सामान्य कुल और चुनिंदा अध्ययन। सांख्यिकीय आत्मविश्वास
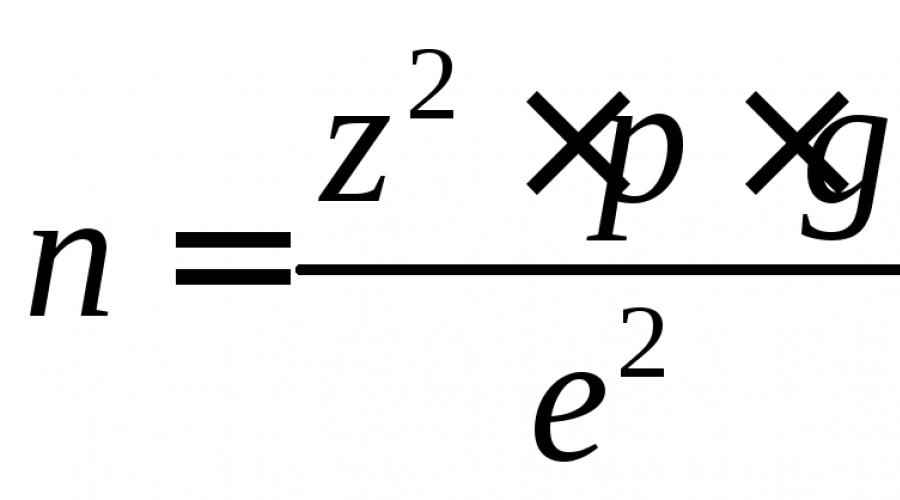
नमूना योजना को चित्रित करने की प्रक्रिया में शामिल हैं तीन निम्नलिखित कार्यों का अनुक्रमिक समाधान:
अध्ययन की वस्तु का निर्धारण;
नमूना संरचना का निर्धारण;
नमूनाकरण का निर्धारण।
आमतौर पर, ऑब्जेक्ट मार्केटिंग रिसर्च यह अवलोकन वस्तुओं का संयोजन है, जो उपभोक्ता, कंपनी के कर्मचारी, मध्यस्थों, आदि को खेला जा सकता है। यदि यह कुटिलता इतनी छोटी है कि शोध दल के पास आवश्यक प्रत्येक तत्व के साथ संपर्क स्थापित करने के लिए आवश्यक श्रम, वित्तीय और अस्थायी क्षमताएं हैं, तो यह पूरी आबादी का निरंतर अध्ययन करने के लिए काफी यथार्थवादी है। इस मामले में, अध्ययन की वस्तु को परिभाषित करके, आप निम्न प्रक्रिया (डेटा संग्रह विधि, अनुसंधान के साधन और दर्शकों के साथ संचार की विधि) के लिए आगे बढ़ सकते हैं।
हालांकि, व्यावहारिक रूप से पूरी आबादी का निरंतर अध्ययन करने के लिए यह संभव नहीं है या उचित नहीं है। ऐसा करने के लिए, निम्नलिखित कारण हो सकते हैं:
कुल मिलाकर कुछ तत्वों के साथ संपर्क स्थापित करने में असमर्थता;
ठोस अध्ययन या वित्तीय प्रतिबंधों की उपलब्धता की अनुचित रूप से बड़ी लागत जो ठोस शोध की अनुमति नहीं देते हैं;
सूचना या अन्य कारणों की प्रासंगिकता के साथ नुकसान के कारण अनुसंधान के लिए आवंटित सुगंधित समय सीमा पूरी कुशलता के लिए व्यापक डेटा के संग्रह, व्यवस्थितकरण और विश्लेषण की अनुमति नहीं दे रही है।
इसलिए, बड़े और बिखरे हुए योगों को अक्सर नमूनाकरण द्वारा अध्ययन किया जाता है, जिसके तहत, जैसा कि अच्छी तरह से जाना जाता है, कुल मिलाकर कुल मिलाकर कुशलता को व्यक्त करने के लिए समझा जाता है।
सटीकता जिसके साथ नमूना पूरी तरह से संपूर्णता को दर्शाता है, इस पर निर्भर करता है नमूना संरचना और आकार.
नमूना संरचना के लिए दो दृष्टिकोणों को अलग करें - संभाव्य और निर्धारक।
नमूना संरचना के लिए संभाव्य दृष्टिकोण यह मानता है कि कुल के किसी भी तत्व को एक निश्चित (शून्य नहीं) संभावना के साथ चुना जा सकता है। संभावनाओं के सिद्धांत (ठेठ, घोंसले, आदि) के आधार पर विभिन्न प्रकार के नमूने हैं। अभ्यास में सबसे आसान और सामान्य एक साधारण यादृच्छिक नमूना है, जिसमें कुल के प्रत्येक तत्व के अध्ययन के लिए समान विकल्प है।
एक संभाव्य नमूना अधिक सटीक है, शोधकर्ता को उनके द्वारा एकत्रित आंकड़ों की विश्वसनीयता की डिग्री का अनुमान लगाने की अनुमति देता है, हालांकि यह निर्धारिती की तुलना में अधिक कठिन और अधिक महंगा है।
निर्धारक दृष्टिकोण नमूना संरचना के लिए यह मानता है कि सेट के तत्वों की पसंद या तो सुविधा के विचारों, या शोधकर्ता के समाधान या आकस्मिक समूहों के आधार पर की जाती है।
विचारों की सुविधा के लिएइसमें कुल के किसी भी तत्व को उनके साथ संपर्क से संपर्क करने की सादगी के आधार पर चुनने में शामिल है। इस विधि की अपूर्णता प्राप्त नमूने की कम प्रतिनिधित्व के कारण है, क्योंकि गैर-यादृच्छिक और अनुचित चयन के कारण शोधकर्ता के लिए कुल योग के आरामदायक तत्व पर्याप्त रूप से विशिष्ट प्रतिनिधि नहीं हो सकते हैं।
हालांकि, दूसरी तरफ, इस विधि द्वारा किए गए अध्ययन की सादगी, दक्षता और दक्षता ने अभ्यास में काफी व्यापक रूप से प्राप्त किया है और, सभी के ऊपर, जो प्रमुख समस्याओं को स्पष्ट करने के उद्देश्य से प्रारंभिक अध्ययनों का संचालन करते हैं।
नमूना निर्माण विधि आधारित शोधकर्ता के निर्णय परइसमें कुल तत्वों को चुनने में शामिल होता है, जो उनकी राय में, इसके विशिष्ट प्रतिनिधियों हैं। यह विधि पिछले एक की तुलना में अधिक सही है, क्योंकि यह अध्ययन के तहत प्रतिद्वंद्वी के लक्षण प्रतिनिधियों पर अभिविन्यास पर आधारित है, हालांकि इसके बारे में शोधकर्ताओं के व्यक्तिपरक प्रतिनिधित्व के आधार पर चुना गया है।
के आधार पर नमूनाकरण की विधि आकस्मिक मानकोंइसमें कुल प्राप्त कुल की विशेषताओं के अनुसार कुल के लक्षण तत्वों को चुनने में शामिल होता है। इन विशेषताओं को प्रारंभिक अध्ययन आयोजित करके प्राप्त किया जा सकता है और पिछली विधि के विपरीत, एक व्यक्तिपरक प्रकृति सहन नहीं करते हैं। इसलिए, यह विधि अधिक परिपूर्ण है, यह आपको संभावित रूप से कम निगरानी लागत के साथ संभाव्य नमूने की तुलना में कम प्रतिनिधि के चुनिंदा सेट प्राप्त करने की अनुमति देती है।
नमूना संरचना का चयन (इसके गठन के लिए दृष्टिकोण, संरचनात्मक नमूने के संभाव्य या रोलिंग गठन का प्रकार), शोधकर्ता को वॉल्यूम निर्धारित करना होगा, यानी। चुनिंदा कुल तत्वों की संख्या।
नमूनाकरण जानकारी की सटीकता निर्धारित करता हैइसके शोध के परिणामस्वरूप, साथ ही अनुसंधान करने के लिए आवश्यक लागत भी प्राप्त की गई। नमूना का आकार निर्भर करता है समरूपता या वस्तुओं की किस्मों के स्तर से अध्ययन किया गया।
नमूना का आकार जितना अधिक होगा, इसकी सटीकता और इसके सर्वेक्षण के लिए अधिक लागत अधिक होगी। नमूना संरचना के संभावित दृष्टिकोण के साथ, इसकी मात्रा को अपनी सटीकता के लिए निर्दिष्ट आवश्यकताओं के आधार पर प्रसिद्ध सांख्यिकीय सूत्रों का उपयोग करके निर्धारित किया जा सकता है।
अभ्यास में, नमूने को परिभाषित करने के लिए कई दृष्टिकोणों का उपयोग किया जाता है:
1. मनमानी दृष्टिकोण "अंगूठे के नियम" के उपयोग के आधार पर। उदाहरण के लिए, यह आवश्यक नहीं है कि सटीक परिणाम प्राप्त करने के लिए नमूना कुलता का 5% होना चाहिए। यह दृष्टिकोण सरल और प्रदर्शन करने में आसान है, लेकिन प्राप्त परिणामों की सटीकता स्थापित करना संभव नहीं है। पर्याप्त रूप से बड़ी कुलता के साथ, यह भी बहुत महंगा हो सकता है।
नमूना का आकार कुछ पूर्व निर्धारित परिस्थितियों के आधार पर स्थापित किया जा सकता है। उदाहरण के लिए, विपणन अनुसंधान के ग्राहक को पता है कि जनता की राय का अध्ययन करते समय, नमूना आमतौर पर 1000-1200 लोग होते हैं, इसलिए उन्होंने शोधकर्ता को इस आंकड़े का पालन करने की सिफारिश की। यदि कुछ बाजारों पर वार्षिक अध्ययन आयोजित किए जाते हैं, तो प्रत्येक वर्ष में यह एक ही मात्रा के नमूने का उपयोग करता है। पहले दृष्टिकोण के विपरीत, नमूना मात्रा निर्धारित करने के लिए यहां एक प्रसिद्ध तर्क का उपयोग किया जाता है, हालांकि, बहुत कमजोर है।
उदाहरण के लिए, कुछ अध्ययनों का संचालन करते समय, सार्वजनिक राय का अध्ययन करते समय सटीकता की आवश्यकता हो सकती है, और जनता की राय का अध्ययन करते समय कुल मिलाकर कुल मिलाकर कई गुना कम हो सकती है। इस प्रकार, यह दृष्टिकोण वर्तमान परिस्थितियों को ध्यान में रखता नहीं है और काफी महंगा हो सकता है।
कुछ मामलों में, मुख्य तर्क के रूप में, नमूना मात्रा निर्धारित करते समय, सर्वेक्षण की लागत का उपयोग किया जाता है। इस प्रकार, विपणन अनुसंधान का बजट कुछ सर्वेक्षणों के लिए प्रदान करता है जिन्हें पार नहीं किया जा सकता है। जाहिर है, प्राप्त जानकारी का मूल्य ध्यान में नहीं लिया जाता है। हालांकि, कुछ मामलों में, एक छोटा सा नमूना काफी सटीक परिणाम दे सकता है।
यह ध्यान में रखते हुए उचित रूप से नहीं है, लेकिन सर्वेक्षण किए गए सर्वेक्षणों के परिणामस्वरूप प्राप्त जानकारी की उपयोगिता के संबंध में। ग्राहक और शोधकर्ता को विभिन्न नमूना वॉल्यूम्स और डेटा संग्रह विधियों, लागतों, अन्य कारकों को ध्यान में रखते हुए विचार करना चाहिए
2. एक मान्य त्रुटि के गोपनीय अंतराल के स्तर पर नमूना का आकार, जैसा कि पहले से ही उल्लेख किया गया है, अंतिम सामान्यीकरण की शीघ्र सटीकता द्वारा दिया गया है: अनुमानित से अनुमानित। हालांकि, किसी भी सांख्यिकीय त्रुटियों की प्रकृति से जुड़े तथाकथित यादृच्छिक त्रुटियों को ध्यान में रखते हुए हैं। उन्हें संभाव्य नमूनों की प्रतिनिधित्व की त्रुटियों के रूप में गणना की जाती है।
V.I. Paniotto 5 प्रतिशत त्रुटि (तालिका 4.2) की अनुमतियों के साथ प्रतिनिधि नमूने की निम्नलिखित गणनाओं का हवाला देता है।
तालिका 4.2।
गणना नमूना तालिका
100,000 से अधिक नमूने के संयोजन के लिए 400 इकाइयां हैं। अगर मैं एक ही लेखक की गणना के अनुसार 5 हजार से अधिक संख्या के सामान्य सेट को ध्यान में रखता हूं, तो आप इसकी मात्रा के आधार पर नमूना की वास्तविक त्रुटि के मान निर्दिष्ट कर सकते हैं, जो बहुत है हमारे लिए महत्वपूर्ण है, याद रखना कि वैध त्रुटि का मूल्य उद्देश्य अनुसंधान पर निर्भर करता है और वैकल्पिक 5 प्रतिशत स्तर तक पहुंचना चाहिए।
तालिका 4.3।
गणना तालिका
|
नमूनाकरण, यदि सामान्य कुल 5000 | ||||||||
|
इस नमूना मात्रा में वास्तविक त्रुटि,% |
यादृच्छिक, व्यवस्थित त्रुटियों के साथ संभव है। वे एक चुनिंदा परीक्षा के संगठन पर निर्भर करते हैं। ये चुनिंदा पैरामीटर के ध्रुवों में से एक की ओर सैंपलिंग ऑफसेट की एक किस्म है।
3. सांख्यिकीय विश्लेषण के आधार पर नमूनाकरण । यह दृष्टिकोण प्राप्त परिणामों की विश्वसनीयता और विश्वसनीयता के लिए कुछ आवश्यकताओं के आधार पर न्यूनतम नमूनाकरण निर्धारित करने पर आधारित है। इसका उपयोग फर्श, आयु, शिक्षा के स्तर आदि पर चयन के हिस्से के रूप में किए गए व्यक्तिगत उपसमूहों के लिए प्राप्त परिणामों के विश्लेषण में भी किया जाता है। व्यक्तिगत उपसमूहों के परिणामों की विश्वसनीयता और सटीकता के लिए आवश्यकताएं पूरी तरह से नमूने के आकार के लिए कुछ आवश्यकताओं को निर्देशित करती हैं।
नमूना मात्रा निर्धारित करने के लिए सबसे सैद्धांतिक रूप से प्रमाणित और सही दृष्टिकोण विश्वसनीय अंतराल की गणना पर आधारित है। भिन्नता की अवधारणा एक निश्चित प्रश्न के उत्तरदाताओं के गलत (समान) प्रतिक्रियाओं की परिमाण की विशेषता है। एक और सख्त योजना में, किसी सेट में किसी भी साइन के मानों की भिन्नता को इसी अवधि या समय में इस सेट की विभिन्न इकाइयों से अपने मूल्यों में अंतर कहा जाता है। सर्वेक्षण प्रश्नों के लिए प्रतिक्रिया आमतौर पर वितरण वक्र (चित्र 4.1) के रूप में दर्शाया जाता है। उच्च समानता के साथ, उत्तर कम भिन्नताओं (संकीर्ण वितरण वक्र) के बारे में बात कर रहे हैं और कम समानता समानताएं - उच्च भिन्नता (विस्तृत वितरण वक्र) के बारे में।
भिन्नता के एक उपाय के रूप में, आमतौर पर औसत वर्गबद्ध विचलन आमतौर पर लिया जाता है, जो प्रत्येक प्रतिवादी के औसत मूल्यांकन से औसत दूरी को एक निश्चित प्रश्न के लिए दर्शाता है।
छोटी भिन्नता
उच्च भिन्नता
अंजीर। 4.1। भिन्नता और वितरण घटता
चूंकि सभी विपणन समाधान अनिश्चितता में स्वीकार किए जाते हैं, इसलिए इस परिस्थिति को नमूना के आकार को निर्धारित करते समय ध्यान में रखना उचित है। चूंकि एक संकीर्ण में एक सेट के लिए अध्ययन मूल्यों की परिभाषा चुनिंदा आंकड़ों के आधार पर किया जाता है, सीमा (आत्मविश्वास अंतराल) को सेट किया जाना चाहिए, जो पूरी तरह से एक कुशलता के लिए अनुमानित होने की उम्मीद है, और उनकी परिभाषा की त्रुटि।
आत्मविश्वास अंतराल सीमा है, जो चरम बिंदु कुछ प्रश्नों के कुछ उत्तरों के एक निश्चित प्रतिशत से मेल खाता है। आत्मविश्वास अंतराल सामान्य जनसंख्या में अध्ययन विशेषता के औसत वर्गिक विचलन के साथ निकटता से जुड़ा हुआ है: जितना अधिक, उत्तर के एक निश्चित प्रतिशत को शामिल करने के लिए अधिक व्यापक आत्मविश्वास अंतराल होना चाहिए।
आत्मविश्वास अंतराल, 95%, या 99%, विपणन अनुसंधान आयोजित करते समय मानक है। कोई भी फर्म कई नमूने बनाकर विपणन अनुसंधान आयोजित नहीं करता है। और गणितीय आंकड़े चुनिंदा वितरण के बारे में कुछ जानकारी प्राप्त करना संभव बनाता है, जो एक नमूने की विविधताओं पर केवल डेटा का मालिक है।
मूल्यांकन के मूल्यांकन के संकेतक, पूरी तरह से एक सेट के लिए सत्य, मूल्यांकन से एक सामान्य नमूना होने की उम्मीद है, एक मध्यम वर्गीय त्रुटि है। इसके अलावा, अधिक नमूनाकरण, त्रुटि छोटी है। भिन्नता का उच्च मूल्य त्रुटि के उच्च मूल्य और इसके विपरीत निर्धारित करता है।
जब असाइन किए गए प्रश्न के लिए केवल दो विकल्प होते हैं, तो प्रतिशत (प्रतिशत माप का उपयोग किया जाता है) के रूप में व्यक्त किया जाता है, नमूना आकार निम्न सूत्र द्वारा निर्धारित किया जाता है:

जहां एन नमूना का आकार है; जेड सामान्यीकृत विचलन है, जो आत्मविश्वास के चुने हुए स्तर के आधार पर निर्धारित है; पी - नमूनाकरण के लिए भिन्नता मिली; जी - (100-पी); ई - अनुमेय त्रुटि।
एक निश्चित सेट के लिए भिन्नता के संकेतक को निर्धारित करने में, सबसे पहले, अध्ययन के प्रारंभिक गुणात्मक विश्लेषण का संचालन करने के लिए सलाह दी जाती है, सबसे पहले जनसांख्यिकीय, सामाजिक और अन्य संबंधों में कुल इकाइयों की समानता स्थापित करना शोधकर्ता के लिए ब्याज। एक पायलट अध्ययन करना संभव है, अतीत में किए गए इस तरह के अध्ययनों के परिणामों का उपयोग। परिवर्तनशीलता के प्रतिशत माप का उपयोग करते समय ध्यान में रखा जाता है कि पी \u003d 50% के लिए अधिकतम परिवर्तनशीलता हासिल की जाती है, जो सबसे खराब मामला है। इसके अलावा, यह सूचक मूल रूप से नमूना के आकार को प्रभावित नहीं करता है। नमूनाकरण की मात्रा पर ग्राहक के शोध की राय भी ध्यान में रखी जाती है।
औसत मूल्यों के उपयोग के आधार पर नमूना आकार को परिभाषित करना संभव है, और प्रतिशत मूल्यों को नहीं।

जहां एस एक द्वितीयक द्विघात विचलन है।
अभ्यास में, यदि नमूना गठित किया गया है और इसी तरह के सर्वेक्षण नहीं किए गए थे, तो एस ज्ञात नहीं है। इस मामले में, मानक विचलन के अंशों में ई की त्रुटि सेट करने की सलाह दी जाती है। गणनाित सूत्र परिवर्तित और निम्नलिखित रूप प्राप्त करता है:
 कहा पे
कहा पे  .
.
ऊपर बहुत बड़े आकार के योग के बारे में बातचीत हुई थी। हालांकि, कुछ मामलों में, कुल बड़ा नहीं है। आम तौर पर, यदि नमूना कुल के पांच प्रतिशत से कम है, तो कुल को बड़े पैमाने पर माना जाता है और उपर्युक्त नियमों के अनुसार गणना की जाती है। यदि नमूना का आकार कुल 5% से अधिक है, तो बाद वाला छोटा माना जाता है और उपरोक्त सूत्र को सुधार गुणांक द्वारा पेश किया जाता है।
इस मामले में नमूना आकार निम्नानुसार परिभाषित किया गया है:
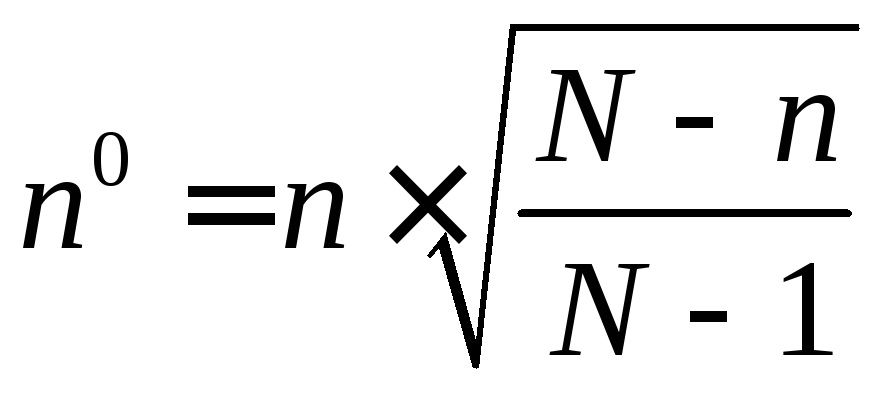 ,
,
जहां एन छोटे कुल के लिए नमूना का आकार है; एन 0 - उपरोक्त सूत्रों के अनुसार गणना नमूने का आकार; एन सामान्य आबादी की मात्रा है।
जाहिर है, छोटे नमूनों का उपयोग समय बचत और धन का कारण बन जाएगा।
नमूने के आकार की गणना के लिए उपरोक्त सूत्र इस धारणा पर आधारित हैं कि सभी नमूना गठन नियमों को देखा गया था और नमूना की एकमात्र त्रुटि इसकी मात्रा के कारण एक त्रुटि है। हालांकि, यह याद रखना चाहिए कि नमूना का आकार प्राप्त परिणामों की सटीकता निर्धारित करता है, लेकिन उनकी प्रतिनिधित्व नहीं है।
उत्तरार्द्ध नमूनाकरण की विधि द्वारा निर्धारित किया जाता है। नमूने के आकार की गणना के लिए सभी सूत्रों से पता चलता है कि सही संभाव्य नमूना प्रक्रियाओं का उपयोग करके प्रतिनिधित्व की गारंटी है।
वॉल्यूम, नमूना अध्ययन के विश्लेषणात्मक, उद्देश्यों द्वारा निर्धारित किया जाता है, और इसकी प्रतिनिधित्व कार्यक्रम की लक्ष्य स्थापना है। यह वह कार्यक्रम है जो नमूनाकरण के लिए आवश्यक सामान्य आबादी की छवि सेट करता है। चाहे वह सभी आबादी या उसके विशेष संरचनात्मक संरचनाएं होंगी, वस्तु के सभी तत्वों का अध्ययन किया जा रहा है या केवल मानदंडों के निर्दिष्ट कार्यक्रम के अनुसार आवंटित किया जा रहा है, सामान्य जनसंख्या ऑब्जेक्ट प्रोग्राम में परिभाषित सभी इकाइयां हैं।
नमूना संरचना के लिए एक निर्धारक दृष्टिकोण के दौरान, सामान्य रूप से, यह संभव नहीं है कि प्राप्त जानकारी की विश्वसनीयता के लिए निर्दिष्ट मानदंड के अनुसार इसकी मात्रा को सटीक रूप से निर्धारित करना संभव है। इस मामले में, नमूना का आकार अनुभवी रूप से निर्धारित किया जा सकता है। विदेशों में विपणन अनुसंधान की गतिविधि एक दिशानिर्देश के रूप में काम कर सकती है। इसलिए, खरीदारों की जांच करते समय, नमूना की उच्च सटीकता सुनिश्चित की जाती है, भले ही इसकी मात्रा पूरे सेट का 1% से अधिक न हो, मध्यम और बड़ी खुदरा फर्मों के ग्राहकों के लिए चुनाव आयोजित करते समय, उत्तरदाताओं की संख्या (नमूना मात्रा) आमतौर पर होती है 500 से 1000 लोगों में उतार-चढ़ाव।
प्राथमिक जानकारी एकत्र करने की विधि का चयन करने के लिए प्रक्रिया का मूल्य, और अध्ययन के वाद्ययंत्र यह है कि इस चयन के परिणामों को जानकारी की विश्वसनीयता और सटीकता दोनों को प्राप्त करने और अवधि, और इसकी उच्च लागत दोनों को परिभाषित किया गया है संग्रह।
योजना:
1. गणितीय आंकड़ों के कार्य।
2. नमूने के प्रकार।
3. नमूना पद्धतियां।
4. सांख्यिकीय नमूना वितरण।
5. अनुभवजन्य वितरण समारोह।
6. बहुभुज और हिस्टोग्राम।
7. विविध श्रृंखला की संख्यात्मक विशेषताएं।
8. वितरण मानकों के सांख्यिकीय अनुमान।
9. वितरण मानकों के अंतराल अनुमान।
1. कार्य और गणितीय आंकड़ों के तरीके
गणित सांख्यिकी - यह वैज्ञानिक और व्यावहारिक उद्देश्यों के लिए सांख्यिकीय अवलोकन डेटा के परिणामों को एकत्रित करने, विश्लेषण करने और संसाधित करने के तरीकों के लिए समर्पित गणित का एक वर्ग है।
इन वस्तुओं की विशेषता वाले कुछ गुणात्मक या मात्रात्मक सुविधा के सापेक्ष सजातीय वस्तुओं की कुलता का अध्ययन करने के लिए आवश्यक होने दें। उदाहरण के लिए, यदि भागों का हिस्सा है, तो भाग का मानक एक उच्च गुणवत्ता वाली सुविधा हो सकती है, और भाग का मात्रात्मक आकार मात्रात्मक हिस्सा है।
कभी-कभी एक ठोस अध्ययन किया जाता है, यानी वांछित सुविधा के सापेक्ष प्रत्येक वस्तु की जांच करें। व्यावहारिक रूप से, एक ठोस परीक्षा शायद ही कभी लागू होती है। उदाहरण के लिए, यदि कुटिलता में बड़ी संख्या में वस्तुएं होती हैं, तो यह ठोस परीक्षा करने के लिए शारीरिक रूप से असंभव है। यदि कोई ऑब्जेक्ट सर्वेक्षण अपने विनाश से जुड़ा हुआ है या बड़ी भौतिक लागत की आवश्यकता है, तो यह एक ठोस परीक्षा आयोजित करने के लिए समझ में नहीं आता है। ऐसे मामलों में, सीमित संख्या में ऑब्जेक्ट्स (चुनिंदा कुलता) को यादृच्छिक रूप से पूरे सेट से चुना जाता है और उनका शोषण किया जाता है।
गणितीय आंकड़ों का मुख्य कार्य उद्देश्य सेट के आधार पर चुनिंदा डेटा के पूरे संयोजन का अध्ययन करना है, यानी। कुल्ला के संभाव्य गुणों का अध्ययन: वितरण, संख्यात्मक विशेषताओं आदि का कानून अनिश्चितता की स्थितियों में प्रबंधन निर्णय लेने के लिए।
2. नमूने के प्रकार
सामान्य समग्र - यह उन वस्तुओं का एक संयोजन है जहां से नमूना किया जाता है।
चुनिंदा कुल (नमूना) - यह यादृच्छिक रूप से चयनित वस्तुओं का एक संयोजन है।
कुल मात्रा - यह इस कुटिलता की वस्तुओं की संख्या है। सामान्य आबादी की मात्रा इंगित की जाती हैएन, चुनिंदा - एन।
उदाहरण:
यदि 100 भागों के सर्वेक्षण के लिए 1000 भागों का चयन किया जाता है, तो सामान्य जनसंख्या की मात्राएन \u003d 1000, और नमूनाकरणn \u003d 100।
एकल नमूना आप दो तरीकों से कर सकते हैं: ऑब्जेक्ट का चयन करने के बाद और इसे ऊपर देखा गया है, इसे वापस किया जा सकता है या सामान्य आबादी में वापस नहीं किया जा सकता है। इसलिए नमूने बार-बार और पुनर्जीवित में विभाजित होते हैं।
दोहराया गया कॉल नमूनाजिस पर चयनित वस्तु (अगले चयन से पहले) सामान्य आबादी को वापस कर दी जाती है।
बंदीकॉल नमूनाजिस पर सामान्य कुल में चयनित वस्तु वापसी योग्य नहीं है।
अभ्यास में, वे आमतौर पर एक लाश-अप यादृच्छिक चयन का उपयोग करते हैं।
नमूना डेटा के लिए, साइन इन करने में रुचि रखने वाले सामान्य कुल योग के संकेत के बारे में आत्मविश्वास से न्याय करना संभव था, यह आवश्यक है कि नमूना वस्तुओं ने सही ढंग से इसका प्रतिनिधित्व किया था। नमूना सामान्य जनसंख्या के अनुपात का सही ढंग से प्रतिनिधित्व करना चाहिए। नमूना होना चाहिए प्रतिनिधि (प्रतिनिधि)।
बड़ी संख्या के कानून के आधार पर, यह तर्क दिया जा सकता है कि नमूना यादृच्छिक होने पर प्रतिनिधि होगा।
यदि सामान्य कुल की मात्रा काफी बड़ी है, और नमूना केवल इस कुलता का एक मामूली हिस्सा है, तो पुन: और प्रतिकूल नमूने के बीच का अंतर मिटा दिया जाता है; सीमित मामले में, जब एक अंतहीन सामान्य सेट पर विचार किया जाता है, और नमूना में एक सीमित मात्रा होती है, तो यह भेद गायब हो जाता है।
उदाहरण:
सांख्यिकीय तरीकों की मदद से अमेरिकी पत्रिका "साहित्यिक समीक्षा" में, 1 9 36 में अमेरिकी राष्ट्रपति के आने वाले चुनावों के नतीजे के संबंध में अनुमानों द्वारा एक अध्ययन आयोजित किया गया था। इस पद के लिए आवेदक एफडी थे। रूजवेल्ट और ए एम लैंडन। टेलीफोन ग्राहकों की निर्देशिकाओं को अध्ययन किए गए अमेरिकियों के सामान्य सेट के लिए एक स्रोत के रूप में लिया गया था। इनमें से 4 मिलियन पते यादृच्छिक रूप से चुने गए थे।, जिसके लिए पत्रिका के संपादकों ने राष्ट्रपति पद के लिए उम्मीदवारों के लिए अपना दृष्टिकोण व्यक्त करने के अनुरोध के साथ पोस्टकार्ड भेजा। सर्वेक्षण के परिणामों को संसाधित करते हुए, पत्रिका ने एक सामाजिक भविष्यवाणी प्रकाशित की कि लैंडन आगामी चुनावों पर एक बड़े लाभ के साथ जीत जाएगा। और ... मैं गलत था: रूजवेल्ट ने जीत हासिल की।
इस उदाहरण को एक अपरिवर्तनीय नमूने के उदाहरण के रूप में देखा जा सकता है। तथ्य यह है कि संयुक्त राज्य अमेरिका में बीसवीं शताब्दी के पहले छमाही में, फोनों में केवल आबादी के एक हिस्से का एक हिस्सा था जिसने लैंडन के विचारों का समर्थन किया।
3. चयन के तरीके
व्यावहारिक रूप से, चयन के विभिन्न तरीकों को लागू किया जाता है, जिसे 2 प्रकारों में विभाजित किया जा सकता है:
1. चयन को सामान्य जनसंख्या के विघटन (ए) की आवश्यकता नहीं होती है सरल यादृच्छिक लापरवाह; बी) सरल यादृच्छिक दोहराया).
2. वह चयन जिस पर सामान्य कुल भागों में विभाजित होता है। (लेकिन अ) विशिष्ट चयन; बी) यांत्रिक चयन; में) धारावाहिक चयन).
बस यादृच्छिक कहा जाता है चयनजिसमें पूरी सामान्य आबादी (यादृच्छिक रूप से) में से एक के अनुसार वस्तुओं को पुनः प्राप्त किया जाता है।
ठेठ कॉल चयनजिसमें पूरी सामान्य आबादी से वस्तुओं का चयन नहीं किया जाता है, लेकिन इसके प्रत्येक "विशिष्ट" भाग से। उदाहरण के लिए, यदि भाग कई मशीनों पर किया जाता है, तो चयन सभी मशीनों द्वारा उत्पादित भागों की पूरी कुलता से और प्रत्येक मशीन के उत्पादों से अलग से उत्पन्न नहीं होता है। जैसा कि इस तरह के चयन का उपयोग किया जाता है जब परीक्षण संकेतक सामान्य जनसंख्या के विभिन्न "विशिष्ट" भागों में उल्लेखनीय रूप से भिन्न होते हैं।
यांत्रिककॉल चयन, जिसमें सामान्य सेट "मैकेनिकल" को इतने सारे समूहों में विभाजित किया जाता है क्योंकि वस्तुओं को नमूना में शामिल किया जाना चाहिए, और प्रत्येक समूह से एक वस्तु ली जाती है। उदाहरण के लिए, यदि आपको मशीन द्वारा किए गए हिस्सों के 20% चुनने की आवश्यकता है, तो प्रत्येक 5 वां भाग लिया जाता है; यदि आप 5% विवरण चुनना चाहते हैं, तो प्रत्येक 20 वां आदि। कभी-कभी ऐसा चयन नमूना की प्रतिनिधित्व प्रदान नहीं कर सकता है (यदि प्रत्येक 20 अंत में डिस्चार्ज करने योग्य रोलर चुना जाता है, और चयन के तुरंत बाद, कटर को बदल दिया जाता है, सभी रोलर्स को ब्लॉटेड कटर द्वारा कब्जा कर लिया जाता है।
धारावाहिक कॉल चयनसामान्य आबादी से वस्तुओं का चयन किया जाता है, एक-एक करके नहीं, लेकिन "श्रृंखला", जो एक ठोस परीक्षा के अधीन होती है। उदाहरण के लिए, यदि उत्पादों को मशीन टूल्स का एक बड़ा समूह बनाया जाता है, तो केवल एकाधिक मशीनों को ठोस परीक्षा के अधीन किया जाता है।
अभ्यास में, एक संयुक्त चयन अक्सर उपयोग किया जाता है, जो उपरोक्त विधियों को जोड़ता है।
4. आंकड़ा नमूना वितरण
सामान्य जनसंख्या से निकाले गए एक नमूना को दें, और मूल्य x 1- एक बार, x 2 -n 2 बार, ... एक्स के - एन के बार। n \u003d एन 1 + एन 2 + ... + एन के नमूना का आकार है। मनाया मानबुला हुआ विकल्प, और बढ़ते क्रम में दर्ज विकल्प का अनुक्रम निकटता। नंबरबुला हुआ आवृत्तियों (पूर्ण आवृत्तियों), और नमूने के आकार के लिए उनके संबंध- सापेक्ष आवृत्तियों या सांख्यिकीय संभावनाएं।
यदि संस्करण की मात्रा बड़ी या नमूना एक निरंतर सामान्य सेट से बनाई जाती है, तो भिन्नता श्रृंखला को अलग-अलग बिंदु मूल्यों द्वारा संकलित नहीं किया जाता है, बल्कि सामान्य आबादी के मूल्यों के अंतराल पर। इस विविधता श्रृंखला को बुलाया जाता है मध्यान्तर।अंतराल की लंबाई बराबर होनी चाहिए।
आंकड़ा नमूना वितरण विकल्प और संबंधित आवृत्तियों या सापेक्ष आवृत्तियों की एक सूची कहा जाता है।
सांख्यिकीय वितरण को अंतराल के अनुक्रम के रूप में भी निर्दिष्ट किया जा सकता है और उनकी आवृत्तियों के अनुरूप (मूल्यों के इस अंतराल में आवृत्ति मात्रा)
आवृत्तियों की बिंदु भिन्नता सीमा तालिका द्वारा प्रस्तुत की जा सकती है:
| एक्स I. |
एक्स 1 |
एक्स 2 |
… |
एक्स के। |
| एन मैं |
एन 1 |
N 2। |
… |
एन के। |
इसी प्रकार, आप सापेक्ष आवृत्तियों की एक बिंदु भिन्नता श्रृंखला जमा कर सकते हैं।
तथा:
उदाहरण:
कुछ पाठ एक्स में अक्षरों की संख्या 1000 के बराबर थी। "मैं", दूसरा अक्षर "और", तीसरा और अक्षर "ए", चौथा- "यू" की पहली बैठक। फिर अक्षर "ओ", "ई", "यू", "ई", "एस"।
हम उन स्थानों को पीते हैं जो वे क्रमशः वर्णमाला में कब्जा करते हैं, हमारे पास है: 33, 10, 1, 32, 16, 6, 21, 31, 29।
इन संख्याओं को ऑर्डर करने के बाद, आरोही, हम एक विविधता श्रृंखला प्राप्त करते हैं: 1, 6, 10, 16, 21, 2 9, 31, 32, 33।
पाठ में अक्षरों की उपस्थिति की आवृत्तियों: "ए" - 75, "ई" -87, "और" - 75, "ओ" - 110, "वाई" - 25, "एस" - 8, "ई" - 3, "" - 7, "मैं" - 22।
आइए एक बिंदु भिन्नता आवृत्ति रेंज बनाएं:
उदाहरण:
नमूना मात्रा की आवृत्तियों का वितरण सेट हैn \u003d 20।
सापेक्ष आवृत्तियों की एक बिंदु भिन्नता रेंज बनाओ।
| एक्स I. |
2 |
6 |
12 |
| एन मैं |
3 |
10 |
7 |
फेसला:
सापेक्ष आवृत्तियों को खोजें:
| एक्स I. |
2 |
6 |
12 |
| डब्ल्यू मैं |
0,15 |
0,5 |
0,35 |
एक अंतराल वितरण का निर्माण करते समय, अंतराल की संख्या या प्रत्येक अंतराल की परिमाण के नियम होते हैं। यहां मानदंड इष्टतम अनुपात है: अंतराल की संख्या में वृद्धि के साथ, प्रतिनिधित्व में सुधार हुआ है, लेकिन उनके प्रसंस्करण में डेटा और समय की मात्रा बढ़ जाती है। अंतर x अधिकतम - x min सबसे बड़े और सबसे छोटे मूल्यों के बीच कहा जाता है पहिया नमूने।
अंतराल की संख्या को गिनने के लिएक। आमतौर पर गुप्तता के अनुभवजन्य सूत्र का उपयोग किया जाता है (निकटतम सुविधाजनक इरादे के लिए घुमावदार):के \u003d 1 + 3.322 एलजी एन।
तदनुसार, प्रत्येक अंतराल का मूल्यएच सूत्र द्वारा गणना की जा सकती है:
5. अनुभवजन्य वितरण समारोह
सामान्य जनसंख्या से कुछ नमूने पर विचार करें। इसे एक्स की मात्रात्मक सुविधा की आवृत्तियों के सांख्यिकीय वितरण को ज्ञात करने दें। हम नोटेशन पेश करते हैं: एन एक्स- उन टिप्पणियों की संख्या जिसके तहत एक्स से कम फीचर का अर्थ मनाया गया था;एन - अवलोकनों की कुल संख्या (नमूनाकरण)। सापेक्ष घटना आवृत्ति एक्स<х равна एन एक्स / एन। यदि x बदलता है, तो सापेक्ष आवृत्ति परिवर्तन, यानी सापेक्ष आवृत्तिn x / n- एक्स से एक समारोह है। चूंकि यह अनुभवजन्य है, इसे अनुभवजन्य कहा जाता है।
अनुभवजन्य वितरण समारोह (नमूना समारोह) कॉल समारोहप्रत्येक एक्स रिश्तेदार घटना आवृत्ति एक्स के लिए परिभाषित<х.
जहां संख्या छोटी एक्स है,
एन - नमूना मात्रा।
अनुभवजन्य नमूना वितरण समारोह के विपरीत, सामान्य आबादी के वितरण एफ (एक्स) का कार्य कहा जाता है सैद्धांतिक वितरण समारोह.
अनुभवजन्य और सैद्धांतिक वितरण कार्यों के बीच का अंतर यह है कि सैद्धांतिक कार्य f (x) घटना x की संभावना को निर्धारित करता है
इसलिए सामान्य आबादी के वितरण के सैद्धांतिक (अभिन्न) कार्य के अनुमानित प्रतिनिधित्व के लिए अनुभवजन्य नमूना वितरण कार्य का उपयोग करने की सलाह दी जाती है।
F * (x)इसमें सभी गुण हैंF (x)।
1. मूल्य F * (x)अंतराल से संबंधित हैं।
2. एफ * (एक्स) - गैर-घटती कार्य।
3. यदि - सबसे छोटा संस्करण, tf * (x) \u003d 0, x के साथ < x 1; यदि एक्स के सबसे बड़ा संस्करण है, तो F * (x) \u003d 1, x\u003e x k पर।
वे। F * (x)f (x) का अनुमान लगाने के लिए उपयोग किया जाता है।
यदि नमूना भिन्नता पक्ष द्वारा निर्धारित किया जाता है, तो अनुभवजन्य कार्य में फॉर्म होता है:
एक अनुभवजन्य समारोह का ग्राफ संचयी कहा जाता है।
उदाहरण:
इस नमूना वितरण पर एक अनुभवजन्य कार्य का निर्माण करें।
फेसला:
नमूनाकरण वॉल्यूम एन \u003d 12 + 18 +30 \u003d 60. सबसे छोटा विकल्प 2, यानी। एक्स पर। <
2. घटना एक्स।<6,
(x 1
= 2) наблюдалось 12 раз, т.е. F * (x) \u003d 12/60 \u003d 0.2दो पर। <
एक्स। <
6. घटना एच।<10, (x 1 =2, x 2 = 6) наблюдалось 12 + 18 = 30 раз, т.е.F*(x)=30/60=0,5
при 6 <
एक्स। <
10. क्योंकि x \u003d 10 सबसे बड़ा विकल्प F * (x) \u003d 1x\u003e 10 पर। वांछित अनुभवजन्य समारोह में फॉर्म है:
Cumulat:
Cumulat ग्राफिक रूप से प्रस्तुत की गई जानकारी को समझना संभव बनाता है, उदाहरण के लिए, प्रश्नों का उत्तर देने के लिए: "अवलोकनों की संख्या निर्धारित करें, जिसमें वर्ण मूल्य 6 से कम था या 6 से कम नहीं 6. F * (6) \u003d 0.2 "फिर अवलोकन की संख्या जिसमें मनाई गई सुविधा का मूल्य 6 के बराबर 0.2 * थाएन \u003d 0.2 * 60 \u003d 12. अवलोकन की संख्या जिसमें देखी गई सुविधा का मूल्य कम से कम 6 बराबर था (1-0.2) *n \u003d 0.8 * 60 \u003d 48।
यदि अंतराल भिन्नताएं निर्धारित की जाती हैं, तो वितरण के अनुभवजन्य कार्य के संकलन के लिए, मध्य-अंतराल पाए जाते हैं और अनुभवजन्य वितरण समारोह एक बिंदु भिन्नता श्रृंखला द्वारा प्राप्त किया जाता है।
6. बहुभुज और हिस्टोग्राम
स्पष्टता के लिए सांख्यिकीय वितरण के विभिन्न ग्राफ बनाएं: बहुपद और हिस्टोग्राम
बहुभुज यह एक टूटा हुआ है, जिनमें से कनेक्ट अंक (x 1; n 1), (x 2; n 2), ..., (x k; n k), जहां - विकल्प - संबंधित आवृत्तियों।
बहुभुज सापेक्ष आवृत्ति यह एक टूटा हुआ है, जिनमें से कुछ अंक (x 1; डब्ल्यू 1), (x 2; डब्ल्यू 2), ..., (xk; wk), जहां i-vintage, w i - संबंधित आवृत्तियों संबंधित उनको।
उदाहरण:
इस नमूना वितरण पर बहुपद सापेक्ष आवृत्तियों का निर्माण करें:
फेसला:
एक निरंतर सुविधा के मामले में, एक हिस्टोग्राम बनाने की सलाह दी जाती है, जिसके लिए अंतराल जिसमें सभी मनाए गए फीचर मानों को लंबाई एच के कई आंशिक अंतराल में विभाजित किया जाता है और प्रत्येक आंशिक अंतराल एन I के लिए पाया जाता है - आई-सेल अंतराल में आवृत्ति आवृत्तियों की राशि। (उदाहरण के लिए, मानव या वजन वृद्धि को मापते समय, हम निरंतर संकेत से निपट रहे हैं)।
हिस्टोग्राम आवृत्ति यह एक कदम वाला आंकड़ा है जिसमें आयताकार होते हैं, जिनके आधार लंबाई एच के साथ आंशिक अंतराल के रूप में कार्य करते हैं, और ऊंचाई अनुपात (आवृत्ति घनत्व) के बराबर होती है।
क्षेत्र i-TO I-TH अंतराल के आवृत्ति संस्करण की राशि के बराबर आंशिक आयताकार, यानी आवृत्ति हिस्टोग्राम का क्षेत्र सभी आवृत्तियों के योग के बराबर है, यानी। नमूनाकरण।
उदाहरण:
पावर ग्रिड में वोल्टेज परिवर्तन (वोल्ट में) के परिणाम दिए गए हैं। एक विविधता श्रृंखला बनाएं, एक बहुभुज और आवृत्ति हिस्टोग्राम बनाएं, यदि वोल्टेज मूल्य निम्नानुसार हैं: 227, 215, 230, 232, 222, 220, 22, 22, 212, 220, 228, 222, 217, 220 ।
फेसला:
चलो एक विविधता श्रृंखला बनाते हैं। हमारे पास n \u003d 20, x min \u003d 212, x अधिकतम \u003d 232 है।
अंतराल की संख्या को गिनने के लिए यूनिवर्स फॉर्मूला को लागू करें।
आवृत्तियों की अंतराल भिन्नता सीमा का रूप होता है:
|
|
आवृत्ति घनत्व |
|
212-21 6 |
0,75 |
|
|
21 6-22 0 |
0,75 |
|
|
220-224 |
1,75 |
|
|
224-228 |
||
|
228-232 |
0,75 |
हम आवृत्ति हिस्टोग्राम का निर्माण करते हैं:
हम एक आवृत्ति बहुभुज का निर्माण करते हैं, पूर्व-मध्य अंतराल को ढूंढते हैं:
सापेक्ष आवृत्तियों का हिस्टोग्राम आयताकार से युक्त एक चरणबद्ध आकृति को कॉल करें, जिनके आधार लंबाई एच के साथ आंशिक अंतराल हैं, और ऊंचाई अनुपात डब्ल्यू के बराबर है मैं।/ एच (सापेक्ष आवृत्ति घनत्व)।
क्षेत्र मैं आंशिक आयताकार बराबर आवृत्ति विकल्प जो I - C में गिर गया। वे। सापेक्ष आवृत्ति हिस्टोग्राम का क्षेत्र सभी सापेक्ष आवृत्तियों के योग के बराबर है, यानी एकता।
7. विविधता श्रृंखला की संख्यात्मक विशेषताएं
सामान्य और चुनिंदा सेट की मुख्य विशेषताओं पर विचार करें।
आमइसे सामान्य आबादी के संकेत के औसत अंकगणितीय मूल्यों कहा जाता है।
विभिन्न मूल्यों के लिए x 1, x 2, x 3, ..., x n। वॉल्यूम एन की सामान्य आबादी का संकेत हमारे पास है:
यदि चरित्र मानों में संबंधित आवृत्तियों n 1 + n 2 + ... + n k \u003d n, तो
चुनिंदा मध्यइसे नमूना सेट के संकेत के औसत अंकगणितीय मान कहा जाता है।
यदि चरित्र मानों में संबंधित आवृत्तियों n 1 + n 2 + ... + n k \u003d n, तो
उदाहरण:
नमूना के लिए चुनिंदा औसत की गणना करें: x 1 \u003d 51.12; x 2 \u003d 51.07; x 3 \u003d 52.95; x 4 \u003d 52.93; x 5 \u003d 51,1; x 6 \u003d 52.98; x 7 \u003d 52.29; x 8 \u003d 51.23; x 9 \u003d 51.07; x 10 \u003d 51.04।
फेसला:
सामान्य फैलावइसे सामान्य औसत से सामान्य आबादी की विशेषता के मूल्यों के विचलन के अंकगणितीय वर्ग कहा जाता है।
विभिन्न मूल्यों के लिए x 1, x 2, x 3, ..., x n, वॉल्यूम एन के सामान्य सेट का संकेत हमारे पास है:
यदि चरित्र मानों में संबंधित आवृत्तियों n 1 + n 2 + ... + n k \u003d n, तो
सामान्य रेडियाट्रल विचलन (मानक) सामान्य फैलाव से एक वर्ग रूट को कॉल करें
चुनिंदा फैलाव इसे औसत मूल्य से सुविधा के मनाए गए मूल्यों के विचलन के औसत अंकगणितीय वर्ग कहा जाता है।
विभिन्न मूल्यों के लिए x 1, x 2, x 3, ..., x n, वॉल्यूम एन के चयनात्मक सेट का एक संकेत हमारे पास है:
यदि चरित्र मानों में संबंधित आवृत्तियों n 1 + n 2 + ... + n k \u003d n, तो
चुनिंदा आरएमएस विचलन (मानक) इसे चुनिंदा फैलाव से एक वर्ग रूट कहा जाता है।
उदाहरण:
चुनिंदा सेट सेट वितरण तालिका। एक चुनिंदा फैलाव का पता लगाएं।
फेसला:
प्रमेय: फैलाव संकेतों के मध्य वर्गों और कुल औसत के वर्ग में अंतर के बराबर है।
उदाहरण:
इस वितरण पर फैलाव पाएं।
फेसला:
8. वितरण मानकों के सांख्यिकीय अनुमान
कुछ नमूने पर सामान्य कुल परीक्षा दें। इस मामले में, केवल अज्ञात पैरामीटर क्यू का अनुमानित मूल्य प्राप्त किया जा सकता है, जो मूल्यांकन के रूप में कार्य करता है। जाहिर है, अनुमान एक नमूना से दूसरे में भिन्न हो सकते हैं।
सांख्यिकीय आकलनक्यू * सैद्धांतिक वितरण का अज्ञात पैरामीटर मनाए गए नमूना मानों के आधार पर फ़ंक्शन एफ है। नमूना पर अज्ञात मानकों के सांख्यिकीय मूल्यांकन का कार्य सांख्यिकीय अवलोकनों से उपलब्ध डेटा से ऐसे फ़ंक्शन का निर्माण करना है, जो वास्तविक के सबसे सटीक अनुमानित मान प्रदान करेगा, जो शोधकर्ता के लिए ज्ञात नहीं है, इनमें से मूल्य पैरामीटर।
सांख्यिकीय अनुमान उन्हें (संख्या या अंतराल द्वारा) प्रदान करने की विधि के आधार पर बिंदु और अंतराल में विभाजित होते हैं।
प्वाइंट कॉल सांख्यिकीय मूल्यांकन सैद्धांतिक वितरण का पैरामीटर क्यू पैरामीटर q * \u003d f (x 1, x 2, ..., x n) के एक मान द्वारा निर्धारित किया जाता है, जहांएक्स 1, एक्स 2, ..., एक्स एन- कुछ नमूने के मात्रात्मक चिह्न x पर अनुभवजन्य अवलोकनों के परिणाम।
विभिन्न नमूनों में प्राप्त पैरामीटर के इस तरह के अनुमान अक्सर एक दूसरे से अलग होते हैं। पूर्ण अंतर / प्रश्न * -Q / कॉल त्रुटि नमूनाकरण (अनुमान)।
आंकड़ों के अनुमानित मानकों के विश्वसनीय परिणाम देने के लिए, यह आवश्यक है कि वे अस्थिर, कुशल और सुसंगत हैं।
बिंदु लागत, जिसका गणितीय अपेक्षा बराबर है (बराबर नहीं) अनुमानित पैरामीटर कहा जाता है निर्बाध (स्थानांतरित)। M (q *) \u003d q.
अंतर एम ( Q *) - q कहा जाता है विस्थापन या व्यवस्थित त्रुटि। असंबंधित अनुमानों के लिए, व्यवस्थित त्रुटि 0 है।
प्रभावी मूल्यांकन क्यू *, जो किसी दिए गए नमूने एन के साथ, सबसे छोटा संभव फैलाव है: डीन्यूनतम (एन \u003d कॉन्स)। प्रभावी मूल्यांकन में अन्य अस्थिर और अमीर अनुमानों की तुलना में सबसे छोटी तात्करण है।
धनी इस तरह के सांख्यिकीय कहा जाता है मूल्यांकन क्यू *, जो एन के लिएवह अनुमानित पैरामीटर की संभावना के लिए प्रयास करती हैप्र । नमूनाकरण में वृद्धि के साथएन मूल्यांकन पैरामीटर के वास्तविक मूल्य की संभावना की तरह खोजता हैप्र
स्थिरता की आवश्यकता बड़ी संख्या के कानून के अनुरूप है: अध्ययन के तहत वस्तु के बारे में अधिक स्रोत जानकारी, परिणाम अधिक सटीक है। यदि नमूना आकार छोटा है, तो पैरामीटर का बिंदु अनुमान गंभीर त्रुटियों का कारण बन सकता है।
किसी को नमूनाकरण (मात्रा)एन) एक आदेशित सेट के रूप में माना जा सकता हैएक्स 1, एक्स 2, ..., एक्स एनस्वतंत्र समान रूप से वितरित यादृच्छिक चर।
विभिन्न मात्रा नमूने के लिए चुनिंदा औसतएन एक ही सामान्य आबादी से अलग होगा। यही है, चुनिंदा औसत को यादृच्छिक राशि के रूप में माना जा सकता है, और इसलिए, हम नमूना माध्यम और इसकी संख्यात्मक विशेषताओं के वितरण के बारे में बात कर सकते हैं।
चुनिंदा औसत सांख्यिकीय अनुमानों के लिए अतिरंजित सभी आवश्यकताओं को संतुष्ट करता है, यानी सामान्य औसत के अविश्वसनीय, कुशल और अमीर मूल्यांकन देता है।
आप इसे साबित कर सकते हैं। इस प्रकार, चुनिंदा फैलाव सामान्य फैलाव का पक्षपातपूर्ण अनुमान है, जो इसे कम मूल्य देता है। यही है, एक छोटे नमूने के साथ, यह एक व्यवस्थित त्रुटि देगा। अभूतपूर्व के लिए, अमीर मूल्यांकन राशि लेने के लिए पर्याप्त हैजिसे सही फैलाव कहा जाता है। अर्थात्
व्यावहारिक रूप से, सामान्य फैलाव का अनुमान लगाने के लिए एक सही फैलाव का उपयोग किया जाता है।एन < 30. अन्य मामलों में (n\u003e 30) से विचलन दुर्भाग्य से। इसलिए, बड़े मूल्यों परएन विस्थापन त्रुटि की उपेक्षा की जा सकती है।
आप यह भी साबित कर सकते हैं कि सापेक्ष आवृत्तिएन I / N संभावना का एक अनलॉक और अमीर मूल्यांकन है।P (x \u003d x i )। अनुभवजन्य वितरण समारोहF * (x) ) सैद्धांतिक वितरण समारोह का एक अस्थिर और अमीर मूल्यांकन हैF (x) \u003d p (x)< x ).
उदाहरण:
नमूना तालिका पर फैलाव की गणितीय अपेक्षा के असंगत आकलन पाएं।
| एक्स I. |
|||
| एन मैं |
फेसला:
नमूनाकरण वॉल्यूम एन \u003d 20।
गणितीय अपेक्षा का अनौपचारिक मूल्यांकन चुनिंदा औसत है।
फैलाव के अनइंस्टॉल किए गए मूल्यांकन की गणना करने के लिए, हम पहले एक चुनिंदा फैलाव पाएंगे:
अब हमें एक अनबोट मूल्यांकन मिलेगा:
9. वितरण मानकों के अंतराल अनुमान
अंतराल अध्ययन के तहत अंतराल के दो संख्यात्मक मूल्यों द्वारा निर्धारित एक सांख्यिकीय मूल्यांकन है।
संख्या\u003e 0, किस पर | प्रश्न - क्यू * |< , अंतराल मूल्यांकन की सटीकता को दर्शाता है।
विश्वास बुला हुआ मध्यान्तर किसी दिए गए संभाव्यता के साथपैरामीटर के अज्ञात मूल्य को कवर करता हैप्र । सभी संभावित पैरामीटर मूल्यों के विभिन्न प्रकार के ट्रस्ट अंतराल का जोड़प्र बुला हुआ महत्वपूर्ण क्षेत्र। यदि महत्वपूर्ण क्षेत्र केवल आत्मविश्वास अंतराल के एक तरफ स्थित है, तो आत्मविश्वास अंतराल कहा जाता है एक तरफा: बाएं पक्षीययदि महत्वपूर्ण क्षेत्र केवल बाईं ओर मौजूद है और सही तरफा अगर केवल दाईं ओर। अन्यथा, आत्मविश्वास अंतराल कहा जाता है द्विपक्षीय.
विश्वसनीयता, या आत्मविश्वास संभावना रेटिंग क्यू (क्यू का उपयोग कर) *) संभावना को कॉल करें जिसके साथ निम्नलिखित असमानता की जाती है: |प्रश्न - क्यू * |< .
अक्सर, आत्मविश्वास की संभावना अग्रिम में निर्दिष्ट होती है (0.95; 0.9 9; 0.9 9 99) और वे एक के करीब होने की आवश्यकता लागू करते हैं।
संभावनाकॉल त्रुटि की संभावना, या महत्व का स्तर।
चलो | प्रश्न - क्यू * |< , तब फिर। इसका मतलब है कि संभावना के साथयह तर्क दिया जा सकता है कि पैरामीटर का सही मूल्यप्र अंतराल से संबंधित हैं। विक्षेपण मूल्य छोटाइसके अलावा, मूल्यांकन।
आत्मविश्वास अंतराल की सीमाएं (समाप्त) ट्रस्ट सीमाएं, या क्रिटिकल सीमाएं।
आत्मविश्वास अंतराल की सीमाओं के मूल्य पैरामीटर वितरण कानून पर निर्भर करते हैंक्यू *।
विचलन की परिमाणआत्मविश्वास अंतराल की चौड़ाई के बराबर आधा, कहा जाता है मूल्यांकन सटीकता।
आत्मविश्वास अंतराल के निर्माण के तरीकों को पहली बार अमेरिकी सांख्यिकीविद वाई न्यूमैन द्वारा विकसित किया गया था। शुद्धता मूल्यांकनभरोसा और नमूना n एक दूसरे से संबंधित। इसलिए, दो मानों के विशिष्ट मानों को जानना, आप हमेशा तीसरे की गणना कर सकते हैं।
सामान्य वितरण की गणितीय अपेक्षा का आकलन करने के लिए आत्मविश्वास अंतराल ढूँढना, यदि मानक विचलन ज्ञात है।
सामान्य वितरण के कानून के अधीन सामान्य जनसंख्या का नमूना दें। सामान्य मीन-स्क्वायर विचलन को जाने देंलेकिन सैद्धांतिक वितरण की अज्ञात गणितीय उम्मीदए ().
निम्नलिखित सूत्र मान्य है:
वे। विचलन की परिभाषा के अनुसारएक अज्ञात सामान्य औसत अंतराल के साथ पाया जा सकता है। और इसके विपरीत। सूत्र से यह स्पष्ट है कि नमूना के आकार में वृद्धि और आत्मविश्वास की संभावना के निश्चित मूल्य, मूल्य- घटता है, यानी। मूल्यांकन की सटीकता बढ़ जाती है। विश्वसनीयता (ट्रस्ट संभावना) में वृद्धि के साथ, मूल्य- यहां तक \u200b\u200bकि, यानी मूल्यांकन सटीकता घट जाती है।
उदाहरण:
परीक्षणों के परिणामस्वरूप, निम्नलिखित मान प्राप्त किए गए थे -25, 34, -20, 10, 21. यह ज्ञात है कि वे आरएमएस विचलन के साथ सामान्य वितरण के कानून के अधीन हैं। एक अनुमान लगाएं * गणितीय उम्मीद के लिए ए। उसके लिए 9% आत्मविश्वास अंतराल का निर्माण करें।
फेसला:
अविश्वसनीय अनुमान खोजें
फिर
एक के लिए आत्मविश्वास अंतराल का रूप है: 4 - 1.47< ए।< 4+ 1,47 или 2,53 < a < 5, 47
सामान्य वितरण की गणितीय अपेक्षा का आकलन करने के लिए आत्मविश्वास अंतराल ढूँढना, यदि अज्ञात मानक विचलन है।
यह ज्ञात हो कि सामान्य कुल सामान्य वितरण के कानून के अधीनस्थ है, जहां ए और। विश्वसनीयता के साथ आवरण अंतराल की सटीकताइस मामले में पैरामीटर ए का सही मूल्य सूत्र द्वारा गणना की जाती है:
, जहां एन नमूना का आकार है, , - छात्र गुणांक (यह निर्दिष्ट मूल्यों के अनुसार पाया जाना चाहिएएन मैं तालिका "छात्र के महत्वपूर्ण वितरण" से)।
उदाहरण:
परीक्षण के परिणामस्वरूप, निम्नलिखित मान प्राप्त किए गए थे -35, -32, -26, -35, -30, -17। यह ज्ञात है कि वे सामान्य वितरण के कानून का पालन करते हैं। गणितीय उम्मीदों और एक सामान्य आबादी के लिए एक सामान्य आबादी 0.9 की संभावना के साथ एक आत्मविश्वास अंतराल खोजें।
फेसला:
अविश्वसनीय अनुमान खोजें.
खोज.
फिर
ट्रस्ट अंतराल फॉर्म ले जाएगा(-29.2 - 5.62; -29,2 + 5.62) या (-34.82; -23,58)।
फैलाव और सामान्य वितरण के मानक विचलन के लिए एक आत्मविश्वास इंटरलाइन ढूँढना
सामान्य कानून द्वारा वितरित मूल्यों के कुछ सामान्य सेट से जाने दें, मात्रा का एक यादृच्छिक नमूना लिया जाता हैएन < 30 जिसके लिए चुनिंदा भिन्नताओं की गणना की जाती है: स्थानांतरितऔर एस 2 को ठीक किया। फिर दी गई विश्वसनीयता के साथ अंतराल अनुमान खोजने के लिएसामान्य फैलाव के लिएडी सामान्य-चौकोर विचलननिम्नलिखित सूत्रों का उपयोग किया जाता है।
या,
मूल्यों- महत्वपूर्ण मूल्यों की एक तालिका की मदद से खोजें पियरसन वितरण।
फैलाव के लिए आत्मविश्वास अंतराल इन असमानताओं से वर्ग में असमानता के सभी हिस्सों को बनाकर है।
उदाहरण:
15 बोल्ट की गुणवत्ता की जांच की गई थी। यह मानते हुए कि उनके निर्माण में त्रुटि सामान्य वितरण कानून के अधीन है, और चुनिंदा औसत विचलनसमान रूप से 5 मिमी, विश्वसनीयता के साथ निर्धारित करेंएक अज्ञात पैरामीटर के लिए ट्रस्ट अंतराल
अंतराल सीमाएं डबल असमानता के रूप में प्रस्तुत की जाएंगी:
फैलाव के लिए दो तरफा आत्मविश्वास अंतराल के सिरों को निर्धारित किया जा सकता है और उपयुक्त तालिका (स्वतंत्रता और विश्वसनीयता की डिग्री की संख्या के आधार पर फैलाव के लिए आत्मविश्वास अंतराल की सीमाओं (फैलाव के लिए आत्मविश्वास अंतराल की सीमाएं) )। ऐसा करने के लिए, अंतराल की तालिका से प्राप्त को सही फैलाव एस 2 से गुणा किया जाता है.
उदाहरण:
मैं पिछले कार्य को दूसरे तरीके से तय करता हूं।
फेसला:
हमें सही फैलाव मिलता है:
टेबल पर "स्वतंत्रता और विश्वसनीयता की डिग्री की संख्या के आधार पर, फैलाव के लिए आत्मविश्वास अंतराल की सीमाएं, हमें फैलाव के लिए आत्मविश्वास अंतराल की सीमाएं मिलेंगीक।\u003d 14 I.: निचली सीमा 0.513 और ऊपरी 2,354।
पर प्राप्त सीमाओं को गुणा करेंएस 2 और निकाले गए जड़ (क्योंकि हमें फैलाव के लिए एक आत्मविश्वास अंतराल की आवश्यकता नहीं है, लेकिन रिकंडक्टिक विचलन के लिए)।
जैसा कि उदाहरणों से देखा जा सकता है, आत्मविश्वास अंतराल का मूल्य इसके निर्माण की विधि पर निर्भर करता है और एक दूसरे के करीब, लेकिन असमान परिणाम देता है।
नमूने में काफी बड़ी मात्रा में (एन\u003e 30) सामान्य माध्य-वर्ग विचलन के लिए आत्मविश्वास अंतराल की सीमाओं को सूत्र द्वारा निर्धारित किया जा सकता है: - एक संख्या जो सारणीबद्ध है और प्रासंगिक संदर्भ तालिका में दी गई है।
अगर 1- प्र<1, то формула имеет вид:
उदाहरण:
हम पिछले कार्य को तीसरे तरीके से तय करते हैं।
फेसला:
पहले मिलाएस= 5,17. प्र(0.95; 15) \u003d 0.46 - हम टेबल पर पाते हैं।
फिर:
एक घटना की संभावना का अंतराल अनुमान। चयन के एक किफायती विधि के साथ नमूने के आकार की गणना के लिए सूत्र।
आपके द्वारा रुचि रखने वाली घटनाओं की संभावनाओं को निर्धारित करने के लिए, हम चुनिंदा विधि का उपयोग करते हैं: हम करते हैं एन स्वतंत्र प्रयोग, जिनमें से प्रत्येक में हो सकता है (या नहीं होता) घटना ए (संभावना) आर प्रत्येक प्रयोग में घटनाओं की उपस्थिति स्थिर है)। फिर सापेक्ष आवृत्ति पी * घटनाओं की उपस्थिति लेकिन अ श्रंखला में एन संभावनाओं के लिए एक बिंदु अनुमान के रूप में परीक्षण स्वीकार किए जाते हैं। पी घटना उपस्थिति लेकिन अ एक अलग परीक्षण में। इस मामले में, पी * का मान कहा जाता है चुनिंदा शेयर घटना उपस्थिति लेकिन अ, और आर - आम .
केंद्रीय सीमा प्रमेय (मोरेव-लैपलेस प्रमेय) की जांच के आधार पर, बड़ी मात्रा में नमूनाकरण के साथ होने वाली घटना की सापेक्ष आवृत्ति सामान्य रूप से पैरामीटर एम (पी *) \u003d पी और के साथ वितरित की जा सकती है
इसलिए, एन\u003e 30 के साथ, सामान्य शेयर के लिए आत्मविश्वास अंतराल सूत्रों का उपयोग करके बनाया जा सकता है:
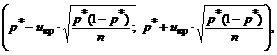
जहां यू क्र लैप्पलेस फ़ंक्शन की तालिकाओं पर स्थित है, एक दिए गए ट्रस्ट संभावना को ध्यान में रखते हुए γ: 2 एफ (यू सीआर) \u003d γ।
N≤30 के एक छोटे से नमूना आकार के साथ, त्रुटि ε छात्र वितरण तालिका द्वारा निर्धारित किया जाता है: ![]() जहां टी क्र \u003d टी (के; α) और स्वतंत्रता के डिग्री की डिग्री \u003d एन -1 की संभावना α \u003d 1-γ (दो तरफा क्षेत्र)।
जहां टी क्र \u003d टी (के; α) और स्वतंत्रता के डिग्री की डिग्री \u003d एन -1 की संभावना α \u003d 1-γ (दो तरफा क्षेत्र)।
सूत्र मान्य हैं यदि चयन यादृच्छिक रूप से फिर से किया गया था (अनंत का सामान्य सेट), अन्यथा, चयन (तालिका) की विशिष्टता में सुधार करना आवश्यक है।
सामान्य शेयर के लिए औसत नमूना त्रुटि
| सामान्य समग्र | अनंत | परिमित मात्रा एन |
| चयन प्रकार | दोहराया गया | कब्जा |
| औसत नमूना त्रुटि |
चयन के एक किफायती विधि के साथ नमूना के आकार की गणना के लिए सूत्र
| चयन की विधि | नमूना संख्यात्मक सूत्र | ||
| मध्य के लिए | एक शेयर के लिए | ||
| दोहराया गया | |||
| कब्जा | |||
सामान्य कार्य
सवाल "निर्दिष्ट मूल्य पी 0 के आत्मविश्वास अंतराल को शामिल करता है?" - आप सांख्यिकीय परिकल्पना एच 0: पी \u003d पी 0 की जांच करके जवाब दे सकते हैं। यह माना जाता है कि बर्नौली परीक्षण योजना (स्वतंत्र, संभावना) के अनुसार प्रयोग किए जाते हैं पी घटना उपस्थिति लेकिन अ लगातार)। नमूना मात्रा द्वारा एन पी * की सापेक्ष आवृत्ति निर्धारित करें घटना की उपस्थिति ए: जहां म। - घटनाओं की संख्या लेकिन अ श्रंखला में एन परीक्षण। एच 0 परिकल्पना की जांच करने के लिए, आंकड़ों का उपयोग किया जाता है, एक मानक सामान्य वितरण के साथ एक मानक सामान्य वितरण (तालिका 1) के साथ।तालिका 1 - सामान्य अनुपात के बारे में परिकल्पना
परिकल्पना | एच 0: पी \u003d पी 0 | एच 0: पी 1 \u003d पी 2 |
| मान्यताओं | बर्नौली परीक्षण योजना | बर्नौली परीक्षण योजना |
| नमूना रेटिंग | 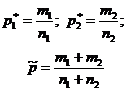 |
|
| आंकड़े क। |  |  |
| सांख्यिकीय वितरण क। | मानक सामान्य n (0,1) |
उदाहरण संख्या 1। एक यादृच्छिक पुन: चयन की मदद से, कंपनी के प्रबंधन ने अपने 9 00 कर्मचारियों का नमूना सर्वेक्षण किया। उत्तरदाताओं में से 270 महिलाएं हुईं। 0.95 की संभावना के साथ एक आत्मविश्वास अंतराल बनाएं, जो कंपनी की पूरी टीम में महिलाओं के वास्तविक अनुपात को शामिल करता है।
फेसला। हालत से, महिलाओं का नमूना हिस्सा (सभी उत्तरदाताओं के बीच महिलाओं की सापेक्ष आवृत्ति) है। चूंकि चयन दोहराया जाता है, और नमूना का आकार बड़ा होता है (एन \u003d 900) चयन त्रुटि सूत्र द्वारा निर्धारित की जाती है ![]()
यूआर का मूल्य अनुपात 2 एफ (यू सीआर) \u003d γ, यानी से लैपलेस फ़ंक्शन की तालिका का पता लगाएं। ![]() लैपलेस फ़ंक्शन (परिशिष्ट 1) यू केआर \u003d 1.96 में 0.475 का मान लेता है। इसलिए, सीमा त्रुटि
लैपलेस फ़ंक्शन (परिशिष्ट 1) यू केआर \u003d 1.96 में 0.475 का मान लेता है। इसलिए, सीमा त्रुटि ![]() और वांछित आत्मविश्वास अंतराल
और वांछित आत्मविश्वास अंतराल
(पी - ε, पी + ε) \u003d (0.3 - 0.18; 0.3 + 0.18) \u003d (0.12; 0.48)
इसलिए, 0.95 की संभावना के साथ, यह गारंटी दी जा सकती है कि कंपनी की पूरी टीम में महिलाओं का अनुपात 0.12 से 0.48 की सीमा में है।
उदाहरण संख्या 2। पार्किंग स्थल का मालिक "सफल" दिन को पढ़ता है यदि पार्किंग स्थल 80% से अधिक से भरा हुआ है। वर्ष के दौरान, 40 पार्किंग चेक आयोजित किए गए, जिनमें से 24 "सफल" थे। 0.98 की संभावना के साथ, वर्ष के दौरान "सफल" दिनों के वास्तविक हिस्से का मूल्यांकन करने के लिए आत्मविश्वास अंतराल का पता लगाएं।
फेसला। "सफल" दिनों का नमूना हिस्सा है
लेपलेस के टेबल फ़ंक्शन पर, हमें यू के साथ यू सीआर का मूल्य मिलेगा
भरोसा
एफ (2.23) \u003d 0.4 9, यू केआर \u003d 2.33।
चयन को ध्यान में रखते हुए संभव नहीं है (यानी, दो चेक एक दिन में आयोजित नहीं किए गए थे), हमें एक सीमा त्रुटि मिलती है: ![]()
जहां n \u003d 40, n \u003d 365 (दिन)। यहां से ![]()
और सामान्य शेयर के लिए आत्मविश्वास अंतराल: (पी - ε, पी + ε) \u003d (0.6 - 0.17; 0.6 + 0.17) \u003d (0.43; 0.77)
0.98 की संभावना के साथ, यह उम्मीद की जा सकती है कि वर्ष के दौरान "सफल" दिनों का हिस्सा 0.43 से 0.77 तक की सीमा में है।
उदाहरण संख्या 3। पार्टी में 2500 उत्पादों की जांच, पता चला कि उच्चतम ग्रेड के 400 उत्पादों, और एन-एम - संख्या। 95% तक 0.01 तक के आत्मविश्वास के साथ उच्चतम ग्रेड के हिस्से को निर्धारित करने के लिए आपको उत्पादों की जांच करने की आवश्यकता है?
समाधान हम पुन: चयन के लिए नमूनाकरण की संख्या निर्धारित करने के लिए सूत्र की तलाश में हैं।
F (t) \u003d γ / 2 \u003d 0.95 / 2 \u003d 0.475 और लैपलेस टेबल पर यह मान टी \u003d 1.96 से मेल खाता है
चुनिंदा शेयर w \u003d 0.16; त्रुटि नमूनाकरण ε \u003d 0.01
उदाहरण संख्या 4। उत्पादों का बैच स्वीकार किया जाता है यदि यह संभावना है कि उत्पाद उचित मानक होगा कम से कम 0.97 है। प्राप्त बैच के यादृच्छिक रूप से चयनित 200 उत्पादों में से 1 9 3 प्रासंगिक मानकों थे। क्या पार्टी को स्वीकार करने के लिए महत्व α \u003d 0.02 के स्तर पर संभव है?
फेसला। हम मुख्य और वैकल्पिक परिकल्पना तैयार करते हैं।
एच 0: पी \u003d पी 0 \u003d 0.97 - अज्ञात सामान्य शेयर पी दिए गए मूल्य के बराबर पी 0 \u003d 0.97। इस स्थिति के संबंध में - प्राप्त बैच से भाग की संभावना मानक के बराबर होगी, 0.97 के बराबर; वे। उत्पादों का एक बैच लिया जा सकता है।
एच 1: पी<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
आंकड़ों का मनाया गया मूल्य क। (तालिका) निर्दिष्ट मानों पर गणना करें P 0 \u003d 0.97, n \u003d 200, m \u003d 193

महत्वपूर्ण महत्व समानता से लैपलेस फ़ंक्शन की तालिका का पता लगाएं
![]()
स्थिति के तहत α \u003d 0.02, यह यहां से एफ (केकेआर) \u003d 0.48 और केकेआर \u003d 2.05 से। महत्वपूर्ण क्षेत्र बाएं तरफा, यानी यह अंतराल (-∞; -k केपी) \u003d (-∞; -2.05) है। नाभि \u003d -0.415 के लिए मनाया गया मूल्य महत्वपूर्ण क्षेत्र से संबंधित नहीं है, इसलिए, महत्व के इस स्तर पर मुख्य परिकल्पना को हटाने का कोई कारण नहीं है। आप उत्पादों का एक बैच ले सकते हैं।
उदाहरण संख्या 5। दो पौधे एक ही प्रकार के विवरण बनाते हैं। उनकी गुणवत्ता का आकलन करने के लिए, नमूने इन पौधों के उत्पादों से बने होते हैं और निम्नलिखित परिणाम प्राप्त होते हैं। पहले संयंत्र के 200 चयनित उत्पादों में से दूसरे संयंत्र के 300 उत्पादों - 15 दोषपूर्ण के बीच 20 दोषपूर्ण साबित हुए।
0.025 के महत्व के स्तर पर, पता लगाएं कि इन पौधों द्वारा निर्मित भागों के रूप में एक महत्वपूर्ण अंतर है या नहीं।
स्थिति के तहत α \u003d 0.025, इसलिए एफ (सीकेआर) \u003d 0.4875 और केकेआर \u003d 2.24। द्विपक्षीय विकल्प के साथ, अनुमेय मूल्यों के क्षेत्र में फॉर्म (-2.24; 2.24) है। मनाया मूल्य के नाभि \u003d 2,15 इस अंतराल में गिरता है, यानी महत्व के इस स्तर पर मुख्य परिकल्पना को अस्वीकार करने का कोई कारण नहीं है। पौधे एक ही गुणवत्ता के उत्पादों को बनाते हैं।
यह अक्सर होता है कि किसी भी विशेष सामाजिक घटना का विश्लेषण करना और उसके बारे में जानकारी प्राप्त करना आवश्यक है। ऐसे कार्य अक्सर आंकड़ों और सांख्यिकीय अध्ययन के साथ होते हैं। पूरी तरह से सोशल घटना की जांच करें अक्सर असंभव है। उदाहरण के लिए, किसी भी प्रश्न पर आबादी या किसी निश्चित शहर के सभी निवासियों की राय कैसे जानें? बिल्कुल सब पूछें - मामला लगभग असंभव और बहुत श्रमिक है। ऐसे मामलों में, हमें एक नमूना चाहिए। यह वास्तव में अवधारणा है जिस पर लगभग सभी शोध और परीक्षण आधारित होते हैं।
नमूना क्या है
एक विशिष्ट सामाजिक घटना का विश्लेषण करते समय, इसके बारे में जानकारी प्राप्त करना आवश्यक है। यदि आप कोई शोध करते हैं, तो यह ध्यान दिया जा सकता है कि अध्ययन और विश्लेषण अनुसंधान वस्तु के एक सेट की प्रत्येक इकाई के अधीन नहीं है। केवल पूरी कुटिलता का एक निश्चित हिस्सा ध्यान में रखा जाता है। यह प्रक्रिया नमूना है: जब सेट से केवल कुछ इकाइयों की जांच की जाती है।
बेशक, नमूना के प्रकार पर निर्भर करता है। लेकिन बुनियादी नियम हैं। मुख्य बात यह है कि कुल का चयन बिल्कुल यादृच्छिक होना चाहिए। उपयोग की जाने वाली कुल इकाइयों को किसी भी मानदंड के कारण नहीं चुना जाना चाहिए। मोटे तौर पर, यदि आपको एक निश्चित शहर की आबादी की एक कुलता इकट्ठा करने और केवल पुरुषों को लेने की आवश्यकता है, तो अध्ययन एक त्रुटि होगी, क्योंकि चयन गलती से खर्च नहीं किया गया था, लेकिन लिंग द्वारा चुना गया था। लगभग सभी नमूना विधियां इस नियम पर आधारित हैं।
चयन नियम
चयनित कुल योग के लिए संपूर्ण घटना के मुख्य गुणों को प्रतिबिंबित करने के लिए, इसे विशिष्ट कानूनों के अनुसार बनाया जाना चाहिए, जहां निम्नलिखित श्रेणियों पर ध्यान केंद्रित करना आवश्यक है:
- नमूना (चुनिंदा कुल);
- सामान्य जनसंख्या;
- प्रतिनिधित्वशीलता;
- प्रतिनिधि त्रुटि;
- कुल की एक इकाई;
- एक नमूना बनाने के तरीके।
चुनिंदा अवलोकन और नमूनाकरण की विशेषताएं निम्नानुसार हैं:
- प्राप्त सभी परिणाम गणितीय कानूनों और नियमों पर आधारित हैं, जो उचित अनुसंधान और सही गणनाओं के तहत हैं, परिणाम व्यक्तिपरक आधार पर विकृत नहीं होंगे।
- यह अवसर को बहुत तेज़ और परिणाम प्राप्त करने के लिए कम समय और संसाधनों के साथ देता है, घटनाओं की पूरी श्रृंखला का अध्ययन नहीं करता है, बल्कि केवल उनका हिस्सा।
- इसे विभिन्न वस्तुओं का अध्ययन करने के लिए लागू किया जा सकता है: विशिष्ट मुद्दों से, उदाहरण के लिए, आयु, समूह की मंजिल हम सार्वजनिक राय के अध्ययन या जनसंख्या के भौतिक समर्थन के स्तर के लिए रुचि रखते हैं।
चुनिंदा अवलोकन
चुनिंदा - यह एक सांख्यिकीय अवलोकन है, जिसमें अध्ययन अध्ययन के पूरे सेट के अधीन नहीं है, लेकिन केवल कुछ, एक निश्चित तरीके से चुने गए हैं, और इस भाग के अध्ययन के परिणाम पूरे सेट को वितरित किए जाते हैं । इस भाग को एक चुनिंदा सेट कहा जाता है। अध्ययन की वस्तु की एक बड़ी श्रृंखला का अध्ययन करने का यह एकमात्र तरीका है।
लेकिन चुनिंदा अवलोकन का उपयोग केवल उन मामलों में किया जा सकता है जहां इकाइयों के केवल एक छोटे समूह की जांच करना आवश्यक है। उदाहरण के लिए, दुनिया में महिलाओं के लिए पुरुषों के अनुपात का अध्ययन करते समय, चुनिंदा अवलोकन का उपयोग किया जाएगा। स्पष्ट कारणों से, हमारे ग्रह के हर निवासी को ध्यान में रखना असंभव है।
लेकिन एक ही अध्ययन के साथ, लेकिन पृथ्वी के सभी निवासियों के अलावा, लेकिन एक विशिष्ट स्कूल में एक निश्चित 2 "ए" वर्ग, एक निश्चित शहर, एक निश्चित देश, चुनिंदा अवलोकन के बिना कर सकता है। आखिरकार, अध्ययन की वस्तु की पूरी श्रृंखला का विश्लेषण करने के लिए - यह काफी संभव है। इस वर्ग की लड़कों और लड़कियों की गणना करना आवश्यक है - यह अनुपात होगा।

चुनिंदा और सामान्य कुल
वास्तव में, सबकुछ इतना मुश्किल नहीं है, जैसा कि यह लगता है। अध्ययन के किसी भी वस्तु में, दो सिस्टम हैं: सामान्य और चुनिंदा कुल। यह क्या है? सभी इकाइयां सामान्य को संदर्भित करती हैं। और चुनिंदा करने के लिए - कुल कुल योग की उन इकाइयों को नमूना के लिए लिया गया था। यदि सब कुछ सही तरीके से किया जाता है, तो चयनित भाग पूरे (सामान्य) सेट का एक कम लेआउट होगा।
अगर हम सामान्य कुल के बारे में बात करते हैं, तो केवल दो प्रकार के इसे प्रतिष्ठित किया जा सकता है: एक निश्चित और अनिश्चित सामान्य सामान्य समुच्चय। यह इस बात पर निर्भर करता है कि इस प्रणाली की इकाइयों की कुल संख्या ज्ञात है या नहीं। यदि यह एक निश्चित सामान्य सेट है, तो नमूना क्या ज्ञात है कि इकाइयों की कुल संख्या का प्रतिशत नमूना होगा।
यह क्षण अनुसंधान में बहुत जरूरी है। उदाहरण के लिए, यदि आपको किसी विशेष कारखाने में खराब गुणवत्ता वाले कन्फेक्शनरी उत्पादों के प्रतिशत की जांच करने की आवश्यकता है। मान लीजिए कि सामान्य कुल पहले से ही परिभाषित है। यह सिर्फ इतना ही ज्ञात है कि प्रति वर्ष यह कंपनी 1000 कन्फेक्शनरी का उत्पादन करती है। यदि आप इस हजार से 100 यादृच्छिक कन्फेक्शनरी उत्पादों का नमूना बनाते हैं और उन्हें परीक्षा में भेजते हैं, तो त्रुटि न्यूनतम होगी। मोटे तौर पर, एक अध्ययन को सभी उत्पादों के 10%, और परिणामों पर हम प्रतिनिधित्व की त्रुटि को ध्यान में रखते हुए, सभी उत्पादों की खराब गुणवत्ता के बारे में बात कर सकते हैं।
और यदि आपके पास अनिश्चित सामान्य कुल योग से 100 कन्फेक्शनरी उत्पादों का नमूना है, जहां वे वास्तव में थे, स्वीकार किए जाते थे, 1 मिलियन यूनिट, नमूना का नतीजा और शोध स्वयं महत्वपूर्ण और गलत होगा। क्या आप अंतर महसूस करते हैं? इसलिए, ज्यादातर मामलों में सामान्य आबादी की निश्चितता अत्यंत महत्वपूर्ण है और अध्ययन के परिणाम को बहुत प्रभावित करती है।

समुच्चयता
तो, अब सबसे महत्वपूर्ण मुद्दों में से एक - नमूना क्या होना चाहिए? यह अध्ययन का मुख्य क्षण है। इस चरण में, नमूना की गणना करना और कुल संख्या की इकाइयों का चयन करना आवश्यक है। सेट को सही ढंग से चुना गया था यदि सामान्य जनसंख्या की कुछ विशेषताओं और विशेषताओं को चुनिंदा में बनी हुई है। इसे प्रतिनिधि कहा जाता है।
दूसरे शब्दों में, यदि चयन के बाद, भाग उसी रुझान और सुविधाओं को बरकरार रखता है जो जांच की पूरी राशि, तो इस तरह के एक सेट को प्रतिनिधि कहा जाता है। लेकिन प्रत्येक विशिष्ट नमूने को प्रतिनिधि समग्रता से नहीं चुना जा सकता है। अध्ययन की ऐसी वस्तुएं हैं, जिनमें से नमूना केवल प्रतिनिधि नहीं हो सकता है। यहां से और एक प्रतिनिधित्व त्रुटि की अवधारणा होती है। लेकिन हम इस बारे में बात करेंगे।
नमूना कैसे बनाएं
इसलिए, प्रतिनिधित्वशीलता अधिकतम है, तीन मूल नमूना नियम आवंटित करें:
- नमूना की संख्या का सबसे अनूठा संकेतक 20% है। 20% का सांख्यिकीय नमूना लगभग वास्तविकता के लिए जितना संभव हो सके परिणाम देगा। साथ ही, सामान्य आबादी के अधिकांश भाग के लिए आम कुल के अधिकांश भाग में स्थानांतरित करना आवश्यक नहीं है। नमूना का 20% संकेतक है जिसे कई अध्ययनों से विकसित किया गया है। हम थोड़ा सिद्धांत देते हैं। अधिक नमूना, प्रतिनिधित्व त्रुटि को छोटा और अध्ययन के परिणामस्वरूप अधिक सटीक। निकटतम इकाइयों की संख्या के संदर्भ में सामान्य रूप से एक चुनिंदा सेट है, अधिक सटीक और सही परिणाम होंगे। आखिरकार, यदि आप पूरे सिस्टम का पता लगाते हैं, तो परिणाम 100% होगा। लेकिन कोई भी नमूना नहीं है। ये वे शोध हैं जिनसे संपूर्ण सरणी की जांच की जाती है, सभी इकाइयां, इसलिए यह हमें रूचि नहीं देती है।
- अनुचित के मामले में, सामान्य आबादी के 20% की प्रसंस्करण को कम से कम 1001 की राशि में कुल इकाइयों का अध्ययन करने की अनुमति है। यह वस्तु की एक सरणी के अध्ययन के संकेतकों में से एक है अध्ययन, जो समय के साथ उत्पादित किया गया है। बेशक, यह बड़े शोध सरणी के लिए सटीक परिणाम नहीं देगा, लेकिन संभावित नमूना सटीकता के लिए अधिकतम दृष्टिकोण।
- आंकड़ों में, कई सूत्र और फोल्ड टेबल हैं। अध्ययन की वस्तु और नमूना मानदंड पर निर्भर करता है, एक सूत्र चुनने की व्यवहार्यता है। लेकिन इस आइटम का उपयोग जटिल और बहु-चरण अध्ययनों में किया जाता है।
त्रुटि (त्रुटि) प्रतिनिधित्वशीलता
चयनित नमूने की गुणवत्ता की मुख्य विशेषता "प्रतिनिधि त्रुटि" की अवधारणा है। यह क्या है? ये चुनिंदा और ठोस अवलोकन के संकेतकों के बीच कुछ विसंगतियां हैं। त्रुटि के मामले में, प्रतिनिधित्व विश्वसनीय, सामान्य और अनुमानित में विभाजित है। दूसरे शब्दों में, क्रमशः 3 से 10% तक और 10 से 20% तक की राशि में अनुमत विचलन। हालांकि यह आंकड़ों में वांछनीय है कि त्रुटि 5-6% से अधिक नहीं है। अन्यथा, नमूना की अपर्याप्त प्रतिनिधित्व के बारे में बात करने का एक कारण है। प्रतिनिधि की तात्कालिकता की गणना करने के लिए और यह चुनिंदा या सामान्य आबादी को कैसे प्रभावित करता है, कई कारकों को ध्यान में रखा जाता है:
- संभावना जिसके साथ सटीक परिणाम प्राप्त करना आवश्यक है।
- चुनिंदा कुल की इकाइयों की संख्या। जैसा कि पहले उल्लेख किया गया है, कम इकाइयां एक नमूना होंगी, उतनी ही अधिक प्रतिनिधित्व त्रुटि होगी, और इसके विपरीत।
- अध्ययन के तहत कुलता की एकरूपता। अधिक विषमता एक कुलता है, प्रतिनिधित्व की अनिश्चितता जितनी अधिक होगी। प्रतिनिधि होने की संभावना सभी सभी घटकों की एकरूपता पर निर्भर करती है।
- चुनिंदा सेट में इकाइयों के चयन की विधि।
विशिष्ट अध्ययनों में, औसत त्रुटि का प्रतिशत आमतौर पर शोधकर्ता द्वारा अवलोकन कार्यक्रम के आधार पर और पहले आयोजित अध्ययनों के आंकड़ों के अनुसार निर्धारित किया जाता है। एक नियम के रूप में, एक वैध नमूना त्रुटि को 3-5% के भीतर एक अनुमेय त्रुटि (प्रतिनिधि) माना जाता है।

अधिक - हमेशा बेहतर नहीं
यह याद रखने के लायक भी है कि चुनिंदा अवलोकन संगठन में मुख्य बात इसकी मात्रा को अनुमत न्यूनतम तक लाने के लिए है। इसे नमूना त्रुटि की सीमाओं को कम करने का प्रयास नहीं करना चाहिए, क्योंकि इससे इन नमूनों के आकार में एक अन्यायपूर्ण वृद्धि हो सकती है और इसलिए, चुनिंदा अवलोकन पर व्यय में वृद्धि के लिए।
साथ ही, प्रतिनिधित्व की तात्कालिकता के आकार को अत्यधिक वृद्धि करना असंभव है। दरअसल, इस मामले में, हालांकि चुनिंदा कुल की मात्रा में कमी आएगी, इससे प्राप्त परिणामों की सटीकता में गिरावट आएगी।
आमतौर पर शोधकर्ता के सामने क्या प्रश्न हैं
कोई भी अध्ययन यदि इसे किया जाता है, तो कुछ उद्देश्य के लिए और कुछ परिणाम प्राप्त करने के लिए। एक नियम के रूप में नमूना अध्ययन आयोजित करते समय, प्रारंभिक प्रश्न डाल दिए जाते हैं:
- चुनिंदा कुल इकाइयों की आवश्यक संख्या का निर्धारण, यानी, कितनी इकाइयों की जांच की जाएगी। इसके अलावा, एक सटीक अध्ययन के लिए, सेट प्रतिनिधि होना चाहिए।
- स्थापित संभावना स्तर के साथ तत्काल त्रुटि की गणना। यह ध्यान रखना आवश्यक है कि चुनिंदा अध्ययन 100% की संभावना स्तर के साथ नहीं होता है। यदि वह उदाहरण, जिसने एक निश्चित खंड का अध्ययन किया, तर्क दिया कि उनके परिणाम 100% की संभावना के साथ सटीक हैं, तो यह एक झूठ है। बारहमासी अभ्यास पहले से ही एक सही ढंग से आयोजित नमूना अध्ययन की संभावना का प्रतिशत निर्धारित कर चुका है। यह सूचक 95.4% है।
नमूना में अनुसंधान की इकाइयों का चयन करने के तरीके
हर नमूना का प्रतिनिधित्व नहीं किया जाता है। कभी-कभी सामान्य रूप से और इसके हिस्सों में सामान्य रूप से एक ही संकेत अलग होता है। प्रतिनिधित्व आवश्यकताओं को प्राप्त करने के लिए, विभिन्न नमूना तकनीकों का उपयोग करने की सलाह दी जाती है। इसके अलावा, एक या किसी अन्य विधि का उपयोग विशिष्ट परिस्थितियों पर निर्भर करता है। इन नमूना निर्माण तकनीकों में प्रतिष्ठित हैं:
- यादृच्छिक चयन;
- यांत्रिक चयन;
- विशिष्ट चयन;
- सीरियल (घोंसला) चयन।
यादृच्छिक चयन कुल की इकाइयों के यादृच्छिक चयन के उद्देश्य से उपायों की एक प्रणाली है, जब नमूना में शामिल होने की संभावना सामान्य आबादी की सभी इकाइयों के बराबर होती है। इस तकनीक को केवल समानता के मामले में और इसमें अंतर्निहित संकेतों की एक छोटी संख्या में लागू करने की सलाह दी जाती है। अन्यथा, कुछ विशेषता विशेषताओं का जोखिम नमूना में प्रतिबिंबित नहीं होता है। यादृच्छिक चयन के संकेत नमूना बनाने के सभी अन्य तरीकों पर आधारित हैं।
इकाइयों के यांत्रिक चयन के साथ एक निश्चित अंतराल के माध्यम से किया जाता है। यदि आपको विशिष्ट अपराधों का नमूना बनाने की आवश्यकता है, तो आप अपने कुल संख्या और नमूना आकार के आधार पर प्रत्येक 5, 10 वीं या 15 वें कार्ड के सभी सांख्यिकी लेखांकन कार्ड से वापस ले सकते हैं। इस विधि का नुकसान यह है कि चयन से पहले कुल इकाइयों की पूर्ण लेखांकन के लिए आवश्यक है, फिर रैंकिंग और केवल उसके बाद एक निश्चित अंतराल के साथ नमूना करना संभव है। इस विधि में बहुत समय लगता है, इसलिए इसका अक्सर उपयोग नहीं किया जाता है।

विशिष्ट (ज़ोनेड) चयन नमूनाकरण का एक प्रकार है, जिसमें सामान्य जनसंख्या को एक निश्चित संकेत पर सजातीय समूहों में विभाजित किया जाता है। कभी-कभी शोधकर्ता समूहों के बजाय अन्य शर्तों का उपयोग करते हैं: "जिलों" और "जोन्स"। फिर, प्रत्येक समूह से यादृच्छिक क्रम में, कुल कुल योग में समूह के विशिष्ट वजन के अनुपात में इकाइयों की एक निश्चित संख्या का चयन किया जाता है। विशिष्ट चयन अक्सर कई चरणों में किया जाता है।
सीरियल चयन एक विधि है जिसमें इकाइयों का चयन समूह (श्रृंखला) द्वारा किया जाता है और चयनित समूह (श्रृंखला) की सभी इकाइयां सर्वेक्षण के अधीन होती हैं। इस विधि का लाभ यह है कि कभी-कभी एक श्रृंखला की तुलना में व्यक्तिगत इकाइयों को अधिक जटिल चुनते हुए, उदाहरण के लिए, एक ऐसे व्यक्ति का अध्ययन करते समय जो वाक्य की सेवा कर रहा है। चयनित क्षेत्रों के ढांचे के भीतर, जोन अपवाद के बिना सभी इकाइयों के अध्ययन को लागू करते हैं, उदाहरण के लिए, कुछ विशेष संस्थानों में एक वाक्य की सेवा करने वाले सभी व्यक्तियों का अध्ययन।
नमूना
नमूना या चुनिंदा कुल - अध्ययन में भाग लेने के लिए सामान्य आबादी से चुने गए एक निश्चित प्रक्रिया का उपयोग करके कई मामले (विषयों, वस्तुओं, घटनाओं, नमूने)।
नमूनाकरण विशेषताएं:
- नमूना की गुणात्मक विशेषता - जो हम वास्तव में चुनते हैं और नमूने बनाने के किस तरीके के लिए हम इसका उपयोग करते हैं।
- नमूना की मात्रात्मक विशेषता - अन्य शब्दों में, नमूने के आकार में कितने मामले चुनते हैं।
नमूना की आवश्यकता
- अध्ययन का उद्देश्य बहुत व्यापक है। उदाहरण के लिए, वैश्विक कंपनी के उत्पादों के उपभोक्ताओं को भूख से बिखरे हुए बाजारों की एक बड़ी संख्या है।
- प्राथमिक जानकारी एकत्र करने की आवश्यकता है।
सैम्पलिंग
सैम्पलिंग - चुनिंदा सेट में शामिल मामलों की संख्या। सांख्यिकीय विचारों से यह अनुशंसा की जाती है कि मामलों की संख्या कम से कम 30-35 थी।
आश्रित और स्वतंत्र नमूने
दो (या अधिक) नमूने की तुलना करते समय, एक महत्वपूर्ण पैरामीटर उनकी निर्भरता है। यदि आप एक होमोमोर्फिक जोड़ी स्थापित कर सकते हैं (यानी, एक मामला, एक मामला, एक नमूना एक्स और इसके विपरीत) प्रत्येक मामले में प्रत्येक मामले में प्रत्येक मामले में (और यह रिश्ते का आधार विशेषता विशेषता के लिए महत्वपूर्ण है) नमूने कहा जाता है आश्रित। आश्रित नमूने के उदाहरण:
- जुड़वां जोड़े
- प्रायोगिक प्रभाव से पहले और बाद में किसी भी संकेत के दो माप,
- पति और पत्नी
- आदि।
यदि नमूने के बीच ऐसा कोई संबंध नहीं है, तो इन नमूनों पर विचार किया जाता है स्वतंत्र, उदाहरण:
तदनुसार, आश्रित नमूने हमेशा एक ही राशि रखते हैं, और स्वतंत्र की मात्रा भिन्न हो सकती है।
नमूना तुलना विभिन्न सांख्यिकीय मानदंडों का उपयोग करके बनाई गई है:
- और आदि।
प्रातिनिधिकता
नमूना को एक प्रतिनिधि या अविश्वसनीय माना जा सकता है।
एक अप्रत्याशित नमूने का एक उदाहरण
- विभिन्न स्थितियों में किए गए प्रायोगिक और नियंत्रण समूहों के साथ अध्ययन करें।
- एक जोड़ी चयन रणनीति की भागीदारी के साथ प्रयोगात्मक और नियंत्रण समूहों के साथ अनुसंधान
- केवल एक समूह का उपयोग करके अध्ययन - प्रायोगिक।
- एक मिश्रित (कारक) योजना का उपयोग करके अध्ययन - सभी समूहों को विभिन्न स्थितियों में रखा गया है।
नमूना के प्रकार
नमूने दो प्रकारों में विभाजित हैं:
- संभाव्य
- अविश्वसनीय
संभाव्य नमूनों
- सरल संभाव्य नमूना:
- सरल बार-बार नमूना। इस तरह के नमूने का उपयोग इस धारणा पर आधारित है कि संभाव्यता के बराबर हिस्से के साथ प्रत्येक प्रतिवादी नमूना में पड़ सकता है। सामान्य आबादी की सूची के आधार पर, कार्ड उत्तरदाताओं की संख्याओं के साथ तैयार किए जाते हैं। उन्हें एक डेक में रखा जाता है, मिश्रित और कार्ड उनसे हटा दिया जाता है, संख्या दर्ज की जाती है, फिर वापस लौटती है। इसके बाद, प्रक्रिया की जरूरत के रूप में कई बार दोहराया जाता है। माइनस: चयन इकाइयों की पुनरावृत्ति।
एक साधारण यादृच्छिक नमूने के निर्माण के लिए प्रक्रिया में निम्नलिखित कदम शामिल हैं:
1. सामान्य आबादी के सदस्यों की पूरी सूची और इस सूची की संख्या प्राप्त करना आवश्यक है। ऐसी सूची, हमें याद है, नमूना का आधार कहा जाता है;
2. अनुमानित नमूना आकार निर्धारित करें, यानी उत्तरदाताओं की अपेक्षित संख्या;
3. यादृच्छिक संख्याओं की तालिका से निकालें जितनी संख्याएं हमें नमूना इकाइयों की आवश्यकता होती है। यदि 100 लोगों को नमूना में होना चाहिए, तो तालिका से 100 यादृच्छिक संख्याएं ली गई हैं। इन यादृच्छिक संख्याओं को कंप्यूटर प्रोग्राम द्वारा उत्पन्न किया जा सकता है।
4. सूची-आधारित उन अवलोकन से चुनें, जिनकी संख्या निर्वहन यादृच्छिक संख्या के अनुरूप है
- एक साधारण यादृच्छिक नमूना में स्पष्ट फायदे हैं। यह विधि समझने में बेहद आसान है। अध्ययन के परिणामों को अध्ययन के लिए वितरित किया जा सकता है। सांख्यिकीय निष्कर्षों को प्राप्त करने के अधिकांश दृष्टिकोण में एक साधारण यादृच्छिक नमूना का उपयोग करके जानकारी एकत्र करना शामिल है। हालांकि, एक साधारण यादृच्छिक नमूना विधि में कम से कम चार महत्वपूर्ण सीमाएं हैं:
1. अवलोकन नमूना का आधार बनाना अक्सर मुश्किल होता है, जो एक साधारण यादृच्छिक नमूना की अनुमति देगा।
2. एक साधारण यादृच्छिक नमूने के उपयोग का परिणाम एक बड़ी कुलता हो सकता है, या एक बड़े भौगोलिक क्षेत्र द्वारा वितरित एक कुशलता हो सकती है, जो डेटा संग्रह के समय और लागत को काफी बढ़ाती है।
3. एक साधारण यादृच्छिक नमूने के उपयोग के परिणाम अक्सर अन्य संभाव्य तरीकों के उपयोग के परिणामों की तुलना में कम सटीकता और अधिक मानक त्रुटि की विशेषता होती हैं।
4. एसआरएस के उपयोग के परिणामस्वरूप, एक अविश्वसनीय नमूना बनाया जा सकता है। यद्यपि नमूने एक साधारण यादृच्छिक चयन द्वारा प्राप्त किए गए हैं, औसत सामान्य आबादी का पर्याप्त रूप से प्रतिनिधित्व करते हैं, उनमें से कुछ पूरी तरह से अध्ययन की कुलता का प्रतिनिधित्व करते हैं। इसकी संभावना एक छोटे नमूने के साथ विशेष रूप से बड़ी है।
- सरल समग्र नमूना। नमूना निर्माण प्रक्रिया एक जैसी है, केवल उत्तरदाताओं के साथ कार्ड डेक पर वापस नहीं लौटे हैं।
- व्यवस्थित संभाव्य नमूना। यह सरल संभाव्य नमूना का एक सरलीकृत संस्करण है। एक निश्चित अंतराल (के) के बाद सामान्य कुल की सूची के आधार पर, उत्तरदाताओं का चयन किया जाता है। मान संयोग से निर्धारित किया जाता है। सबसे विश्वसनीय परिणाम एक सजातीय सामान्य आबादी के साथ हासिल किया जाता है, अन्यथा चरण का संयोग और नमूनाकरण (नमूनाकरण) के कुछ आंतरिक चक्रीय पैटर्न संभव है। विपक्ष: एक साधारण संभाव्य नमूना के समान।
- सीरियल (घोंसला) नमूना। चयन इकाइयां सांख्यिकीय श्रृंखला (परिवार, स्कूल, ब्रिगेड, आदि) हैं। चयनित तत्व एक ठोस परीक्षा के अधीन हैं। सांख्यिकीय इकाइयों का चयन यादृच्छिक या व्यवस्थित नमूने के प्रकार से व्यवस्थित किया जा सकता है। माइनस: सामान्य जनसंख्या की तुलना में अधिक समानता की संभावना।
- ज़ोन नमूना। किसी भी चयन तकनीक के साथ एक संभाव्य नमूना का उपयोग करने से पहले, एक अनौपचारिक सामान्य आबादी के मामले में, सजातीय हिस्सों के लिए सामान्य कुल को विभाजित करने की सिफारिश की जाती है, इस तरह के एक नमूने को एक ज़ोन किया जाता है। जोनिंग के समूह प्राकृतिक शिक्षा के रूप में कार्य कर सकते हैं (उदाहरण के लिए, शहर के क्षेत्र) और किसी भी संकेत, अध्ययन का आधार। संकेत, जिसके आधार पर अलगाव किया जाता है, को बंडल और ज़ोनिंग का संकेत कहा जाता है।
- "आरामदायक" नमूना। "सुविधाजनक" नमूना प्रक्रिया "सुविधाजनक" नमूना इकाइयों के साथ संपर्क स्थापित करना है - छात्रों के समूह, एक खेल टीम, दोस्तों और पड़ोसियों के साथ। यदि आपको लोगों की एक नई अवधारणा के बारे में जानकारी प्राप्त करने की आवश्यकता है, तो यह नमूना काफी न्यायसंगत है। प्रश्नावली का पूर्व-परीक्षण करने के लिए अक्सर "सुविधाजनक" नमूना का उपयोग किया जाता है।
अविश्वसनीय नमूने
इस तरह के नमूने में चयन मौके के सिद्धांतों के अनुसार नहीं किया जाता है, लेकिन व्यक्तिपरक मानदंडों के अनुसार - अभिगम्यता, विशिष्ट, समान प्रतिनिधित्व आदि।
- क्वाड नमूना - नमूना एक मॉडल के रूप में बनाया गया है जो सामान्य जनसंख्या की संरचना को पुन: उत्पन्न करता है जो अध्ययन के संकेतों के कोटा (अनुपात) के रूप में (अनुपात) के रूप में पुन: उत्पन्न करता है। अध्ययन सुविधाओं के विभिन्न संयोजन के साथ नमूना तत्वों की संख्या इस तरह की गणना के साथ निर्धारित की जाती है ताकि यह सामान्य आबादी में अपने हिस्से (अनुपात) से मेल खाती है। उदाहरण के लिए, यदि सामान्य सेट में हमारे पास 5,000 लोग हैं, तो 2,000 महिलाएं और 3,000 पुरुष हैं, फिर कोटा नमूने में हमारे पास 20 महिलाएं और 30 पुरुष, या 200 महिलाएं और 300 पुरुष होंगे। उद्धृत नमूने अक्सर जनसांख्यिकीय मानदंडों पर आधारित होते हैं: लिंग, आयु, क्षेत्र, आय, शिक्षा और अन्य। विपक्ष: आमतौर पर ऐसे नमूने अप्रतिबंधित होते हैं, क्योंकि आप कई सामाजिक मानकों को ध्यान में नहीं रख सकते हैं। पेशेवरों: आसानी से सुलभ सामग्री।
- स्नोबॉल की विधि। नमूना निम्नानुसार बनाया गया है। प्रत्येक प्रतिवादी, पहले से शुरू होता है, अपने दोस्तों, सहयोगियों, परिचितों के संपर्कों से पूछता है जो चयन की शर्तों के लिए उपयुक्त होंगे और अध्ययन में भाग ले सकते हैं। इस प्रकार, पहले चरण के अपवाद के साथ, नमूना वस्तुओं की भागीदारी के साथ गठित किया जाता है। विधि का अक्सर उपयोग किया जाता है जब उत्तरदाताओं के हार्ड-टू-रीच समूहों को ढूंढना और साक्षात्कार करना आवश्यक होता है (उदाहरण के लिए, उच्च आय वाले उत्तरदाताओं, एक पेशेवर समूह से संबंधित उत्तरदाताओं, उत्तरदाताओं जिनके पास कोई भी समान शौक / शौक आदि है। )
- सहज नमूना तथाकथित "पहला काउंटर" का एक नमूना है। अक्सर टेलीविजन और रेडियो सितारों में उपयोग किया जाता है। प्राकृतिक नमूनों का आकार और संरचना अग्रिम में नहीं जानती है, और केवल एक पैरामीटर द्वारा निर्धारित किया जाता है - उत्तरदाताओं की गतिविधि। विपक्ष: यह स्थापित करना असंभव है कि सामान्य साक्षात्कार का एक सेट क्या है, और नतीजतन - प्रतिनिधित्वशीलता को निर्धारित करने में असमर्थता।
- यदि अध्ययन की एकता परिवार है तो मार्ग सर्वेक्षण का अक्सर उपयोग किया जाता है। समझौते के मानचित्र पर जिसमें सर्वेक्षण किया जाएगा, सभी सड़कों को गिना जाता है। यादृच्छिक संख्याओं की तालिका (जेनरेटर) की मदद से, बड़ी संख्याओं का चयन किया जाता है। प्रत्येक बड़ी संख्या को 3 घटकों के रूप में देखा जाता है: सड़क की संख्या (2-3 पहली संख्या), घर की संख्या, अपार्टमेंट संख्या। उदाहरण के लिए, संख्या 14832: 14 मानचित्र पर सड़क संख्या है, 8 - हाउस नंबर, 32 - अपार्टमेंट रूम।
- ठेठ वस्तुओं के चयन के साथ एक ज़ोन नमूना। यदि, ज़ोनिंग के बाद, प्रत्येक समूह से एक सामान्य वस्तु का चयन किया जाता है, यानी। ऑब्जेक्ट जो अध्ययन में अध्ययन की गई अधिकांश विशेषताओं के लिए औसत संकेतकों तक पहुंचता है, ऐसे नमूने को एक प्रकार के सामान्य ऑब्जेक्ट्स-ज़ोन कहा जाता है।
6. मॉडल नमूना। 7. विशेषज्ञ नमूना। 8.Getherogenic नमूना।
भवन समूहों के लिए रणनीतियाँ
मनोवैज्ञानिक प्रयोग में उनकी भागीदारी के लिए समूहों का चयन आंतरिक और बाहरी वैधता के साथ अधिकतम संभावित अनुपालन सुनिश्चित करने के लिए आवश्यक विभिन्न रणनीतियों का उपयोग करके किया जाता है।
यादृच्छिकीकरण
यादृच्छिकीकरण, या यादृच्छिक चयनसरल यादृच्छिक नमूने बनाने के लिए उपयोग किया जाता है। इस तरह के नमूने का उपयोग इस धारणा पर आधारित है कि समान संभावना के साथ आबादी का प्रत्येक सदस्य नमूना में पड़ सकता है। उदाहरण के लिए, 100 विश्वविद्यालय के छात्रों का एक यादृच्छिक नमूना बनाने के लिए, आप एक टोपी में सभी विश्वविद्यालय के छात्रों के नामों के साथ कागजात को फोल्ड कर सकते हैं, और फिर उस से 100 टुकड़े प्राप्त कर सकते हैं - यह एक यादृच्छिक चयन होगा (गुडविन जे।, पी। 147)।
जोड़ना
जोड़ना - नमूना समूहों के निर्माण के लिए रणनीति, जिसमें विषयों के समूह साइड पैरामीटर द्वारा प्रयोग के लिए महत्वपूर्ण विषयों के बराबर विषयों से संकलित किए जाते हैं। यह रणनीति एक बेहतर विकल्प के साथ प्रयोगात्मक और नियंत्रण समूहों का उपयोग करके प्रयोगों के लिए प्रभावी है - जुड़वां जोड़े (मोनो- और डायलिंग) को आकर्षित करना, क्योंकि यह आपको बनाने की अनुमति देता है ...
पैशमेट्रिक चयन
पैशमेट्रिक चयन - स्ट्रैटम (या क्लस्टर) के आवंटन के साथ यादृच्छिकरण। नमूना बनाने की इस विधि के साथ, सामान्य सेट को कुछ विशेषताओं (लिंग, आयु, राजनीतिक वरीयताओं, शिक्षा, आय स्तर, आदि) के साथ समूहों (स्ट्रेट) में विभाजित किया गया है, और विषयों को संबंधित विशेषताओं के साथ चुना जाता है।
अनुमानित मॉडलिंग
अनुमानित मॉडलिंग - सीमित नमूनों को चित्रित करना और व्यापक आबादी पर इस नमूने के बारे में निष्कर्षों को सारांशित करना। उदाहरण के लिए, विश्वविद्यालय के दूसरे वर्ष के छात्रों के अध्ययन में भागीदारी के साथ, इस अध्ययन का डेटा "17 से 21 वर्ष की आयु के लोगों" पर लागू होता है। ऐसी सामान्यीकरण की अनुमतता बेहद सीमित है।
अनुमानित मॉडलिंग - एक मॉडल का गठन जो कि सिस्टम (प्रक्रियाओं) की स्पष्ट रूप से निर्दिष्ट वर्ग है, स्वीकार्य सटीकता के साथ इसके व्यवहार (या आवश्यक घटना) का वर्णन करता है।
टिप्पणियाँ
साहित्य
ह्रेनोव ए डी। मनोवैज्ञानिक अनुसंधान के गणितीय तरीके। - एसपीबी।: भाषण, 2004।
- इलियासोव एफएन। सर्वेक्षण की प्रतिनिधित्व विपणन अध्ययन // सामाजिक अनुसंधान में परिणाम देता है। 2011. № 3. पी। 112-116।
यह सभी देखें
- कुछ प्रकार के शोध में, नमूना समूहों में विभाजित है:
- प्रयोगात्मक
- नियंत्रण
- जत्था
लिंक
- नमूनाकरण की अवधारणा। नमूना की मुख्य विशेषताएं। नमूना के प्रकार
विकिमीडिया फाउंडेशन। 2010।
समानार्थक शब्द:- शचेपकिन, मिखाइल सेमेनोविच
- सामान्य समग्र
देखें अन्य शब्दकोशों में "नमूना" क्या है:
नमूना - एक निश्चित आबादी का प्रतिनिधित्व करने वाले विषयों का एक समूह और प्रयोग या शोध के लिए चुना गया। विपरीत अवधारणा सामान्य का एक सेट है। नमूना सामान्य की कुलता का हिस्सा है। एक व्यावहारिक मनोवैज्ञानिक का शब्दकोश। एम।: एएसटी, ... ... बिग साइकोलॉजिकल एनसाइक्लोपीडिया
नमूना - अवलोकन द्वारा कवर किए गए तत्वों के सामान्य संयोजन का नमूना हिस्सा (इसे अक्सर चुनिंदा सेट कहा जाता है, और नमूना स्वयं चुनाव विधि है)। गणितीय आंकड़ों में, अपनाया ... ... तकनीकी अनुवादक निर्देशिका
नमूना - (नमूना) 1. अपनी सभी संख्या का प्रतिनिधित्व करने के लिए चुने गए सामानों की एक छोटी राशि। देखें: नमूना द्वारा बिक्री। 2. संभावित खरीदारों को प्रेषित वस्तुओं की एक छोटी मात्रा उन्हें खर्च करने का मौका देने के लिए ... ... व्यवसाय शर्तें शब्दकोश
नमूना - अवलोकन द्वारा कवर किए गए तत्वों के सामान्य संयोजन का हिस्सा (इसे अक्सर चुनिंदा सेट कहा जाता है, और नमूना स्वयं चुनिंदा अवलोकन की विधि है)। गणितीय आंकड़ों में, यादृच्छिक चयन के सिद्धांत को अपनाया जाता है; यह है… … अर्थशास्त्र और गणितीय शब्दकोश
नमूना - (नमूना) मुख्य समुच्चय से तत्वों के उपसमूह का मनमाना चयन, जिनकी विशेषताओं को पूरी तरह से पूरी तरह से आकलन करने के लिए उपयोग किया जाता है। चुनिंदा विधि का उपयोग किया जाता है जब पूरे सेट की जांच करने के लिए बहुत लंबा या बहुत महंगा ... आर्थिक शब्दकोश
नमूना - से। मी … समानार्थी शब्द