formula empirica di secrethess (implica per l'arrotondamento al più vicino pratico intuto):k \u003d 1 + 3.322 lg n.
Di conseguenza, il valore di ogni intervalloh. può essere calcolato dalla formula:
5. Funzione di distribuzione empirica
Considera qualche campione dalla popolazione generale. Lascia che sia noto la distribuzione statistica delle frequenze della caratteristica quantitativa di X. Introduciamo la notazione: n x- il numero di osservazioni in cui è stato osservato il significato di una caratteristica inferiore a X;n. - Numero totale di osservazioni (campionamento). Frequenza di eventi relativi x<х равна n x / n. Se X cambia, la frequenza relativa cambia, I.e. Frequenza relativan x / n- C'è una funzione da x. Perché È empiricamente, è chiamato empirico.
Funzione di distribuzione empirica (funzione di campionamento) Call Function.Definizione per ogni x frequenza di eventi relativi x<х.
dove il numero è il più piccolo x,
n - volume di campionamento.
A differenza della funzione di distribuzione empirica del campione, viene chiamata la funzione della distribuzione f (x) della popolazione generale funzione di distribuzione teorica.
La differenza tra le funzioni di distribuzione empirica e teorica è che la funzione teorica F (x) determina la probabilità dell'evento X
Così Si consiglia di utilizzare la funzione di distribuzione empirica del campione per una rappresentazione approssimativa della funzione teorica (integrale) della distribuzione della popolazione generale.
F * (x)ha tutte le proprietàF (x).
1. Valori F * (x)appartengono all'intervallo.
2. F * (x) - funzione non decrescente.
3. Se - la variante più piccola, tf * (x) \u003d 0, con x < x 1; Se x K è la variante più grande, quindi f * (x) \u003d 1, a x\u003e x k.
Quelli. F * (x)usato per stimare f (x).
Se il campione è impostato dal lato variazionale, la funzione empirica ha il modulo:
Il grafico di una funzione empirica è chiamato cumulativo.
Esempio:
Costruisci una funzione empirica su questa distribuzione del campione.
Decisione:
Volume di campionamento n \u003d 12 + 18 +30 \u003d 60. L'opzione più piccola 2, I.e. a x. <
2. Evento X.<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F * (x) \u003d 12/60 \u003d 0,2alle 2. <
X. <
6. Evento H.<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
x. <
10. Perché x \u003d 10 l'opzione più grande allora F * (x) \u003d 1a x\u003e 10. La funzione empirica desiderata ha la forma:
Cumulat:
Cumulat consente di comprendere le informazioni graficamente presentate, ad esempio, per rispondere alle domande: "Determinare il numero di osservazioni, in cui il valore del carattere era inferiore a 6 o non inferiore a 6. F * (6) \u003d 0,2 "Quindi il numero di osservazioni in cui il valore della funzione osservata era inferiore a 6 uguale a 0,2 *n. \u003d 0,2 * 60 \u003d 12. Il numero di osservazioni in cui il valore della funzione osservata è stato almeno 6 uguale (1-0,2) *n \u003d 0,8 * 60 \u003d 48.
Se sono impostati i variazionari intervalli, quindi per la compilazione della funzione empirica della distribuzione, vengono trovati gli intervalli intermedi e la funzione di distribuzione empirica è ottenuta da una serie di variazioni del punto.
6. Poligono e istogramma
Per la chiarezza costruire vari grafici di distribuzione statistica: polinomio e istogrammi
Poligono Questo è un segmento rotto e rotto dei quali collega i punti (x 1; n 1), (x 2; n 2), ..., (x k; n k), dove - opzioni - le frequenze corrispondenti.
Frequenza relativa del poligono Questo è un segmento rotto, di cui collegare i punti (x 1; w 1), (x 2; w 2), ..., (xk; wk), dove l'I-Vintage, w I - Le relative frequenze corrispondenti a loro.
Esempio:
Costruisci frequenze relative polinomiali su questa distribuzione del campione:
Decisione:
Nel caso di una caratteristica continua, è consigliabile costruire un istogramma, per il quale l'intervallo in cui tutti i valori delle caratteristiche osservati sono suddivisi in diversi intervalli parziali della lunghezza H e si trovano per ciascun intervallo parziale n I - il Importo delle frequenze di frequenza nell'intervallo I-cell. (Ad esempio, quando si misura la crescita umana o il peso, abbiamo a che fare con un segno continuo).
Frequenza dell'istogramma Questa è una figura a gradini costituita da rettangoli, le quali servono come intervalli parziali con lunghezza H, e le altezze sono uguali al rapporto (densità di frequenza).
La zona i -TO-rettangolo parziale uguale alla quantità della versione di frequenza dell'intervallo I - Th, I.e. L'area dell'istogramma di frequenza è uguale alla somma di tutte le frequenze, cioè. Campionamento.
Esempio:
Vengono forniti i risultati del cambio di tensione (in volt) nella rete elettrica. Crea una serie variazionale, costruire un poligono e un istogramma di frequenza, se i valori di tensione sono i seguenti: 227, 215, 230, 232, 222, 220, 22, 22, 212, 220, 228, 22, 212, 220, 228, 222, 217, 220 .
Decisione:
Facciamo una serie variazionale. Abbiamo n \u003d 20, x min \u003d 212, x max \u003d 232.
Applicare la formula universitaria per il conteggio del numero di intervalli.
L'intervallo di variazione della gamma di frequenze ha il modulo:
|
|
Densità di frequenza |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
Costruiamo l'istogramma di frequenza:
Costruiamo un poligono di frequenza, trovando intervalli pre-mezzo:
Istogramma di frequenze relative Chiamare una figura a gradini costituita da rettangoli, le cui basi sono intervalli parziali con lunghezza h, e l'altezza è uguale al rapporto w IO./ h (relativa densità di frequenza).
La zona i -to opzione parziale di parità di rettangolo di frequenza che è caduto nel I - C. Quelli. L'area del relativo istogramma di frequenza è uguale alla somma di tutte le frequenze relative, cioè. unità.
7. Caratteristiche numeriche della serie di variazioni
Considera le caratteristiche principali dei set generali e selettivi.
Generalesi chiama i valori aritmetici medi del segno della popolazione generale.
Per diversi valori x 1, x 2, x 3, ..., x n. Segno della popolazione generale del volume N Abbiamo:
Se i valori del personaggio hanno le frequenze corrispondenti n 1 + n 2 + ... + n k \u003d n, quindi
Medioeletto selettivosi chiama i valori aritmetici medi del segno del set di campioni.
Se i valori del personaggio hanno le frequenze corrispondenti n 1 + n 2 + ... + n k \u003d n, quindi
Esempio:
Calcola la media selettiva per il campione: x 1 \u003d 51.12; x 2 \u003d 51.07; x 3 \u003d 52.95; x 4 \u003d 52,93; x 5 \u003d 51,1; x 6 \u003d 52.98; x 7 \u003d 52.29; x 8 \u003d 51.23; x 9 \u003d 51.07; x 10 \u003d 51.04.
Decisione:
Dispersione generalesi chiama piazze aritmetiche di deviazioni dei valori della caratteristica della popolazione generale della media generale.
Per vari valori x 1, x 2, x 3, ..., x n, il segno del set generale del volume n Abbiamo:
Se i valori del personaggio hanno le frequenze corrispondenti n 1 + n 2 + ... + n k \u003d n, quindi
Deviazione generale radiatral (standard) Chiama una radice quadrata dalla dispersione generale
Dispersione selettiva Si chiama i quadrati aritmetici medi delle deviazioni dei valori osservati della funzione dal valore medio.
Per diversi valori x 1, x 2, x 3, ..., x n, un segno di set selettivo di volume n Abbiamo:
Se i valori del personaggio hanno le frequenze corrispondenti n 1 + n 2 + ... + n k \u003d n, quindi
Deviazione RMS selettiva (standard) Si chiama una radice quadrata dalla dispersione selettiva.
Esempio:
Set Set Set Set Tabella di distribuzione. Trova una dispersione selettiva.
Decisione:
Teorema: La dispersione è uguale alla differenza tra i quadrati medi dei segni e il quadrato della media totale.
Esempio:
Trova dispersione su questa distribuzione.
Decisione:
8. Stime statistiche dei parametri di distribuzione
Lasciare esaminare l'aggregato generale su qualche campione. In questo caso, è possibile ottenere solo il valore approssimativo del parametro SCOLOGGIO Q, che funge da valutazione. Ovviamente, le stime possono variare da un campione all'altro.
Valutazione statisticaQ * Il parametro sconosciuto della distribuzione teorica è la funzione f, a seconda dei valori del campione osservati. Il compito della valutazione statistica dei parametri sconosciuti sul campione è quello di creare una tale funzione dai dati disponibili da osservazioni statistiche, che fornirebbero i valori approssimativi più accurati del reale, non noti al ricercatore, i valori di questi parametri.
Le stime statistiche sono suddivise in punto e intervallo, a seconda del metodo di fornitura (per numero o intervallo).
Valutazione statistica della chiamata del punto Il parametro Q della distribuzione teorica è determinata da un valore del parametro Q * \u003d f (x 1, x 2, ..., x n), dovex 1, x 2, ..., x n- Risultati delle osservazioni empiriche sul segno quantitativo X di qualche campione.
Tali stime dei parametri ottenute in diversi campioni sono più spesso diverse l'una dall'altra. Differenza assoluta / Q * -Q / chiamata campionamento degli errori (stima).
Affinché le stime statistiche per dare risultati affidabili dei parametri stimati, è necessario che siano instabili, efficienti e coerenti.
Punto stima, l'aspettativa matematica di cui è uguale (non uguale) viene chiamato il parametro stimato non accurato (spostato). M (q *) \u003d Q.
La differenza m ( Q *) - Q Chiamato spostamento o errore sistematico. Per stime non correlate, l'errore sistematico è 0.
Efficace valutazione Q *, che, con un dato campionamento n, ha la più piccola dispersione possibile: Dmin (n \u003d const). La valutazione efficace ha la dispersione più piccola rispetto ad altre stime instabili e ricche.
Ricco Chiamato tale statistico valutazione Q *, che per nsi impegna per probabilità al parametro stimatoQ. . Con un aumento del campionamenton. La valutazione cerca come probabilità al vero valore del parametroQ.
Il requisito di coerenza è coerente con la legge del numero elevato: le informazioni più fonti sull'oggetto in studio, il risultato più accurato. Se la dimensione del campione è piccola, la stima del punto del parametro può portare a errori gravi.
Chiunque campionamento (volume.n) può essere considerato come un set ordinatox 1, x 2, ..., x nvariabili casuali distribuite ugualmente indipendenti.
Media selettiva per diversi campioni di volumen. dalla stessa popolazione generale sarà diversa. Cioè, la media selettiva può essere considerata come un importo casuale, e quindi, possiamo parlare della distribuzione del mezzo campione e delle sue caratteristiche numeriche.
Media selettiva soddisfa tutti i requisiti sovrapposti a stime statistiche, cioè. Dà una valutazione incredibile, efficiente e ricca della media generale.
Puoi dimostrarlo. Pertanto, la dispersione selettiva è una stima di prevenzione della dispersione generale, dandola un valore basso. Cioè, con un piccolo campionamento, darà un errore sistematico. Per una valutazione senza precedenti e ricca è sufficiente a prendere la quantitàche è chiamato la dispersione corretta. Questo è
In pratica, viene utilizzata una dispersione corretta per stimare la dispersione generale.n. < 30. In altri casi (n\u003e 30) deviazione da milita. Pertanto, a valori di grandi dimensionin. l'errore di spostamento può essere trascurato.
Puoi anche provare quella frequenza relativan I / N è una valutazione sbloccata e ricca della probabilità.P (x \u003d x i ). Funzione di distribuzione empiricaF * (x ) è una valutazione instabile e ricca della funzione di distribuzione teoricaF (x) \u003d p (x< x ).
Esempio:
Trova valutazioni inconsistenti dell'aspettativa matematica della dispersione sulla tabella dei campioni.
| X I. |
|||
| N I. |
Decisione:
Volume di campionamento n \u003d 20.
La valutazione non formata dell'aspettativa matematica è la media selettiva.
Per calcolare la valutazione disinstallata della dispersione, troveremo per la prima volta una dispersione selettiva:
Ora troveremo una valutazione senza unsieme:
9. Stime di intervalli dei parametri di distribuzione
L'intervallo è una valutazione statistica determinata dai due valori numerici dell'intervallo in studio.
Numero\u003e 0, a cui | Q - Q * |< , caratterizza l'accuratezza della valutazione dell'intervallo.
Fiducia chiamato intervallo Con una data probabilitàcopre un valore sconosciuto del parametroQ. . Aggiunta dell'intervallo di fiducia a una varietà di tutti i valori dei parametri possibiliQ. chiamato regione critica. Se l'area critica si trova solo su un lato dell'intervallo di confidenza, viene chiamato l'intervallo di confidenza unilaterale: lato sinistroSe l'area critica esiste solo a sinistra e a destra Se solo a destra. Altrimenti, l'intervallo di confidenza è chiamato bilaterale.
Affidabilità o probabilità di confidenza valutazioni q (usando q *) Chiamare la probabilità con cui viene eseguita la seguente disuguaglianza: |Q - Q * |< .
Molto spesso, la probabilità di confidenza è specificata in anticipo (0,95; 0,99; 0,9999) e impongono un requisito di essere vicino a uno.
Probabilitàchiamata la probabilità di errore o livello di significato.
Let |. Q - Q * |< , poi. Ciò significa che con probabilitàsi può sostenere che il vero valore del parametroQ. Appartiene intervalli. Più piccolo è il valore di deflessioneInoltre, la valutazione.
Bordi (finisce) dell'intervallo di confidenza chiamato confida confini o bordi critici.
I valori dei confini dell'intervallo di confidenza dipendono dalla legge sulla distribuzione dei parametriQ *.
La grandezza della deviazionemetà della metà della larghezza dell'intervallo di confidenza, chiamato precisione di valutazione.
I metodi per la costruzione degli intervalli di confidenza sono stati sviluppati per la prima volta da American Statistian Y. Neuman. Valutazione della precisioneFiducia probabilità e campionamento N. correlati tra loro. Pertanto, conoscendo valori specifici di due valori, è possibile calcolare sempre il terzo.
Trovare l'intervallo di confidenza per valutare l'aspettativa matematica della distribuzione normale, se la deviazione standard è nota.
Lasciare un campione della popolazione generale subordinata alla legge della normale distribuzione. Lasciate sapere alla deviazione generale del quadrato medio generaleMa una destinazione matematica sconosciuta della distribuzione teoricaa ().
La seguente formula è valida:
Quelli. Secondo la definizione di deviazionepuò essere trovato con la probabilità che una media generale sconosciuta sia l'intervallo. E viceversa. Dalla formula è chiaro che con un aumento della dimensione del campione e il valore fisso della probabilità di confidenza, il valore- diminuisce, I.e. L'accuratezza della valutazione aumenta. Con un aumento dell'affidabilità (probabilità di fiducia), il valore- Anche, cioè La precisione di valutazione diminuisce.
Esempio:
Come risultato dei test, i seguenti valori sono stati ottenuti -25, 34, -20, 10, 21. È noto che sono soggetti alla legge della distribuzione normale con la deviazione RMS 2. Trova una stima a * Per l'aspettativa matematica A. Costruisci un intervallo di confidenza del 9% per lui.
Decisione:
Trova una stima incredibile
Poi
L'intervallo di confidenza per A ha la forma: 4 - 1,47< uN.< 4+ 1,47 или 2,53 < a < 5, 47
Trovare l'intervallo di confidenza per valutare l'aspettativa matematica della distribuzione normale, se sconosciuta è una deviazione standard.
Lascia che sia noto che l'aggregato generale è subordinato alla legge della distribuzione normale, dove A e. Accuratezza del copertura dell'intervallo di confidenza con affidabilitàil vero valore del parametro A, in questo caso è calcolato dalla formula:
, dove n è la dimensione del campione, , - Coefficiente degli studenti (dovrebbe essere trovato in base ai valori specificatin I. dalla tabella "Distribuzione critica dello studente").
Esempio:
Come risultato del test, sono stati ottenuti i seguenti valori -35, -32, -26, -35, -30, -17. È noto che obbediscono alla legge della normale distribuzione. Trova un intervallo di confidenza per l'aspettativa matematica e una popolazione generale con una probabilità di fiducia di 0.9.
Decisione:
Trova una stima incredibile.
Trova.
Poi
L'intervallo di fiducia prenderà la forma(-29.2 - 5.62; -29,2 + 5.62) o (-34.82; -23,58).
Trovare un'interline della confidenza per la dispersione e la deviazione standard della distribuzione normale
Lasciare una serie generale di valori distribuiti dalla normale legge, viene preso un campione casuale di volumen. < 30 Per quali varianze selettive sono calcolate: spostatoe corretto S 2. Quindi trovare stime di intervalli con la determinata affidabilitàper la dispersione generaleD. Deviazione del quadrato medio generalevengono utilizzate le seguenti formule.
o,
Valori- Trova con l'aiuto di una tabella di valori critici Distribuzione di Pearson.
L'intervallo di confidenza per la dispersione è da queste disuguaglianze erendo tutte le parti della disuguaglianza nel quadrato.
Esempio:
La qualità di 15 bulloni è stata controllata. Supponendo che l'errore nella loro fabbricazione sia subordinato alla normale legge sulla distribuzione e alla deviazione media selettivaallo stesso modo 5 mm, determinare con affidabilitàintervallo di fiducia per un parametro sconosciuto
I confini dell'intervallo saranno presentati sotto forma di doppia disuguaglianza:
Le estremità dell'intervallo di confidenza bilaterale per la dispersione possono essere determinate e senza eseguire azioni aritmetiche a un determinato livello di fiducia e volume del campione utilizzando la tabella appropriata (i confini degli intervalli di confidenza per dispersione a seconda del numero di gradi di libertà e affidabilità ). Per fare ciò, ottenuto dalla tabella dell'intervallo è moltiplicato per la dispersione corretta S 2.
Esempio:
Decido il compito precedente in un altro modo.
Decisione:
Troviamo la dispersione corretta:
Sul tavolo "i confini degli intervalli di confidenza per la dispersione, a seconda del numero di gradi di libertà e affidabilità, troveremo i confini dell'intervallo di confidenza per la dispersione quandok.\u003d 14 I.: Bordo inferiore 0,513 e superiore 2.354.
Moltiplicare i bordi ottenutis 2 ed estratto (perché abbiamo bisogno di un intervallo di confidenza non per dispersione, ma per la deviazione riconduttrica).
Come si può vedere dagli esempi, il valore dell'intervallo di confidenza dipende dal metodo della sua costruzione e dà vicini l'uno all'altro, ma risultati ineguali.
In campioni abbastanza grande volume (n.\u003e 30) I confini dell'intervallo di confidenza per la deviazione generale del quadrato medio possono essere determinati dalla formula: - Un numero che è tabaccato ed è dato nella tabella di riferimento pertinente.
Se 1- q.<1, то формула имеет вид:
Esempio:
Decidiamo il compito precedente al terzo modo.
Decisione:
Trovato precedentementes.= 5,17. q.(0.95; 15) \u003d 0,46 - troviamo sul tavolo.
Poi:
Stima dell'intervallo della probabilità di un evento. Formule per il calcolo delle dimensioni del campione con un metodo di selezione a prezzi accessibili.
Per determinare le probabilità degli eventi a cui sei interessato, utilizziamo il metodo selettivo: lo svolgiamo n. esperimenti indipendenti, in ciascuno dei quali possono verificarsi (o non accadere) evento A (probabilità r. L'aspetto degli eventi A in ogni esperimento è costante). Quindi la frequenza relativa p * apparenze di eventi MA Nella serie n. I test sono accettati come stima del punto per la probabilità. p. Aspetto dell'evento MA In un test separato. In questo caso, viene chiamato il valore di P * condividua selettiva Apparenze di eventi MAe r - generale .
In virtù dell'indagine dal teorema del limite centrale (The Moorev-Laplace Teorem), la frequenza relativa dell'evento con una grande quantità di campionamento può essere considerata normalmente distribuita con i parametri M (P *) \u003d P e
Pertanto, con N\u003e 30, l'intervallo di confidenza per la quota generale può essere costruito utilizzando formule:
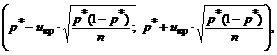
dove U KR si trova sui tavoli della funzione di Laplace, tenendo conto di una data probabilità fiduciario γ: 2F (U cr) \u003d γ.
Con una piccola dimensione del campione di n≤30, l'errore ε è determinato dalla tabella di distribuzione degli studenti: ![]() dove t kr \u003d t (k; α) e il numero di gradi di libertà k \u003d n-1 la probabilità α \u003d 1-γ (regione fronte / retro).
dove t kr \u003d t (k; α) e il numero di gradi di libertà k \u003d n-1 la probabilità α \u003d 1-γ (regione fronte / retro).
Le formule sono valide se la selezione è stata effettuata di nuovo a caso (la serie generale di infinita), altrimenti, è necessario effettuare una correzione alla peculiarità della selezione (tabella).
Errore medio di campionamento per azione generale
| Aggregazione generale | Infinito | Volume finito N. |
| Tipo di selezione | Ripetuto | Catturare |
| Errore medio del campione |
Formule per il calcolo delle dimensioni del campione con un metodo di selezione a prezzi accessibili
| Il metodo di selezione | Sampling formule numeriche | ||
| per il centro | per una quota | ||
| Ripetuto | |||
| Catturare | |||
Compiti generali
La domanda "copre l'intervallo di confidenza del valore specificato P 0?" - Puoi rispondere controllando l'ipotesi statistica H 0: P \u003d P 0. Si presume che gli esperimenti siano effettuati secondo lo schema di test di Bernoulli (indipendente, probabilità p. Aspetto dell'evento MA costante). Per volume del campione n. Determinare la frequenza relativa di P * l'aspetto dell'evento A: Dove m. - il numero di eventi MA Nella serie n. Test. Per controllare l'ipotesi H 0, vengono utilizzate le statistiche, aventi una distribuzione normale standard con un campione sufficientemente ampio (tabella 1).Tabella 1 - Ipotesi sulla proporzione generale
Ipotesi | H 0: P \u003d P 0 | H 0: P 1 \u003d P 2 |
| Ipotesi | Schema di test di Bernoulli | Schema di test di Bernoulli |
| Valutazioni del campione | 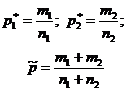 |
|
| Statistiche K. |  |  |
| Distribuzione statistica K. | Standard normale N (0,1) |
Esempio numero 1. Con l'aiuto di una riscossione casuale, la gestione della società ha condotto un sondaggio di esempio di 900 dei suoi dipendenti. Tra gli intervistati si sono rivelati 270 donne. Costruisci un intervallo di confidenza, con una probabilità di 0,95 che copre la proporzione vera delle donne in tutta la squadra della società.
Decisione. Per condizione, la quota di campione delle donne è (la frequenza relativa delle donne tra tutti gli intervistati). Poiché la selezione viene ripetuta e la dimensione del campione è grande (n \u003d 900) L'errore di selezione è determinato dalla formula ![]()
Il valore di U KR Trova la tabella della funzione Laplace dal rapporto 2F (U CR) \u003d γ, I.e. ![]() La funzione Laplace (Appendice 1) prende un valore di 0,475 a U KR \u003d 1.96. Pertanto, l'errore limite
La funzione Laplace (Appendice 1) prende un valore di 0,475 a U KR \u003d 1.96. Pertanto, l'errore limite ![]() e l'intervallo di confidenza desiderato
e l'intervallo di confidenza desiderato
(P - ε, P + ε) \u003d (0,3 - 0,18; 0,3 + 0,18) \u003d (0,12; 0,48)
Quindi, con una probabilità di 0,95, può essere garantito che la proporzione di donne in tutto il team della società è compresa tra 0,12 a 0,48.
Esempio numero 2. Il proprietario del parcheggio legge il giorno "successo" se il parcheggio è pieno di oltre l'80%. Durante l'anno sono stati condotti 40 controlli di parcheggio, di cui 24 "successo". Con una probabilità di 0,98, trova l'intervallo di confidenza per valutare la vera quota di giorni "di successo" durante l'anno.
Decisione. La quota del campione di "giorni di successo" è
Sulla funzione del tavolo della laplace, troveremo il valore di U CR con un dato
fiducia probabilità
F (2.23) \u003d 0,49, u kr \u003d 2.33.
Considerando che la selezione non è possibile (cioè, due controlli non sono stati condotti in un giorno), troviamo un errore limite: ![]()
dove n \u003d 40, n \u003d 365 (giorni). Da qui ![]()
e l'intervallo di confidenza per la quota generale: (P - ε, P + ε) \u003d (0,6 - 0,17; 0,6 + 0,17) \u003d (0.43; 0,77)
Con una probabilità di 0,98, ci si può aspettare che la quota dei giorni "di successo" durante l'anno sia compresa tra 0,43 a 0,77.
Esempio numero 3. Controllo di 2500 prodotti nella parte, ha scoperto che 400 prodotti del grado più alto e N-M - no. Quanto hai bisogno di controllare i prodotti per determinare la quota del voto più alto con la fiducia del 95% fino a 0,01?
Soluzione Stiamo cercando la formula per determinare il numero di campionamento per la riscossione.
F (t) \u003d γ / 2 \u003d 0.95 / 2 \u003d 0,475 e questo valore sulla tabella di laplace corrisponde a t \u003d 1.96
Condivisione selettiva w \u003d 0,16; Errore durante il campionamento ε \u003d 0,01
ESEMPIO numero 4. Il lotto di prodotti è accettato se la probabilità che il prodotto sarà lo standard appropriato sia almeno 0,97. Tra i prodotti selezionati a caso 200 del batch ricevuto sono stati 193 standard pertinenti. È possibile a livello di significato α \u003d 0,02 per accettare la festa?
Decisione. Formulamo l'ipotesi principale e alternativa.
H 0: P \u003d P 0 \u003d 0.97 - Azioni generali sconosciute p. uguale a un dato valore p 0 \u003d 0.97. In relazione alla condizione - la probabilità che la parte del lotto ricevuta sarà rilevante per lo standard, pari a 0,97; quelli. È possibile scattare un lotto di prodotti.
H 1: P<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Il valore osservato delle statistiche K. (Tabella) calcolati ai valori specificati p 0 \u003d 0.97, n \u003d 200, m \u003d 193

Il significato critico Trova la tabella della funzione di laplace dall'uguaglianza
![]()
Sotto la condizione α \u003d 0,02, da qui f (kkr) \u003d 0,48 e kkr \u003d 2.05. Regione critica sinistra, cioè. È l'intervallo (-∞; -k kp) \u003d (-∞; -2.05). Il valore osservato per l'ombelico \u003d -0.415 non appartiene all'area critica, quindi, a questo livello di significato non vi è alcun motivo per deviare l'ipotesi principale. Puoi prendere un lotto di prodotti.
ESEMPIO numero 5. Due piante fanno lo stesso tipo di dettagli. Per valutare la loro qualità, i campioni sono fatti dai prodotti di queste piante e vengono ottenuti i seguenti risultati. Tra 200 prodotti selezionati del primo impianto si sono rivelati 20 difettosi, tra 300 prodotti del secondo impianto - 15 difettosi.
A livello di importanza 0.025, scoprire se ci sono una differenza significativa delle parti prodotte da queste piante.
Sotto la condizione α \u003d 0,025, quindi f (ckr) \u003d 0,4875 e kkr \u003d 2.24. Con un'alternativa bilaterale, l'area dei valori ammissibili ha il modulo (-2.24; 2.24). Il valore osservato K NAVEL \u003d 2,15 cade in questo intervallo, cioè. A questo livello di significato non c'è motivo di respingere l'ipotesi principale. Le piante formano prodotti della stessa qualità.
Succede spesso che sia necessario analizzare qualsiasi particolare fenomeno sociale e ottenere informazioni a riguardo. Tali compiti spesso si verificano in statistiche e con studi statistici. Controlla completamente alcuni fenomeno sociale è il più spesso impossibile. Ad esempio, come scoprire il parere della popolazione o di tutti gli abitanti di una certa città su qualsiasi domanda? Chiedi assolutamente tutti - il caso è quasi impossibile e molto laborioso. In questi casi, abbiamo bisogno di un campione. Questo è esattamente il concetto su cui si basano quasi tutte le ricerche e i test.
Cos'è un campione
Quando si analizza un fenomeno sociale specifico, è necessario ottenere informazioni a riguardo. Se prendi qualche ricerca, allora si può notare che lo studio e l'analisi sono soggetti a non tutte le unità di un insieme di oggetto di ricerca. Viene presa in considerazione solo una certa parte dell'intera totalità. Questo processo è il campione: quando vengono studiate solo alcune unità dal set.
Naturalmente, molto dipende dal tipo di campionamento. Ma ci sono regole di base. La cosa principale è che la selezione dell'aggregato deve essere assolutamente casuale. Le unità di aggregato che verranno utilizzate non devono essere selezionate a causa di alcun criterio. Parlando approssimativamente, se hai bisogno di raccogliere una totalità della popolazione di una certa città e prendere solo gli uomini, allora lo studio sarà un errore, perché la selezione non è stata spesa accidentalmente, ma selezionata dal genere. Quasi tutti i metodi di esempio si basano su questa regola.
Regole di selezione
Affinché l'aggregato selezionato riflettere le principali qualità dell'intero fenomeno, dovrebbe essere costruita secondo le leggi specifiche, dove è necessario concentrarsi sulle seguenti categorie:
- campione (aggregato selettivo);
- popolazione generale;
- rappresentatività;
- errore rappresentativo;
- un'unità di aggregato;
- metodi per la costruzione di un campione.
Le caratteristiche dell'osservazione selettiva e del campionamento sono le seguenti:
- Tutti i risultati ottenuti sono basati su legislazioni e regole matematiche, cioè con una ricerca adeguata e sotto i calcoli corretti, i risultati non saranno distorti su base soggettiva.
- Dà l'opportunità molto più veloce e con meno tempo e risorse per ottenere il risultato, studiando l'intera serie di eventi, ma solo la loro parte.
- Può essere applicato per studiare vari oggetti: da problemi specifici, ad esempio, età, piano del Gruppo a cui siamo interessati, allo studio dell'opinione pubblica o dal livello di sostegno materiale della popolazione.
Osservazione selettiva
Selettivo: questa è una tale osservazione statistica, in cui lo studio non è soggetto all'intero gruppo di studiato, ma solo alcuni, selezionati in un certo modo la sua parte e i risultati dello studio di questa parte sono distribuiti all'intero set . Questa parte è chiamata set selettivo. Questo è l'unico modo per studiare una vasta gamma dell'oggetto dello studio.
Ma l'osservazione selettiva può essere utilizzata solo nei casi in cui è necessario indagare solo un piccolo gruppo di unità. Ad esempio, quando si studia il rapporto tra uomini alle donne nel mondo, verrà utilizzato un'osservazione selettiva. Per ovvi motivi, è impossibile tenere conto di ogni residente del nostro pianeta.
Ma con lo stesso studio, ma non tutti gli abitanti della Terra, ma una certa classe "A" in una scuola specifica, una certa città, un certo paese, può fare senza osservazione selettiva. Dopotutto, per analizzare l'intera serie dell'oggetto dello studio - è del tutto possibile. È necessario calcolare i ragazzi e le ragazze di questa classe - che sarà il rapporto.

Aggregazione selettiva e generale
In effetti, tutto è così difficile, come suona. In qualsiasi oggetto di studio, ci sono due sistemi: aggregato generale e selettivo. Che cos'è? Tutte le unità si riferiscono al generale. E per selezionare: tali unità del totale aggregato che sono state prese per il campione. Se tutto è fatto correttamente, la parte selezionata sarà un layout ridotto dell'intero (General) Set.
Se parliamo del generale aggregato, solo due tipi di esso possono essere distinti: un certo e indefinito aggregato generale. Dipende dal fatto che il numero totale di unità di questo sistema sia noto o meno. Se questo è un determinato set generale, il campione sarà più facile a causa di ciò che è noto quale percentuale del numero totale di unità sarà campione.
Questo momento è molto necessario nella ricerca. Ad esempio, se è necessario esaminare la percentuale di prodotti dolciari di qualità di scarsa qualità in una fabbrica particolare. Supponiamo che l'aggregato generale sia già definito. È noto che all'anno questa azienda produce 1000 dolciumi. Se si effettua un campione di 100 prodotti casuali pasticceria da questo mille e inviali all'esame, l'errore sarà minimo. Parlando approssimativamente, uno studio è stato riferito al 10% di tutti i prodotti e sui risultati che possiamo, tenendo conto dell'errore di rappresentatività, parlare della scarsa qualità di tutti i prodotti.
E se hai un campione di 100 prodotti dolciari da un aggregato generale indefinito, dove erano in realtà, ammessi, 1 milione di unità, il risultato del campione e la ricerca stessa sarà critica e imprecisa. Senti la differenza? Pertanto, la certezza della popolazione generale nella maggior parte dei casi è estremamente importante e influenza notevolmente il risultato dello studio.

Rappresentatività dell'aggregazione
Quindi, ora uno dei problemi più importanti - quale dovrebbe essere il campione? Questo è il momento principale dello studio. In questa fase, è necessario calcolare il campione e selezionare le unità del numero totale in esso. Il set è stato selezionato correttamente se determinate caratteristiche e caratteristiche della popolazione generale rimane in selettiva. Questo è chiamato rappresentante.
In altre parole, se, dopo la selezione, parte conserva le stesse tendenze e le stesse caratteristiche che l'intero importo dell'indagine, quindi tale set è chiamato rappresentante. Ma non ogni campione specifico può essere selezionato da una totalità rappresentativa. Ci sono tali oggetti dello studio, il cui campione semplicemente non può essere rappresentativo. Da qui e il concetto di un errore di rappresentatività si verifica. Ma ne parleremo di più di più.
Come fare un campione
Quindi, che la rappresentatività è massima, alloca tre regole di esempio di base:
- L'indicatore più univoco del numero di campione è del 20%. Il campione statistico del 20% offre quasi sempre il risultato il più vicino possibile alla realtà. Allo stesso tempo, non è necessario trasferire la maggior parte del generale aggregato per la maggior parte della popolazione generale. Il 20% del campione è l'indicatore che è stato sviluppato da molti studi. Diamo una piccola teoria. Più campione, più piccolo è l'errore di rappresentatività e più accurato il risultato dello studio. Più vicino è presente un set selettivo su generale in termini di numero di unità, più accurato e corretto saranno i risultati. Dopotutto, se esplori l'intero sistema, il risultato sarà al 100%. Ma non c'è un campione. Queste sono la ricerca in cui è investigata l'intero array, tutte le unità, quindi non ci interessa.
- Nel caso di inappropriato, il trattamento del 20% della popolazione generale è autorizzato a studiare le unità dell'aggregato per un importo di almeno 1001. È anche uno degli indicatori dello studio di una serie dell'oggetto del studio, che è stato prodotto nel tempo. Naturalmente, non darà risultati esatti per grandi array di ricerca, ma l'approccio massimo alla possibile accuratezza del campionamento.
- Nelle statistiche, ci sono molte formule e tavoli piegati. A seconda dell'oggetto dello studio e del criterio del campione, c'è una fattibilità di scegliere una formula. Ma questo articolo è utilizzato in studi complessi e multi-step.
Errore (errore) Rappresentatività
La caratteristica principale della qualità del campione selezionato è il concetto di "Errore Rappresentante". Che cos'è? Queste sono certe discrepanze tra gli indicatori di osservazione selettiva e solida. In termini di errore, la rappresentatività è divisa in affidabile, ordinaria e approssimativa. In altre parole, deviazioni ammissibili per un massimo del 3%, dal 3% dal 10% e dal 10 al 20%, rispettivamente. Sebbene sia auspicabile nelle statistiche che l'errore non supera il 5-6%. Altrimenti, c'è una ragione per parlare della rappresentatività insufficiente del campione. Per calcolare l'urgenza della rappresentatività e del modo in cui influenza la popolazione selettiva o generale, vengono presi in considerazione molti fattori:
- La probabilità con cui è necessario ottenere un risultato accurato.
- Il numero di unità di aggregato selettivo. Come accennato in precedenza, le meno unità saranno un campione, maggiore sarà un errore di rappresentatività e viceversa.
- L'uniformità della totalità in studio. Più è eterogeneo è una totalità, maggiore è l'incertezza della rappresentatività. La possibilità di aggregazione per essere rappresentativa dipende dall'uniformità di tutti i suoi componenti.
- Il metodo di selezione delle unità nel set selettivo.
In studi specifici, la percentuale dell'errore medio è solitamente impostata dal ricercatore stesso sulla base del programma di osservazione e secondo i dati degli studi precedentemente condotti. Di norma, un errore di campionamento valido è considerato un errore consentito (rappresentatività) entro il 3-5%.

Più - non sempre meglio
Vale anche la pena ricordare che la cosa principale nell'organizzazione dell'osservazione selettiva è di portare il suo volume a un minimo ammissibile. Non dovrebbe sforzarsi di eccessiva diminuzione dei confini dell'errore di campionamento, poiché ciò può portare a un aumento ingiustificato delle dimensioni di questi campioni e, pertanto, ad un aumento delle spese sull'osservazione selettiva.
Allo stesso tempo, è impossibile aumentare eccessivamente le dimensioni dell'urgenza della rappresentatività. In effetti, in questo caso, sebbene ci sarà una diminuzione della quantità di aggregazione selettiva, questo porterà a un deterioramento della precisione dei risultati ottenuti.
Quali domande vengono solitamente messe davanti al ricercatore
Qualsiasi studio se viene effettuato, quindi per uno scopo e ottenere alcuni risultati. Quando si conducono uno studio di esempio, di regola, le domande iniziali sono messe:
- Determinazione del numero richiesto di unità del aggregato selettivo, cioè, quante unità saranno esaminate. Inoltre, per uno studio accurato, il set deve essere rappresentativo.
- Calcolo dell'errore di urgenza con il livello di probabilità stabilito. È necessario notare che gli studi selettivi non accadono con un livello di probabilità del 100%. Se tale istanza, che ha condotto uno studio di un determinato segmento, sostiene che i loro risultati sono accurati con una probabilità del 100%, allora questa è una bugia. La pratica perenne ha già impostato la percentuale della probabilità di uno studio del campione correttamente condotto. Questo indicatore è del 95,4%.
Metodi per selezionare unità di ricerca nel campione
Non ogni campione è rappresentato. A volte lo stesso segno è diverso in generale in generale e nelle sue parti. Per raggiungere i requisiti di rappresentatività, è consigliabile utilizzare varie tecniche di campionamento. Inoltre, l'uso di uno o un altro metodo dipende da circostanze specifiche. Tra queste tecniche di creazione del campione si distinguono:
- selezione casuale;
- selezione meccanica;
- selezione tipica;
- selezione seriale (nido).
La selezione casuale è un sistema di misure volte a selezione casuale di unità di aggregazione, quando la probabilità di entrare nel campione è uguale a tutte le unità della popolazione generale. Si consiglia di applicare questa tecnica solo nel caso dell'omogeneità e di un piccolo numero di segni insiti in esso. Altrimenti, alcune caratteristiche caratteristiche del rischio non riflette nel campione. I segni di selezione casuale sono basati su tutti gli altri modi per costruire un campione.
Con la selezione meccanica delle unità viene eseguita attraverso un determinato intervallo. Se è necessario formare un campione di reati specifici, è possibile prelevare da tutte le schede contabili statistiche dei crimini registrati ogni 5, decima o 15a carta, a seconda del numero totale e della dimensione del campione. Lo svantaggio di questo metodo è che prima della selezione è necessario avere una contabilità piena di unità di aggregazione, quindi classifica e solo dopo che è possibile campionare con un determinato intervallo. Questo metodo richiede molto tempo, quindi non è spesso usato.

La selezione tipica (zone) è un tipo di campionamento, in cui la popolazione generale è divisa in gruppi omogenei su un certo segno. A volte i ricercatori usano altri termini invece di gruppi: "distretti" e "zone". Quindi, da ciascun gruppo in ordine casuale, un certo numero di unità è selezionato in proporzione al peso specifico del Gruppo nel totale aggregato. La selezione tipica è spesso effettuata in diverse fasi.
La selezione seriale è un metodo in cui la selezione delle unità viene eseguita da gruppi (serie) e tutte le unità del gruppo selezionato (serie) sono soggette al sondaggio. Il vantaggio di questo metodo è che a volte selezionando le singole unità più complicate di una serie, ad esempio, durante lo studio di una persona che sta servendo una frase. Nell'ambito delle aree selezionate, le zone applicano lo studio di tutte le unità senza eccezioni, ad esempio lo studio di tutte le persone che servono una sentenza in qualche particolare istituzione.
Campione
Campione o aggregazione selettiva - Molti casi (soggetti, oggetti, eventi, campioni), utilizzando una determinata procedura selezionata dalla popolazione generale per partecipare allo studio.
Caratteristiche del campionamento:
- Caratteristica qualitativa del campione - Chi sceglie esattamente e quali modi per costruire campioni usiamo per questo.
- Caratteristica quantitativa del campione - Quanti casi scelgono, in altre parole, la dimensione del campione.
La necessità di assaggiare
- L'oggetto dello studio è molto ampio. Ad esempio, i consumatori dei prodotti della società globali sono un numero enorme di mercati territorialmente sparsi.
- È necessario raccogliere informazioni primarie.
Campionamento
Campionamento - il numero di casi inclusi nel set selettivo. Dalle considerazioni statistiche si raccomanda che il numero di casi ammontasse almeno a 30-35.
Campioni dipendenti e indipendenti
Quando si confrontano due (o più) campioni, un parametro importante è la loro dipendenza. Se è possibile installare una coppia omomorfa (cioè quando un caso, uno e solo un caso dal campionamento X e viceversa) per ciascun caso in due campioni (e questa è la base della relazione è importante per la caratteristica caratteristica), tale I campioni sono chiamati dipendente. Esempi di campioni dipendenti:
- twins coppie
- due misurazioni di qualsiasi segno prima e dopo l'impatto sperimentale,
- mariti e mogli
- eccetera.
Nel caso in cui non vi sia tale relazione tra i campioni, questi campioni sono considerati indipendente, per esempio:
Di conseguenza, i campioni dipendenti hanno sempre lo stesso importo e il volume di indipendente può essere diverso.
Il confronto del campione è fatto utilizzando vari criteri statistici:
- e così via.
Rappresentatività
Il campione può essere considerato come rappresentante o non rappresentato.
Un esempio di campione non rappresentato
- Studio con gruppi sperimentali e di controllo che vengono messi in condizioni diverse.
- Ricerca con gruppi sperimentali e di controllo con il coinvolgimento di una strategia di selezione a coppie
- Studio usando un solo gruppo - sperimentale.
- Studio utilizzando un piano misto (fattore) - tutti i gruppi sono messi in condizioni diverse.
Tipi di campione
I campioni sono divisi in due tipi:
- probabilistico.
- incredibile
Campioni probabilistici
- Semplice campione probabilistico:
- Semplice campione ripetuto. L'uso di un simile campione si basa sul presupposto che ciascun rispondente con una pari quota di probabilità può cadere nel campione. Sulla base dell'elenco della popolazione generale, le carte sono elaborate con i numeri dei rispondenti. Sono posizionati in un mazzo, mescolato e la carta viene rimossa da loro, il numero è registrato, quindi torna indietro. Successivamente, la procedura viene ripetuta tutte le volte di cui abbiamo bisogno. Meno: ripetizione di unità di selezione.
La procedura per la creazione di un semplice campione casuale include i seguenti passaggi:
1. È necessario ottenere un elenco completo dei membri della popolazione generale e del numero di questo elenco. Tale lista, ricordiamo, è chiamato la base del campione;
2. Determinare la dimensione del campione stimata, cioè il numero previsto di rispondenti;
3. Estrarre dalla tabella dei numeri casuali come molti numeri che abbiamo bisogno di unità di esempio. Se 100 persone dovrebbero essere nel campione, 100 numeri casuali sono presi dalla tabella. Questi numeri casuali possono essere generati da un programma per computer.
4. Scegli tra l'osservazione basata sull'elenco, i numeri corrispondono ai numeri casuali scaricati
- Un semplice campione casuale ha ovvi vantaggi. Questo metodo è estremamente facile da capire. I risultati dello studio possono essere distribuiti alla totalità studiata. La maggior parte degli approcci per ottenere conclusioni statistiche includono la raccolta di informazioni utilizzando un semplice campione casuale. Tuttavia, un semplice metodo di esempio casuale ha almeno quattro limitazioni significative:
1. È spesso difficile creare la base del campione di osservazione, che consentirebbe un semplice campione casuale.
2. Il risultato dell'uso di un semplice campione casuale può essere una grande totalità, o una totalità distribuita da una grande area geografica, che aumenta significativamente il tempo e il costo della raccolta dei dati.
3. I risultati dell'uso di un semplice campione casuale sono spesso caratterizzati da una bassa precisione e da un maggiore errore standard rispetto ai risultati dell'uso di altri metodi probabilistici.
4. Come risultato dell'uso di SRS, può essere formato un campione affrettato. Sebbene i campioni ottenuti da una semplice selezione casuale, una media di rappresentare adeguatamente la popolazione generale, alcune di loro estremamente erroneamente rappresentano la totalità studiata. La probabilità di questo è particolarmente grande con un piccolo campione.
- Semplice campione cotturale. La procedura di costruzione del campione è la stessa, solo le carte con i numeri dei rispondenti non vengono restituite al mazzo.
- Campione probabilistico sistematico. È una versione semplificata del semplice campione probabilistico. Sulla base dell'elenco di aggregato generale dopo un certo intervallo (K), gli intervistati sono selezionati. Il valore è determinato per caso. Il risultato più affidabile è ottenuto con una popolazione generale omogenea, altrimenti è possibile la coincidenza del passo e alcuni modelli ciclici interni del campionamento (campionamento). Contro: lo stesso di un semplice campione probabilistico.
- Campione seriale (nido). Le unità di selezione sono serie statistiche (famiglia, scuola, brigata, ecc.). Gli elementi selezionati sono sottoposti a un solido esame. La selezione delle unità statistiche può essere organizzata per il tipo di campione casuale o sistematico. Meno: la possibilità di una maggiore omogeneità rispetto alla popolazione generale.
- Campione zone Nel caso di una popolazione generale disomogenea, prima di utilizzare un campione probabilistico con qualsiasi tecnica di selezione, si consiglia di dividere l'aggregato generale per le parti omogenee, tale campione è chiamato zone. I gruppi di zonizzazione possono fungere da educazione naturale (ad esempio, le aree della città) e qualsiasi segno, la base dello studio. Il segno, sulla base della quale la separazione viene effettuata, è chiamato un segno di fascio e zonizzazione.
- Campione "confortevole". La "comoda" procedura di esempio è stabilire contatti con unità di esempio "convenienti" - con un gruppo di studenti, una squadra sportiva, con amici e vicini. Se hai bisogno di ottenere informazioni sulla reazione delle persone a un nuovo concetto, questo campione è abbastanza giustificato. Il campione "conveniente" viene spesso utilizzato per pre-testare i questionari.
Campioni incredibili
La selezione in tale campione non viene eseguita secondo i principi del caso, ma secondo criteri soggettivi - accessibilità, tipica, di parità di rappresentazione, ecc.
- Quad Sample - Il campione è costruito come modello che riproduce la struttura della popolazione generale sotto forma di quote (proporzioni) dei segni studiati. Il numero di elementi campione con diverse combinazioni di funzionalità studiate è determinata con tale calcolo in modo che corrisponda alla loro quota (proporzioni) nella popolazione generale. Ad esempio, se il set generale abbiamo 5.000 persone, ci sono 2.000 donne e 3.000 uomini, quindi nel campione di quota avremo 20 donne e 30 uomini o 200 donne e 300 uomini. I campioni quotati sono più spesso basati su criteri demografici: sesso, età, regione, reddito, educazione e altri. Contro: di solito tali campioni sono non rappresentativi, perché Non puoi tenere conto di diversi parametri sociali. Pro: materiale facilmente accessibile.
- Metodo di palla di neve. Il campione è costruito come segue. Ogni rispondente, a partire dal primo, chiedi ai contatti dei suoi amici, colleghi, conoscenti che sarebbero adatti per le condizioni di selezione e potrebbero prendere parte allo studio. Pertanto, ad eccezione del primo passo, il campione è formato con la partecipazione degli oggetti stessi. Il metodo è spesso utilizzato quando è necessario trovare e intervistare i gruppi difficili da raggiungere degli intervistati (ad esempio, gli intervistati che hanno un alto reddito, gli intervistati appartenenti a un gruppo professionale, intervistati che hanno qualche hobby / hobby simili, ecc. )
- Il campione spontaneo è un campione del cosiddetto "primo bancone". Spesso usato in televisione e stelle radio. Le dimensioni e la composizione dei campioni naturali non sono note in anticipo, ed è determinata da un solo parametro - l'attività degli intervistati. Contro: È impossibile stabilire quale generale è stato intervistato, e di conseguenza, l'incapacità di determinare la rappresentatività.
- Il sondaggio del percorso è spesso usato se l'unità dello studio è la famiglia. Sulla mappa dell'insediamento in cui verrà effettuata il sondaggio, tutte le strade sono numerate. Con l'aiuto del tavolo (generatore) dei numeri casuali, sono selezionati numeri di grandi dimensioni. Ogni numero elevato è visto come composto da 3 componenti: il numero della strada (2-3 primi numeri), il numero della casa, il numero dell'appartamento. Ad esempio, il numero 14832: 14 è il numero della strada sulla mappa, 8 - numero di casa, 32 - sala appartamenti.
- Un campione zone con la selezione di oggetti tipici. Se, dopo la zonizzazione, viene selezionato un oggetto tipico da ciascun gruppo, cioè. L'oggetto che per la maggior parte delle caratteristiche studiato nello studio si avvicina agli indicatori medi, tale campione è chiamato un tipo di tipici oggetti-zonizzati.
6. Campione di coda. 7. Campione esperto. 8. Esempio di campione.
Strategie per gruppi di costruzione
La selezione dei gruppi per la loro partecipazione all'esperimento psicologico viene effettuato utilizzando varie strategie necessarie per garantire la massima conformità possibile con validità interna ed esterna.
Randomizzazione
Randomizzazione, o selezione casualeUsato per creare semplici campioni casuali. L'uso di un simile campione si basa sull'assunzione che ciascun membro della popolazione con una probabilità uguale possa cadere nel campione. Ad esempio, per creare un campione casuale di 100 studenti universitari, puoi piegare i documenti con i nomi di tutti gli studenti universitari in un cappello, e quindi ottenere 100 pezzi di carta da esso - sarà una selezione casuale (Goodwin J., p. 147).
Selezione di accoppiamento
Selezione di accoppiamento - Strategia per la costruzione di gruppi di campionamento, in cui gruppi di soggetti sono compilati da soggetti equivalenti a significativi per l'esperimento da parametri collaterali. Questa strategia è efficace per gli esperimenti utilizzando gruppi sperimentali e di controllo con un'opzione migliore - attirando coppie gemelle (mono- e composizione), in quanto ti permette di creare ...
Selezione passionometrica
Selezione passionometrica - Randomizzazione con l'assegnazione di strato (o cluster). Con questo metodo per formare il campione, il set generale è diviso in gruppi (strati) con determinate caratteristiche (sesso, età, preferenze politiche, educazione, livello di reddito, ecc.), E i soggetti sono selezionati con le caratteristiche corrispondenti.
Modellizzazione approssimativa
Modellizzazione approssimativa - Strutturare campioni limitati e riassumare le conclusioni su questo campione su una popolazione più ampia. Ad esempio, con la partecipazione allo studio degli studenti del 2 ° anno dell'università, i dati di questo studio si applicano a "persone di età compresa tra 17 e 21 anni". La permessi di tali generalizzazioni è estremamente limitata.
Modellazione approssimativa - La formazione di un modello che è una classe chiaramente specificata di sistemi (processi) descrive il suo comportamento (o fenomeni necessari) con precisione accettabile.
Appunti
Letteratura
Hrenov A. D. Metodi matematici di ricerca psicologica. - SPB.: Discorso, 2004.
- Ilyasov F.n. Rappresentatività del sondaggio risulta in uno studio di marketing // Ricerca sociologica. 2011. № 3. P. 112-116.
Guarda anche
- In alcuni tipi di ricerca, il campione è diviso in gruppi:
- sperimentale
- controllo
- Coorte
Collegamenti
- Il concetto di campionamento. Le principali caratteristiche del campione. Tipi di campione
Fondazione Wikimedia. 2010.
Sinonimi:- Shchepkin, Mikhail Semenovich
- Aggregazione generale
Guarda cos'è "campione" in altri dizionari:
campione - un gruppo di argomenti che rappresentano una determinata popolazione e selezionati per l'esperimento o la ricerca. Il concetto opposto è un insieme generale. Il campione è parte della totalità generale. Dizionario di uno psicologo pratico. Albero, ... ... Grande enciclopedia psicologica.
campione - parte del campione della combinazione generale di elementi coperti dall'osservazione (viene spesso chiamato il set selettivo e l'esempio stesso è il metodo elettorale stesso). Nelle statistiche matematiche, adottato ... ... Directory tecnica del traduttore.
Campione - (campione) 1. Una piccola quantità di merci selezionate per rappresentare tutto il suo numero. Vedi: Vendita per esempio. 2. Una piccola quantità di merci trasmesse ai potenziali acquirenti per dare loro l'opportunità di spenderlo ... ... Dizionario dei termini di lavoro
Campione - Parte della combinazione generale di elementi coperti dall'osservazione (è spesso chiamata set selettivo e l'esempio stesso è il metodo di osservazione selettiva). Nelle statistiche matematiche, viene adottato il principio della selezione casuale; questo è… … Economia e dizionario matematico
CAMPIONE - (campione) Selezione arbitraria del sottogruppo di elementi dall'aggregato principale, le cui caratteristiche sono utilizzate per valutare l'intera totalità nel suo complesso. Il metodo selettivo viene utilizzato quando è troppo lungo o troppo costoso per esaminare l'intero set ... Dizionario economico
campione - Cm … Sinonimo dizionario