أحكام الاختبار الأساسي. الأحكام الرئيسية للنظرية الكلاسيكية للاختبارات
ما هو الاختبار
وفقا ل IEEE STD 829-1983 اختبارات - هذه عملية لتحليل البرنامج الرامي لتحديد الاختلافات بين خصائصها الحالية والمطلوبة بالفعل (عيب) وتقييم خصائص البرامج.
وفقا ل GOST R ISO IEC 12207-99 في دورة حياة البرامج، من بين العمليات الإضافية الأخرى للتحقق، يتم تحديد الشهادات والتحليل المشترك والمراجعة. عملية التحقق هي عملية تحديد أن منتجات البرمجيات تعمل بشكل كامل مع المتطلبات أو الشروط المنفذة في الأعمال السابقة. قد تتضمن هذه العملية تحليل وتحقق واختبار (اختبار). عملية الشهادة هي عملية تحديد اكتمال امتثال المتطلبات القائمة التي أنشأها النظام أو المنتج البرمجيات لتكون مقصودها الوظيفي. عملية التحليل المشترك هي عملية تقييم الدول، وإذا لزم الأمر، نتائج العمل (المنتجات) في المشروع. عملية التدقيق هي عملية تحديد الامتثال لمتطلبات خطط وشروط العقد. في مقدار هذه العمليات ويشكل ما يسمى عادة الاختبار.
يعتمد الاختبار على إجراءات الاختبار مع بيانات الإدخال المحددة والظروف الأولية والنتيجة المتوقعة التي تم تطويرها لغرض محدد، مثل التحقق من برنامج منفصل أو التحقق من الامتثال لمتطلبات معينة. يمكن إجراء إجراءات الاختبار التحقق من جوانب مختلفة من البرنامج - من التشغيل السليم لوظيفة منفصلة قبل تنفيذ متطلبات الأعمال الكافية.
عند تنفيذ مشروع، من الضروري أن تأخذ في الاعتبار، وفقا للمعايير وما سيتم اختبار المتطلبات من قبل المنتج. ما هي الأدوات التي ستكون (إذا كانت هناك) تستخدم للبحث والعيوب التي تم العثور عليها. إذا كنت تتذكر الاختبار من بداية المشروع، فإن اختبار المنتج الذي يجري تطويره لن يقدم مفاجآت غير سارة. لذلك، من المحتمل أن تكون جودة المنتج مرتفعة للغاية.
دورة حياة المنتج والاختبار
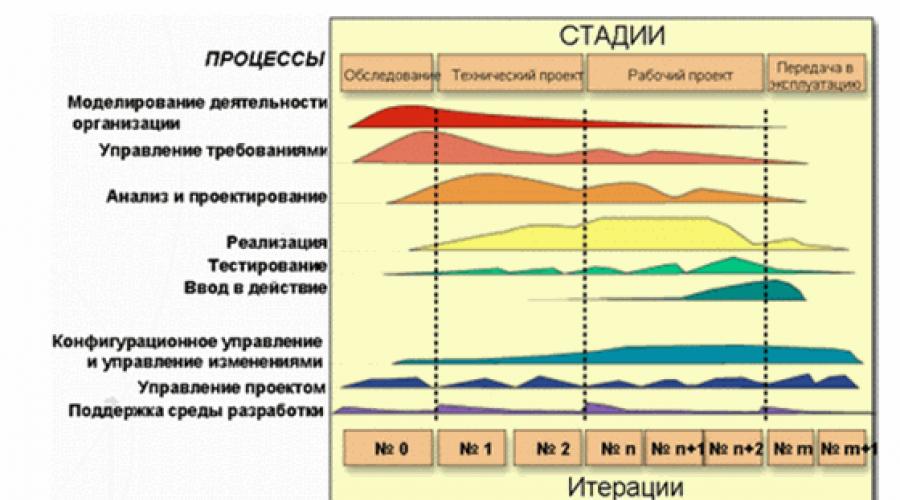
في وقتنا، يتم استخدامه من خلال عمليات تكرارية لتطوير البرمجيات، على وجه الخصوص، التكنولوجيا RUP - عملية موحدة عقلانية(رسم بياني 1). عند استخدام هذا النهج، يتوقف الاختبار عن أن تكون عملية "مخيط"، والتي تعمل بعد كتب المبرمجين جميع التعليمات البرمجية اللازمة. تبدأ العمل على الاختبارات بالمرحلة الأولية ذات الأبدية لتحديد متطلبات المنتج المستقبلي ويدمج عن كثب مع المهام الحالية. ويجعل متطلبات جديدة للمختبرين. لا يتم تقليل دورهم فقط لتحديد الأخطاء بأكمله قدر الإمكان وأحيانا قدر الإمكان. يجب أن يشاركون في العملية الشاملة لتحديد مخاطر المشروع وإلغاء القضاء عليها. لهذا الغرض، يتم تحديد الغرض من الاختبار والأساليب لتحقيقه لكل تكرار. وفي نهاية كل تخصيص يتم تحديد مقدار تحقيق هذا الهدف إذا كانت هناك حاجة إلى اختبارات إضافية، وما إذا كان من الضروري تغيير المبادئ وأدوات الاختبار. بدوره، يجب أن يمر كل عيب بالكشف عبر دورة حياته.
تين. 1. دورة حياة المنتج على RUP
عادة ما يتم إجراء الاختبار بواسطة دورات، لكل منها قائمة محددة بالمهام والأغراض. قد تتزامن دورة الاختبار مع التكرار أو تتوافق مع جزءها المحدد. عادة، يتم تنفيذ دورة الاختبار لتجميع نظام معين.
تتكون دورة حياة منتج البرنامج من سلسلة من التكرارات القصيرة نسبيا (الشكل 2). التنفيذ هو دورة تطوير كاملة تؤدي إلى إصدار المنتج النهائي أو بعض إصدارها المختصر، مما يتوسع من التكرار للتكرار بحيث يصبح في النهاية نظاما نهائيا.
يتضمن كل تكرار، كقاعدة عامة، مهام تخطيط العمل وتحليلها وتصميمها وتنفيذها واختبارها وتقييمها للنتائج المحققة. ومع ذلك، فإن نسب هذه المهام يمكن أن تتغير بشكل كبير. وفقا لنسبة مختلف المهام في التكرار، يتم تجميعها في مراحل. في المرحلة الأولى - البداية - يتم إيلاء الاهتمام الرئيسي لمهام التحليل. في تكرار المرحلة الثانية - التنمية - يركز التركيز على تصميم واختبار قرارات المشروع الرئيسية. في المرحلة الثالثة - البناء هو حصة كبيرة من مهام التطوير والاختبار. وفي المرحلة الأخيرة - إرسال النقل - يتم حلها إلى أعلى مهام اختبار ونقل النظام إلى العميل.

تين. 2. تكرارات دورة حياة المنتج البرمجيات
تتمتع كل مرحلة بأهدافها الخاصة في دورة حياة المنتج وتعتبرها عند تحقيق هذه الأهداف. جميع التكرارات، باستثناء قد تكون، يتم الانتهاء من تكرارات بداية المرحلة من خلال إنشاء إصدار عمل من النظام الذي يجري تطويره.
فئات الاختبار
تختلف الاختبارات اختلافا كبيرا في المهام التي يتم حلها بمساعدتها، وفقا للتقنية المستخدمة.
| فئات الاختبار | وصف الفئات | أنواع الاختبار |
|---|---|---|
| الاختبار الحالي | مجموعة من الاختبارات التي أجريت لتحديد أداء الميزات الجديدة الإضافية للنظام. |
|
| اختبار الانحدار | الغرض من اختبار الانحدار هو التحقق من أن إضافة النظام لم تقلل من قدراتها، أي. يتم الاختبار وفقا للمتطلبات التي تم إكمالها بالفعل قبل إضافة ميزات جديدة. |
|
الفئة الفرعية الاختبار
| الفئة الفرعية الاختبار | وصف نوع الاختبار | اختبارات فرعية |
|---|---|---|
| اختبار الإجهاد | يتم استخدامه لاختبار الجميع دون استثناء وظائف التطبيق. في هذه الحالة، لا يهم تسلسل اختبار الوظيفة. |
|
| اختبار دورات الأعمال | يتم استخدامه لاختبار وظائف التطبيق في تسلسل دعوتهم من قبل المستخدم. على سبيل المثال، تقليد جميع الإجراءات المحاسبية للربع الأول. |
|
| اختبار الإجهاد |
تستخدم لاختبار أداء التطبيق. الغرض من هذا الاختبار هو تحديد إطار التشغيل المستقر للتطبيق. مع هذا الاختبار، يتم استدعاء جميع الوظائف المتاحة. |
|
أنواع الاختبار
وحدة التجارب (الاختبار المعياري) - هذا النوع يعني اختبار وحدات التطبيق الفردية. للحصول على الحد الأقصى للنتيجة، يتم إجراء الاختبار في وقت واحد مع تطوير الوحدات النمطية.
الاختبار الوظيفي - الغرض من هذا الاختبار هو ضمان الأداء المناسب لكائن الاختبار. يتم اختبار التنقل بشكل صحيح على كائن، وكذلك الإدخال والمعالجة وإخراج البيانات.
اختبار قاعدة البيانات - تحقق من أداء قاعدة البيانات مع التشغيل العادي للتطبيق، في لحظات الوضع الزائد والتشغيل المتعدد.
وحدة التجارب
بالنسبة إلى OOP، تتمثل التنظيم المعتاد في الاختبارات المعيارية في اختبار طرق كل فصل، ثم فئة كل حزمة I.T.D. تدريجيا، ننتقل إلى اختبار المشروع بأكمله، والاختبارات السابقة هي نوع الانحدار.
في واجبات الإخراج، تتضمن بيانات الاختبار إجراءات الاختبار، وبيانات الإدخال، واختبار تنفيذ التعليمات البرمجية، والإخراج. فيما يلي نوع من وثائق الإخراج.
الاختبار الوظيفي
يتم التخطيط للاختبار الوظيفي لكائن الاختبار ويتم تنفيذه على أساس متطلبات الاختبار المحددة في مرحلة التعريف. المتطلبات هي قواعد العمل، واستخدام مخططات الحالة، ووظائف العمل، وكذلك إذا كانت هناك مخططات النشاط. الغرض من الاختبارات الوظيفية هو التحقق من امتثال متطلبات مكونات الرسومات المتقدمة.
لا يمكن أن يكون هذا النوع من الاختبارات مؤتمتة بالكامل. وبالتالي، يتم تقسيمها إلى:
- الاختبار الآلي (سيتم استخدامه في الحالة حيث يمكنك التحقق من معلومات الإخراج).
الغرض: اختبار المدخلات ومعالجة وإخراج البيانات؛
- الاختبار اليدوي (في حالات أخرى).
الغرض: اختبارات صحة تنفيذ متطلبات المستخدم.
من الضروري تنفيذ (اللعب) لكل حالة من استخدام القيم المؤمنية، وذلك باستخدام كل من القيم المؤمنة والخطئ بشكل واضح، لتأكيد الأداء الصحيح، وفقا للمعايير التالية:
- يستجيب المنتج بشكل كاف لجميع البيانات المدخلة (يتم عرض النتائج المتوقعة استجابة للبيانات التي تم إدخالها بشكل صحيح)؛
- يستجيب المنتج بشكل كاف للبيانات التي تم إدخالها بشكل غير صحيح (تظهر رسائل الخطأ المناسبة).
اختبار قاعدة البيانات
الغرض من هذا الاختبار هو التأكد من أن أساليب الوصول إلى قواعد البيانات موثوقة، في تنفيذها الصحيح، دون تعطيل سلامة البيانات.
يجب أن تستخدم باستمرار الحد الأقصى لعدد من الطعون إلى قاعدة البيانات. يتم استخدام نهج، حيث يتم تجميع الاختبار بطريقة "تحميل" قاعدة مع تسلسل، وقيم مخلصة ومن الواضح. يتم تحديد استجابة قاعدة البيانات على إدخال البيانات، وتقدر الفواصل الزمنية لمعالجتها.
الفصل 3. نتائج اختبار المعالجة الإحصائية
يسمح المعالجة الإحصائية لنتائج الاختبار من ناحية، وحدد موضوعيا نتائج الموضوعات، من ناحية أخرى - لتقييم جودة الاختبار نفسه، ومهام الاختبار، لا سيما تقييم موثوقيتها. يتم دفع مشكلة الموثوقية الكثير من الاهتمام في النظرية الكلاسيكية للاختبارات. هذه النظرية لم تفقد أهميتها والآن. على الرغم من المظهر، فإن النظريات الحديثة أكثر، تواصل النظرية الكلاسيكية الحفاظ على موقفها.
3.1. الأحكام الرئيسية للنظرية الكلاسيكية للاختبارات
3.2. نتائج اختبار مصفوفة
3.3. عرض الرسوم البيانية لنقاط الاختبار
3.4. اتخاذ تدابير الميل المركزية
3.5. التوزيع الطبيعي
3.6. اختبار نقاط اختبار التشتت
3.7. مصفوفة الارتباط
3.8. اختبار الموثوقية
3.9. اختبار الصلاحية
المؤلفات
الأحكام الرئيسية للنظرية الكلاسيكية للاختبارات
خالق النظرية الكلاسيكية للاختبارات (النظرية الكلاسيكية للاختبارات العقلية) هو عالم نفسي بريطاني معروف، مؤلف تحليل العامل، التحديال إدوارد سبيرمان (1863-1945) 1. ولد في 10 سبتمبر 1863، وتم تقديم ربع حياته في الجيش البريطاني. لهذا السبب، حصل على درجة الطبيب في الفلسفة فقط في سن 41 2. تم إجراء دراسة أطروحة للأقرف في مختبر علم النفس التجريبي في ولاية لايبزيغ بموجب إرشادات فيلهلم Wundt (Wilhelm Wundt). في تلك الفترة، كان فرانسيس جالتون (فرانسيس جالتون) تأثيرا قويا على CH.Pirman (فرانسيس جالتون) لاختبار الذكاء البشري. partspirman من التلاميذ كانوا R.Catell و d.wechsler. من بين أتباعه، A.Anastasi، J. P. Guilford، P.Vernon، C.Burt، A.Jensen يمكن استدعاء.
مساهمة كبيرة في تطوير النظرية الكلاسيكية للاختبارات صنع لويس جوتمان، 1916-1987) 3.
بشكل شامل ومليء للنظرية الكلاسيكية للاختبارات للمرة الأولى مبينة في العمل الأساسي ل Harold Gullixen (Gulliksen H.، 1950) 4. منذ ذلك الحين، تم تحسين النظرية إلى حد ما، ولا سيما الجهاز الرياضي قد تم تحسينه. ترد نظرية الاختبارات الكلاسيكية في العرض التقديمي الحديث في كتاب كروكر L.، Aligna J. (1986) 5. من الباحثين المحليين، لأول مرة، تم إعطاء وصف هذه النظرية v.avalesis (1989) 6. في عمل Chelyowkova M.B. (2002) 7 يوفر معلومات عن الإثارة الإحصائية لجودة الاختبار.
تعتمد نظرية الاختبار الكلاسيكية على المناصب الرئيسية الخمسة التالية.
1. نتيجة القياس التي تم الحصول عليها تجريبيا (x) هي مجموع نتيجة القياس الحقيقية (T) وأخطاء القياس (E) 8:
X \u003d T + E (3.1.1)
عادة ما تكون القيم T و E غير معروفة.
2. يمكن التعبير عن نتيجة القياس الحقيقية كوقعات رياضية E (X):
3. ارتباط المكونات الحقيقية والخاطئة وفقا لمجموعة من الموضوعات هو الصفر، وهذا هو، ρ te \u003d 0.
4. المكونات الخاطئة من اثنين من الاختبارات لا ترتبط:
5. لا ترتبط المكونات الخاطئة للاختبار واحد بالمكونات الحقيقية لأي اختبار آخر:
بالإضافة إلى ذلك، فإن أساس النظرية الكلاسيكية للاختبارات هو تعريفان - موازي واختبارات معادلة.
يجب أن تكون الاختبارات الموازية تمتثل للمتطلبات (1-5)، يجب أن تكون المكونات الحقيقية للاختبار واحد (T 1) مساوية للمكونات الحقيقية للاختبار آخر (T 2) في كل عينة من الاختبارات التي تستجيب لكلا الاختبارين. يفترض أن T 1 \u003d T 2، بالإضافة إلى ذلك، تساوي التشتت S 1 2 \u003d S 2 2.
يجب أن تتطلب الاختبارات المكافئة من المتطلبات بأكملها من الاختبارات الموازية باستثناء واحد: لا يجب أن تكون المكونات الحقيقية للاختبار واحد مساويا للمكونات الحقيقية للاختبار الموازي الآخر، ولكن يجب أن تختلف على نفس الثابت. من عند.
يتم تسجيل حالة التكافؤ للاختبارين في النموذج التالي:
حيث C 12 هو ثابت الاختلافات في نتائج الاختبارات الأولى والثانية.
بناء على الأحكام المذكورة أعلاه، فإن نظرية موثوقية الاختبار هي 9.10.
وهذا هو، فإن تشتت نقاط الاختبار التي تم الحصول عليها تساوي مجموع تشتت المكونات الحقيقية والخاطئة.
أعد كتابة هذا التعبير على النحو التالي:
 (3.1.3)
(3.1.3)
الجانب الأيمن من هذه المساواة هو موثوقية الاختبار ( رديئة). وبالتالي، يمكن كتابة موثوقية الاختبار في النموذج:
بناء على هذه الصيغة، كانت هناك تعبيرات لاحقة لإيجاد عامل موثوقية الاختبار. موثوقية الاختبار هي خاصيةها الحاسمة. إذا كانت الموثوقية غير معروفة، فلا يمكن تفسير نتائج الاختبار. تميز موثوقية الاختبار دقةها كأداة قياس. عالية الموثوقية تعني التكرار العالي لنتائج الاختبار في نفس الشروط.
في نظرية الاختبار الكلاسيكية، فإن المشكلة الأكثر أهمية هي تحديد نقطة الاختبار الحقيقية للموضوع (ر). يعتمد نقطة الاختبار التجريبية (X) على العديد من الحالات - مستوى صعوبة المهام، ومستوى استعداد الموضوعات، وعدد المهام، وشروط إجراء الاختبار، إلخ. في مجموعة من الموضوعات القوية المدربة تدريبا جيدا، ستكون نتائج الاختبار عادة أفضل. مما كانت عليه في المجموعة المعدة ضعيفة. وفي هذا الصدد، لا تزال مسألة حجم صعوبة المهام على عامة السكان في الموضوعات مفتوحة. تكمن المشكلة في حقيقة أن البيانات التجريبية الحقيقية يتم الحصول عليها ليس في جميع عينات عشوائية من الموضوعات. كقاعدة عامة، هذه مجموعات تعليمية، والتي تعد العديد من الطلاب من التفاعل بقوة فيما بينهم في عملية التعاليم والطلاب في الظروف التي غالبا ما تتكرر لمجموعات أخرى.
تجد ق ه من المعادلة (3.1.4)
![]()
يدل هنا صراحة اعتماد دقة القياس من قيمة الانحراف المعياري. s X. ومن موثوقية الاختبار رديئة.
تختلف مجالات التطبيق والأهداف ومهام الاختبار، لذلك يتم تقدير الاختبار وتمضح بطرق مختلفة. في بعض الأحيان، يصعب شرح المختبرين أنفسهم في شرح ما هو اختبار "كما هو". هناك ارتباك.
للكشف عن هذا الارتباك، Alexey Barancers (الممارسة والمدرب والاستشاري في اختبار البرمجيات؛ يتنبأ المغادرة من معهد برمجة نظام الأكاديمية الروسية في الأكاديمية الروسية) تدريبه على اختبار الفيديو التمهيدي حول الاختبارات الرئيسية للاختبار.
يبدو لي أنه في هذا التقرير، يمكن للمحاضر أن يشرح أكثر كفاية وبكاء "ما يختبر" من وجهة نظر العالم والمبرمج. من الغريب أن هذا النص لم يظهر بعد في Habré.
استشهد هنا برمجة مضغوطة لهذا التقرير. في نهاية النص هناك روابط في النسخة الكاملة، وكذلك الفيديو المذكور.
المناصب الرئيسية للاختبار
زملائي الأعزاء،أولا، دعونا نحاول فهم ما لا يختبر.
اختبار عدم التنمية,
حتى إذا كان الاختبار قادرين على البرنامج، بما في ذلك الاختبارات (اختبار الأتمتة \u003d البرمجة)، يمكن تطوير بعض البرامج المساعدة (لأنفسهم).
ومع ذلك، فإن الاختبار ليس أنشطة تطوير البرمجيات.
الاختبار ليس تحليلا,
وليس لجمع وتحليل المتطلبات.
على الرغم من ذلك، في عملية الاختبار، في بعض الأحيان عليك توضيح المتطلبات، وأحيانا يكون لديك لتحليلها. لكن هذا النشاط ليس هو الرئيسي، بدلا من ذلك، من الضروري القيام به فقط إذا لزم الأمر.
اختبار عدم الإدارة,
على الرغم من حقيقة أنه في العديد من المنظمات، هناك مثل هذا الدور مثل "مدير الاختبار". بالطبع، يجب إدارة المختبرين. ولكن في حد ذاته لا يتم التحكم فيه.
الاختبار ليس المشاركة الفنية,
ومع ذلك، يتعين على المختبرين توثيق اختباراتهم وعملهم.
لا يمكن اعتبار الاختبار أي من هذه الأنشطة ببساطة لأنه في عملية تطوير (أو تحليل المتطلبات، أو كتابة وثائق للاختبارات) يقوم الاختبار بكل هذا العمل لنفسكليس لشخص آخر.
الأنشطة التي معنى فقط عندما تكون في الطلب، أي أن أصحاب الاختبار يجب أن ينتج شيئا "للتصدير". ماذا يفعلون "للتصدير"؟
العيوب أو الأوصاف العيوب أو تقارير الاختبار؟ جزئيا صحيح.
ولكن هذه ليست الحقيقة كلها.
نشاط النشاط الرئيسي
من أنها توفر المشاركين في المشروع لتطوير ردود فعل سلبية البرمجيات على جودة المنتج البرمجيات."ردود فعل سلبية" لا تحمل بعض صبغة سلبية، ولا تعني أن حاملي الاختبار يقومون بشيء سيء، أو أنهم يفعلون شيئا سيئا. إنه مجرد مصطلح تقني يعني شيئا بسيطا إلى حد ما.
لكن هذا الشيء مهم للغاية، وربما العنصر الوحيد الأكثر أهمية في أنشطة المختبرين.
هناك علم - "نظرية النظام". يحدد هذا المفهوم ك "ردود الفعل".
"ردود الفعل" هي بعض البيانات التي يتم إصدارها مرة أخرى إلى المدخلات، أو جزء من البيانات، والتي من الخروج تعود إلى المدخلات. هذه الملاحظات يمكن أن تكون إيجابية وسالبة.
والآخر، والأصناف الأخرى من الملاحظات مهمة بنفس القدر.
في تطوير أنظمة البرمجيات مع ردود فعل إيجابية، بالطبع، هي بعض المعلومات التي نتلقاها من المستخدمين النهائيين. هذه هي طلبات لبعض الوظائف الجديدة، هذه الزيادة في المبيعات (إذا نستخدم منتجا عالي الجودة).
ردود الفعل السلبية يمكن أن تأتي أيضا من المستخدمين النهائيين في شكل بعض المراجعات السلبية. إما أنها يمكن أن تأتي من المختبرين.
يتم توفير التعليقات السلبية السابقة، فإن الطاقة الأقل ضرورية لتعديل هذه الإشارة. هذا هو السبب في أنك تحتاج إلى البدء في البدء في أقرب وقت ممكن، في المراحل الأولى من المشروع، وتوفير هذه الملاحظات وفي مرحلة التصميم، وكذلك، ربما في وقت سابق، في مرحلة جمع وتحليل المتطلبات.
بالمناسبة، ومن هنا فإن الفهم الذي لا يختبرون غير مسؤولين عن الجودة. أنها تساعد أولئك المسؤولين عنه.
مرادفات مصطلح "اختبار"
من وجهة نظر حقيقة أن الاختبار هو توفير ردود فعل سلبية، اختصار ضمان الجودة الشهير عالميا (الإنجليزية. ضمان الجودة ضمان الجودة) مرادف للمصطلح "الاختبار" ليس بالتأكيد بالضبط.من المستحيل النظر في ضمان الجودة تقديم ملاحظات سلبية، لأن الحكم هو بعض التدابير الإيجابية. من المفهوم أنه في هذه الحالة نحن نقدم الجودة، في الوقت المناسب نتخذ بعض التدابير بحيث زادت جودة تطوير البرامج.
ولكن "مراقبة الجودة" - مراقبة الجودة، يمكن اعتبارها بمعنى واسع من خلال مرادف للمصطلح "الاختبار"، لأن مراقبة الجودة وهذا هو توفير ردود فعل في مجموعة واسعة من أصنافها، في مراحل مختلفة من أصنافها مشروع البرنامج.

في بعض الأحيان يكون الاختبار هو بعض أشكال مراقبة الجودة منفصلة.
الارتباك يأتي من تاريخ الاختبار. في أوقات مختلفة، كان الهدف من مصطلح "الاختبار" من الإجراءات المختلفة التي يمكن تقسيمها إلى فئتين كبيرتين: خارجي وداخلي.
التعاريف الخارجية
تعاريف أنه في أوقات مختلفة أعطيت Myers، Beyser، Kaner، وصف الاختبار من وجهة نظر أهميتها الخارجية. وهذا هو، من وجهة نظرهم، الاختبار هو نشاط مخصص لشيء ما، ولا يتكون من شيء ما. يمكن تعميم جميع هذه التعريفات الثلاثة كتعليقات سلبية.التعاريف الداخلية
هذه هي التعريفات التي يتم تقديمها في معيار المصطلحات المستخدمة في هندسة البرمجيات، على سبيل المثال، في Standard De Facto يسمى Swebok.تتم شرح هذه التعريفات بشكل بناء، وهي أنشطة اختبار، ولكن لا تعطي أي فكرة أنه من الضروري اختبار كل نتائج التحقق من الامتثال بين السلوك الفعلي للبرنامج وسيكون سلوكها المتوقع.
الاختبار هو
- تحقق من امتثال متطلبات البرنامج
- نفذت من خلال مراقبة عملها
- في المواقف الخاصة التي تم إنشاؤها بشكل مصطنع تختار بطريقة معينة.

إجمالي مخطط الاختبار تقريبا كما يلي:
- يستقبل اختبار المدخلات برنامج و / أو متطلبات.
- يفعل شيئا معهم، يشاهد عمل البرنامج في المواقف المعقدة التي أنشأتها.
- عند الإخراج، يتلقى معلومات حول المراسلات والتناقضات.
- بعد ذلك، يتم استخدام هذه المعلومات لتحسين البرنامج الموجود بالفعل. إما من أجل تغيير متطلبات برنامج آخر يجري تطويره.
ما هو الاختبار
- هذا هو موقف خاص، تم إنشاؤه بشكل مصطنع اختيار بطريقة معينة،
- وصف ما يلزم القيام به عن ملاحظات البرنامج
- للتحقق من امتثالها مع بعض المتطلبات.
يشارك مطور الاختبار في حقيقة أنه من اختبار كبير لا حصر له في الاختبارات اختيار بعض مجموعة محدودة.
حسنا، لذلك يمكننا أن نستنتج أن الفاحص يفعل شيئين في عملية الاختبار.
1. أولا، يدير تنفيذ البرنامج ويخلق هذه المواقف الاصطناعية التي سنحقق فيها سلوك البرنامج.
2. أنا وثانيا، هو يشاهد سلوك البرنامج ويقارن ما يراه مع ما هو متوقع.
إذا كان اختبار الأتمتة الاختبارات، فهو لا يشاهد أنفسهم سلوك البرنامج - فهو يفوض هذه المهمة بأداة خاصة أو برنامج خاص كتبه هو نفسه. إنها هي التي تلاحظ، تقارن السلوك الملحوظ مع المتوقع، ويعطي الفاحص فقط بعض النتيجة النهائية - سواء كان السلوك المرصود يتزامن مع المتوقع، أو لا يتزامن.
أي برنامج هو آلية لمعالجة المعلومات. الدخول إلى الإدخال في شكل واحد، معلومات الإخراج في شكل آخر. في الوقت نفسه، يمكن أن تكون مدخلات البرنامج والمخرجات كثيرا، يمكن أن تكون مختلفة، أي أن البرنامج يمكن أن يكون له العديد من الواجهات المختلفة، وقد يكون لهذه الواجهات أنواعا مختلفة:
- واجهة المستخدم (UI)
- واجهة البرمجيات (API)
- بروتوكول الشبكة
- نظام الملفات
- حالة البيئة
- الأحداث
- العادة
- الرسم،
- نص
- الناتئ،
- والكلام.
- بطريقة أو بأخرى يخلق مواقف اصطناعية،
- والتحقق في هذه الحالات كبرنامج يتصرف.
هذا هو الاختبار.
التصنيفات الأخرى لأنواع الاختبار
في معظم الأحيان تستخدم لتقسيم ثلاثة مستويات، وهذا- اختبار وحدات
- اختبار التكامل
- اختبار النظام.
ضمن اختبار النظام يعني الاختبار على مستوى واجهة المستخدم.
في بعض الأحيان يتم استخدام بعض المصطلحات الأخرى أيضا، مثل "اختبار المكونات"، لكنني أفضل تخصيص هؤلاء الثلاثة، بسبب حقيقة أن الفصل التكنولوجي للاختبار المعياري والنظامي لا معنى له كثيرا. على مستويات مختلفة، نفس الأدوات، يمكن استخدام نفس التقنيات. فصل مشروط.
تظهر الممارسة أن الأدوات التي يتم وضعها من قبل الشركة المصنعة كأدوات اختبار وحدات يمكن تطبيقها مع النجاح المتساوي وفي مستوى اختبار التطبيق بأكمله ككل.
والأدوات التي تختبر التطبيق بأكمله ككل على مستوى واجهة المستخدم ترغب في بعض الأحيان في البحث، على سبيل المثال، إلى قاعدة البيانات أو تسبب بعض الإجراءات المخزنة منفصلة هناك.
وهذا يعني أن الانقسام في الاختبارات النظامية والحيونية مشروطة بحتة عموما، إذا نتحدث من وجهة نظر فنية.
يتم استخدام نفس الأدوات، وهذا أمر طبيعي، يتم استخدام نفس التقنيات، في كل مستوى يمكنك التحدث عن اختبار أنواع مختلفة.
يجمع:

وهذا هو، يمكنك التحدث عن الاختبار المعياري للوظائف.
يمكنك التحدث عن اختبار الوظائف النظامية.
يمكنك التحدث عن الاختبار المعياري، على سبيل المثال، الكفاءة.
يمكنك التحدث عن الاختبارات النظامية للكفاءة.
أو نعتبر فعالية بعض الخوارزمية منفصلة، \u200b\u200bأو نعتبر فعالية النظام بأكمله ككل. وهذا هو، الفصل التكنولوجي للاختبار المعياري والنظامي لا معنى له الكثير. لأنه على مستويات مختلفة، نفس الأدوات، يمكن استخدام نفس التقنيات.
أخيرا، مع اختبار التكامل، نتحقق من ذلك، كجزء من النظام، تفاعل الوحدات مع بعضها البعض بشكل صحيح. وهذا هو، نحن فعلا تنفيذ نفس الاختبارات كما هو الحال في اختبار النظام، فقط إيلاء الاهتمام لكيفية تفاعل الوحدات مع بعضها البعض. أداء بعض الشيكات الإضافية. هذا هو الفرق الوحيد.
دعونا نحاول مرة أخرى محاولة فهم الفرق بين الاختبارات النظامية والحيونية. منذ أن تم العثور على هذا الفصل في كثير من الأحيان، يجب أن يكون هذا الاختلاف.
وهذا الاختلاف يتجلى عندما لا نقوم بتصنيف تكنولوجي، ولكن التصنيف بواسطة الأهداف اختبارات.
التصنيف للأغراض مريحة للأداء باستخدام "السحر السحري"، الذي اخترعه أصلا براين مارك ثم تحسين تانين إيري.

في هذه السحر السحري، توجد جميع أنواع الاختبارات في أربعة أرباع، اعتمادا على ما يركز عليه الاهتمام أكثر في هذه الاختبارات.
عموديا - كلما ارتفعت نوع الاختبار، كلما تم إيلاء المزيد من الاهتمام لبعض المظاهر الخارجية لسلوك البرنامج، فإن انخفاضه هو، كلما زاد اهتمامها بجهازها التكنولوجي الداخلي للبرنامج.
أفقيا - تقع اختباراتنا اليسرى، والمزيد من الاهتمام الذي ندفعها لهم للبرمجة، كلما زاد أهميتهم، كلما زاد عدد الاهتمام الذي ندفعه للحصول على الاختبار اليدوي والبحث عن البرنامج من قبل شخص.
على وجه الخصوص، في هذا المربع، يمكنك بسهولة إدخال هذه الشروط كاختبار القبول، واختبار القبول، والاختبار المعياري على وجه التحديد في هذا الفهم الذي يستخدم فيه غالبا في الأدب. هذا اختبار منخفض المستوى مع كبير، مع حصة ساحقة من البرمجة. وهذا يعني أن جميع الاختبارات مبرمجة، يتم تنفيذها تلقائيا بالكامل يتم تنفيذها في المقام الأول إلى الجهاز الداخلي للبرنامج، فهي ميزاتها التكنولوجية.
في الزاوية اليمنى العليا، سيكون لدينا اختبارات يدوية تهدف إلى السلوك الخارجي للبرنامج، على وجه الخصوص، اختبار سهولة الاستخدام، وفي الزاوية اليمنى السفلى، قدمنا \u200b\u200bعلى الأرجح من خلال خصائص مختلفة غير وظيفية: الأداء، الأمن، وهلم جرا.
لذلك، بناء على التصنيف من الأهداف، ننتقل إلى اختبار وحدات في الربع العلوي، وجميع الأرباع الأخرى لاختبار النظام.
شكرا للاهتمام.
أساسيات نظرية الاختبار
المفاهيم الأساسية لنظرية الاختبار
يتم قياس القياس أو الاختبار من أجل تحديد حالة أو قدرات رياضي عجين .
لا يمكن استخدام جميع القياسات كاختبارات، ولكن فقط تلك التي تلبي المتطلبات الخاصة. وتشمل هذه:
1. التوحيد (الإجراءات والاختبار يجب أن تكون هي نفسها في جميع حالات تطبيق الاختبار)؛
2. الموثوقية؛
3. بالمعلومات؛
4. وجود نظام التصنيف.
يتم استدعاء الاختبارات التي تلبي متطلبات الموثوقية والمعلوماتية سوبوتا أو أصلي (اليونانية. طريقة موثوقة حقيقية).
يتم استدعاء عملية الاختبار اختبارات ؛ القيمة العددية التي تم الحصول عليها نتيجة لذلك - نتائج الإختبار (أو نتيجة الاختبار). على سبيل المثال، تشغيل 100 م هو اختبار، وإجراءات تنفيذ المناسبة والتوقيت - اختبار، وقت السباق هو نتيجة الاختبار.
يتم استدعاء الاختبارات بناء على المهام المحرك محرك أو محرك وبعد يمكن أن تكون نتائجها إما إنجازات المحرك (وقت مرور المسافة، وعدد التكرار الذي تم تمريره عبر المسافة، وما إلى ذلك)، أو المؤشرات الفسيولوجية والكيميائية الحيوية.
يتم استخدامه في بعض الأحيان، ولكن العديد من الاختبارات التي لها هدف نهائي واحد (على سبيل المثال، تقييم حالة رياضي في الفترة التدريبية التنافسية). وتسمى مثل هذه المجموعة من الاختبارات معقد أو اختبار البطارية .
يجب تقديم الاختبار نفسه المطبق على نفس الدراسة في نفس الشروط التي تزامنا النتائج (إلا إذا غيروا الدراسة نفسها). ومع ذلك، مع أكثر التوحيد الصارم والمعدات الدقيقة، فإن نتائج الاختبار تختلف دائما إلى حد ما. على سبيل المثال، فإن الديمقراطية الناتجة التي أظهرت نتيجة 215 كجم في اختبار Dinalometry، مع الإعدام المتكرر يظهر فقط 190 كجم.
2. موثوقية الاختبارات وطرق تحديد
الموثوقية يسمى الاختبار درجة صدفة النتائج عند إعادة اختبار نفس الأشخاص (أو أشياء أخرى) في ظل نفس الشروط.
اختلاف النتائج عند استدعاء إعادة الاختبار داخل الفرد، أو داخل المجموعة، أو interasklass.
أربعة أسباب رئيسية تسبب هذا الاختلاف:
1. تغيير حالة الدراسة (التعب، العمل، التعلم، تغيير الدافع، تركيز الاهتمام، إلخ).
2. التغييرات غير المنضبط في الظروف والمعدات الخارجية (درجة الحرارة، الرياح، الرطوبة، الجهد في شبكة الطاقة، وجود أشخاص غير مصرح لهم، إلخ)، I.E. كل ما يجمع بين مصطلح "خطأ قياس عشوائي".
3. تغيير حالة الشخص الذي يجري أو تقييم الاختبار (، وبالطبع، استبدال مجرب واحد أو القاضي للآخرين).
4. النقص العجين (هناك مثل هذه الاختبارات غير مريح عن علم. على سبيل المثال، إذا كانت الاختبارات تؤدي رميا حرا في سلة كرة السلة، فإن لاعب كرة سلة لديه نسبة عالية من الزيارات قد يكون مخطئا بطريق الخطأ في الرمي الأول).
الفرق الرئيسي في نظرية موثوقية الاختبار على نظرية أخطاء القياس هو أنه في نظرية الخطأ، تعتبر القيمة المقاسة دون تغيير، وفي نظرية اختبارات الموثوقية يفترض أنها تتغير من القياس إلى القياس. على سبيل المثال، إذا كنت بحاجة إلى قياس نتيجة محاولة تم إجراؤها في الطول في الطول من مدرج، فلا يمكن تغييرها بشكل كبير وبمرار الوقت. بالطبع، بسبب الأسباب العشوائية (على سبيل المثال، توتر غير متكافئ من الروليت)، من المستحيل قياس هذه النتيجة بدقة مثالية (قل ما يصل إلى 0.0001 ملم). ومع ذلك، باستخدام أداة قياس أكثر دقة (على سبيل المثال، عداد الليزر)، يمكنك زيادة دقةهم إلى المستوى المطلوب. في الوقت نفسه، إذا كانت المهمة هي تحديد استعداد الطائر في مراحل معينة من دورة التدريب السنوية، فإن القياس الأكثر دقة للنتائج التي أظهرتها القليل سيساعد: بعد كل شيء، سيتغيرون من محاولة المحاولة.
للتعامل مع فكرة الأساليب المستخدمة للحكم على موثوقية الاختبارات، النظر في مثال مبسط. افترض أنك تحتاج إلى مقارنة نتائج القفزات في الطول من مكان في اثنين من الرياضيين على محاولتين مكتملتين. لنفترض أن نتائج كل من الرياضيين تختلف ضمن ± 10 سم من القيمة العادية وهي متساوية، على التوالي، 230 ± 10 سم (أي 220 و 240 سم) و 280 ± 10 سم (أي 270 و 290 سم). في هذه الحالة، ستكون الاستنتاج، بالطبع، لا لبس فيه تماما: يتجاوز الرياضي الثاني الأول (الاختلافات بين المتوسط \u200b\u200bفي 50 سم أعلى بوضوح من تذبذب عشوائي من ± 10 سم). إذا، مع وجود نفس التباين المحلي (± 10 سم)، فإن الفرق بين متوسط \u200b\u200bقيم الدراسة (اختلاف intergroup) سيكون صغيرا، ثم سيكون من الصعب تحقيق الإخراج. لنفترض أن متوسط \u200b\u200bالقيم سيكون مساويا إلى 220 سم (في محاولة واحدة - 210، في الآخر - 230 سم) و 222 سم (212 و 232 سم). في الوقت نفسه، تقفز أول مدروسة في المحاولة الأولى عند 230 سم، والثاني فقط عند 212 سم؛ ويبدو أن الأول أقوى بشكل أساسي من الثانية. من هذا المثال، يمكن أن ينظر إليه على أن القيمة الرئيسية ليست في حد ذاتها تقلب في السوق، ولكن نسبةها مع اختلافات InterClace. يمنح نفس التباين داخل الملابس موثوقية مختلفة مع اختلافات متساوية بين الفصول (في حالة معينة بين الشكل 14).
تين. 14. نسبة الاختلاف بين العروض بين المستوى الأعلى (أعلى) وموثوقية منخفضة (أقل):
السكتات الدماغية الرأسية القصيرة - بيانات المحاولات الفردية؛
متوسط \u200b\u200bنتائج الثلاثة مدروسة.
نظرية موثوقية الاختبار العائدات من حقيقة أن نتيجة أي قياس يتم إجراؤها على الشخص هو مجموع القيمتين:
حيث: - ما يسمى النتيجة الحقيقية التي يريدون إصلاحها؛
خطأ ناتج عن تغييرات لا يمكن السيطرة عليها في حالة الاختبار وأخطاء القياس العشوائية.
بموجب النتيجة الحقيقية، فإن متوسط \u200b\u200bقيمة X مع عدد كبير بلا حدود من الملاحظات في نفس الشروط (لهذا، في X وضع علامة).
إذا كانت الأخطاء عشوائية (مجموعها صفر، وفي محاولات متساوية، فلا تعتمد على بعضها البعض)، ثم من الإحصاءات الرياضية التي يتبعها:
أولئك. مسجلة في تجربة تشتت النتائج تساوي مقدار شتتات النتائج والأخطاء الحقيقية.
معامل الموثوقية يتم تسجيل نسبة التشتت الحقيقي إلى التشتت في التجربة:

بالإضافة إلى معامل الموثوقية، لا يزال يستخدم مؤشر الموثوقية:
الذي يعتبر معامل الارتباط النظري لقيم الاختبار المسجلة مع صحيح.
مفهوم النتيجة الحقيقية للاختبار هو التجريد (في التجربة، من المستحيل). لذلك، يجب عليك استخدام الأساليب غير المباشرة. الأكثر تفضيلا في تقييم تحليل تشتت الموثوقية، تليها حساب معاملات الارتباط الدخل. يسمح لك تحليل التشتت بتحلل اختلاف نتائج الاختبار إلى المكونات بسبب تأثير العوامل الفردية. على سبيل المثال، إذا قمت بتسجيل النتائج في النتائج التي تمت دراستها في أي اختبار، فكرر هذا الاختبار في أيام مختلفة، وفي كل يوم للقيام بعدة محاولات، تغيير المجربين بشكل دوري، ثم سيكون هناك اختلافات:
أ) من الموضوع إلى الموضوع؛
ب) من يوم إلى آخر؛
ج) من المجرب إلى المجرب؛
د) من محاولة للمحاولة.
تحليل التشتت يجعل من الممكن تخصيص وتقييم هذه الاختلافات.
وبالتالي، من الضروري تقدير الموثوقية العمالية للاختبار أولا، لأداء تحليل تشتت، ثانيا، حساب معامل الارتباط المعابط (النسبة الموثوقية).
مع محاولتين، تتزامن قيمة معامل الارتباط داخل الفئة عمليا بقيم معامل الارتباط المعتاد بين نتائج المحاولات الأولى والثانية. لذلك، في مثل هذه الحالات، يمكن استخدام معامل الارتباط التقليدي لتقييم الموثوقية (يقدر موثوقية واحدة وليس محاولتين).
تحدث عن موثوقية الاختبارات، من الضروري التمييز بين استقرارها (استنساخ)، الاتساق، التكافؤ.
تحت استقرار تفهم الاختبارات استنساخ النتائج عند تكرارها بعد وقت معين في نفس الشروط. الاختبار المتكرر عادة ما يسمى إعادة الاختبار.
التناسق يتميز الاختبار باستقلال نتائج الاختبار من الصفات الشخصية لشخص إجراء أو اختبار تقييم.
عند اختيار اختبار من عدد معين من اختبارات النوع نفسه (على سبيل المثال، تشغيل Sprint بنسبة 30 و 60 و 100 م) من خلال النماذج الموازية، تقدر درجة صدفة النتائج. تحسب بين نتائج معامل الارتباط النتائج نسبة التكافؤ.
إذا كانت جميع الاختبارات المدرجة في أي نوع من الاختبارات معادلة للغاية، فإنه يسمى المتجانسة. هذا التدابير المجمع بأكمله أحد ممتلكات الحركة الإنسانية (على سبيل المثال، معقد يتكون من القفز من مكان في الطول، أعلى وثلاثية؛ يقدر مستوى تطوير الصفات الأمنية عالية السرعة). إذا لم تكن هناك اختبارات معادلة في المجمع، فهذا هو، فإن الاختبارات المدرجة فيها تقاس خصائص مختلفة، ثم يسمى غير متجانسة (على سبيل المثال، معقد يتكون من أن يصبح دينامومومتريا، قفز Acalac، يعمل لكل 100 م).
يمكن زيادة موثوقية الاختبار إلى حد ما عن طريق:
أ) التوحيد الأكثر صرامة لاختبار؛
ب) زيادة عدد المحاولات؛
ج) زيادة عدد المثمنين (القضاة والتجارب) وتحسين تماسك آرائهم؛
د) زيادة عدد الاختبارات المكافئة؛
ه) أفضل الدافع للدراسة.
مثال 10.1.
تحديد موثوقية نتائج القفز الثلاثي من المكان الوارد في تقييم السرعة وقدرات الطاقة الرياضيين في سباق Sprint، إذا كانت هذه العينات كما يلي:
قرار:
1. تطبيق نتائج الاختبار على جدول العمل: 
2. نحن نحل محل النتائج التي تم الحصول عليها في صيغة الحساب لمعامل ترتيب المرتبة:

3. نحدد عدد درجات الحرية من خلال الصيغة:
انتاج |: وبالتالي فإن قيمة التسوية الناتجة هي بالتالي، بثقة في 99% يمكننا أن نقول أن اختبار القفز الثلاثي موثوق.
يحتوي المكون الأول، نظرية الاختبارات، على وصف لنماذج معالجة بيانات التشخيص الإحصائية. فيما يلي نماذج تحليل الإجابات في مهام الاختبار ونموذج حساب نتائج الاختبار الإجمالية. MELLENBERG (1980، 1990) اتصل به "التمثيل النفسية". نظرية الاختبار الكلاسيكية، نظرية الاختبار الحديثة (أو نموذج تحليل الإجابات لاختبار المهام - IRT) ونموذج
تعوض عينات المهمة أهم ثلاثة أنواع من نماذج نظرية الاختبار. موضوع PsychodiaStics هو النموذجين الأولين.
نظرية الاختبار الكلاسيكية. بناء على هذه النظرية، تم تطوير معظم الاختبارات الفكرية والشخصية. المفهوم المركزي لهذه النظرية هو مفهوم "الموثوقية". بموجب الموثوقية من المفهوم بأنه تماسك نتائج أثناء إعادة التقييم. في الكتيبات المرجعية، عادة ما يكون هذا المفهوم موجزا للغاية، ثم يتم تقديم وصف تفصيلي لجهاز الإحصاءات الرياضية. في هذا، تم استهلاك الفصل، الفصل، وسنقدم وصفا مضغوط للقيمة الرئيسية للمفهوم المذكور. في نظرية الاختبار الكلاسيكية، موثوقة هو تكرار نتائج العديد من إجراءات القياس (القياسات بشكل رئيسي مع الاختبارات). ينطوي مفهوم الموثوقية على حساب خطأ القياس. يمكن تمثيل النتائج التي تم الحصول عليها أثناء عملية الاختبار كمجموع خطأ حقيقي وخطأ القياس:
شي \u003d TI.+ EJ.
أين Xi.- تقييم النتائج التي تم الحصول عليها، TI هي نتيجة حقيقية، و EJ.- خطأ في القياس.
تقييم النتائج التي تم الحصول عليها هي، كقاعدة عامة، عدد الإجابات الصحيحة على مهام الاختبار. يمكن اعتبار النتيجة الحقيقية تقييما حقيقيا في الشعور الأفلاطوني (Gulliksen، 1950). مفهوم النتائج المتوقعة واسع الانتشار، أي تمثيل النقاط التي يمكن الحصول عليها نتيجة لعدد كبير من تكرار إجراءات القياس (الرب & نوفيش، 1968). لكن تنفيذ نفس إجراء التقييم مع شخص واحد غير ممكن. لذلك، تحتاج إلى البحث عن حلول أخرى للمشكلة (Witlman، 1988).
في إطار هذا المفهوم، يتم إجراء بعض الافتراضات بالنسبة إلى النتائج الحقيقية وأخطاء القياس. يتم قبول هذا الأخير كعامل مستقل، والذي، بالطبع، هو افتراض حقيقي الأسس، لأن تقلبات عشوائية في النتائج لا تعطي الأغنياء: ص ذلك \u003d 0.
من المفترض أن الارتباط بين العشرات الحقيقية وأخطاء القياس غير موجود: ص ee \u003d 0.
الخطأ الكلي هو 0، لأن كتقدير حقيقي، يتم أخذ المعنى الحسابي:
هذه الافتراضات تقودنا كنتيجة لتعريف معين للموثوقية كنسبة من النتيجة الحقيقية لتشتت أو تعبير مشترك: 1 ناقص العلاقة، حيث رقم خطأ القياس، وفي القاسم - التشتت الإجمالي:
 ، أو
، أو 
من هذا التعريف الصيغة للموثوقية، نحصل على خطأ التشتت S 2 (ه)إنه يساوي التشتت الكلي بين الحالات (1 - r xx ")؛ وبالتالي، يتم تحديد خطأ القياس القياسي بواسطة الصيغة:
![]()
بعد الإثارة النظرية للموثوقية ومشتقاتها، من الضروري تحديد مؤشر الموثوقية للاختبار. هناك إجراءات عملية لتقييم موثوقية الاختبار، مثل استخدام النماذج القابلة للتبديل (الاختبارات الموازية)، وتقسيم المهام إلى قسمين، وإعادة اختبار وقياس الاتساق الداخلي. يحتوي كل دليل على مؤشرات التحمل لنتائج الاختبار:
r xx '\u003d r (x 1، x 2)
أين r xx - معامل الاستقرار، و x 1. و × 2 - نتائج الأبعادين.
تم تقديم مفهوم موثوقية النماذج القابلة للتبديل وتطويره من قبل Gullixen (1950). هذا الإجراء رائع للغاية، لأنه يرتبط بالحاجة إلى إنشاء سلسلة متوازية من المهام.
r xx '\u003d r (x 1، x 2)
أين r xx - معامل التكافؤ، و x 1. و × 2 - اثنين من الاختبارات الموازية.
الإجراء التالي هو تقسيم الاختبار الرئيسي إلى قسمين A و B أكثر بساطة الاستخدام. ترتبط المؤشرات التي تم الحصول عليها على كلا جزأين الاختبار. بمساعدة صيغة سبيرمان براون، تقدر موثوقية الاختبار ككل ما يلي:
حيث و ب - قطعتين متوازيين من الاختبار.
الطريقة التالية هي تعريف الاتساق الداخلي لمهام الاختبار. تستند هذه الطريقة إلى تعريف Covariants من المهام الفردية. SG - تشتت الوظيفة المختارة بشكل تعسفي، و SGH - التباين من المهام المحددة بشكل تعسفي. يعد المعامل الأكثر استخداما لتحديد الاتساق الداخلي هو "معامل ألفا" Kronbach. تستخدم الصيغة أيضا KR20 و λ-2(Lambda-2).
في المفهوم الكلاسيكي للموثوقية، يتم تحديد أخطاء القياس الناشئة في عملية الاختبار وعملية الملاحظات. تختلف مصادر هذه الأخطاء: قد تكون هذه أيضا ميزات شخصية وميزات ظروف الاختبار ومهام الاختبار نفسها. هناك طرق محددة لحساب الأخطاء. نحن نعلم أن ملاحظاتنا قد تكون خاطئة، فإن الصكوك المنهجية لدينا هي ناقصة بنفس الطريقة التي يعتبرها الأشخاص أنفسهم ناقص. (كيف لا تتذكر شكسبير: "أنت غير موثوق به، اسمه شخصا"). حقيقة أنه في المقياس الكلاسيكي لاختبارات خطأ القياس هو شروير وموضح هو نقطة إيجابية مهمة.
تتمتع نظرية الاختبار الكلاسيكية بعدد من الميزات الأساسية التي يمكن اعتبارها عيوبها. تتم الإشارة إلى بعض هذه الخصائص في الكتب المرجعية، لكن معناها (من وجهة نظر كل يوم) تم التأكيد بشكل غير متوقع بشكل غير منتظم، لا ينبغي اعتبارها أوجه القصور من وجهة نظر النظرية أو المنهجية.
أولا. تركز نظرية الاختبار الكلاسيكية ومفهوم الموثوقية على حساب إجمالي مؤشرات الاختبار، والتي هي نتيجة إضافة تقديرات تم الحصول عليها في مهام منفصلة. لذلك، عند العمل
ثانية. ينطوي عامل الموثوقية على تقييم تباين المؤشرات المقاسة. يتبع أن عامل الموثوقية سيكون أقل إذا كان (مع المساواة بين المؤشرات الأخرى) هو أكثر تتجانسا. لا يوجد معامل واحد من الاتساق الداخلي لمهام الاختبار، وهذا المعامل هو دائما "السياق". كروكر والديجينا (1986)، على سبيل المثال، تقدم صيغة خاصة "تصحيح لعينة متجانسة" مخصصة لأعلى وأقل النتائج التي تم الحصول عليها عن طريق الاختبار. بالنسبة للتشخيص، من المهم معرفة خصائص الاختلافات في مجموعة العينة، وإلا فلن تكون قادرا على استخدام معاملات الاتساق الداخلي المحدد في دليل هذا الاختبار.
ثالث. ظاهرة المعلومات حول المؤشر الحسابي المتوسط \u200b\u200bهي نتيجة منطقية للمفهوم الكلاسيكي للموثوقية. إذا كان التقييم في الاختبار يتقلب (أي، فلا موثوق به بما فيه الكفاية)، فمن الممكن تماما عند تكرار الإجراء، فإن الموضوعات التي لها مؤشرات منخفضة ستتلقى نقاط أعلى، والعكس صحيح، مواضيع ذات مؤشرات عالية منخفضة. لا يمكن أن يخطئ هذا القطع الأثرية لإجراءات القياس بسبب تغيير حقيقي أو مظاهر عمليات التطوير. ولكن في الوقت نفسه delimit لهم ليس بالأمر السهل، ل لا يمكنك القضاء على إمكانية التغيير أثناء التطوير. للحصول على ثقة كاملة، من الضروري "المقارنة مع مجموعة التحكم.
تتميز الخصائص الرابعة بالاختبارات المتقدمة وفقا لمبادئ النظرية الكلاسيكية وجود بيانات تنظيمية. تسمح المعرفة بقواعد الاختبار للباحث بتفسير نتائج الاختبار بشكل مناسب. خارج القاعدة، تقدر تقديرات الاختبار من المعنى. تطوير معايير الاختبار هو مؤسسة باهظة الثمن إلى حد ما، لأن عالم النفس يجب أن يتلقى نتائج اختبار في عينة تمثيلية.
2 J. Ter Laak
إذا تحدثنا عن أوجه القصور في المفهوم الكلاسيكي للموثوقية، فإن بيان SIY Tsma مناسب هنا (1992، ص. 123-125). يلاحظ أن الأول والأكثر أهمية للنظرية الكلاسيكية للاختبارات هو أن نتائج الاختبار تخضع للمبدأ الفاصل. ومع ذلك، لا توجد بحث يؤكد هذا الافتراض ليس كذلك. في الواقع، هو "القياس على قاعدة ثابتة بشكل تعسفي." تضع هذه الميزة النظرية الكلاسيكية للاختبارات في وضع أقل ملاءمة مقارنة بموازين القياس، وبالطبع مقارنة بنظرية الاختبار الحديثة. تعتمد العديد من طرق تحليل البيانات (تحليل التشتت. تحليل الانحدار، الارتباط وتحليل العوامل) على وجود مقياس الفاصل الزمني. ومع ذلك، ليس له مبرر قوي. النظر في حجم النتائج الحقيقية كوسيلة من قيم الخصائص النفسية (على سبيل المثال، والقدرات الحسابية، والذكاء العصبي العصبي) لا يمكن إلا أن تكون مفترضة فقط.
الملاحظة الثانية تتعلق بنتائج الاختبار من الاختبار - هذه ليست مؤشرات مطلقة لأحد أو خصائص نفسية أو أخرى للاختبار، يجب أن تعتبر فقط نتيجة لتنفيذ اختبار. قد تنطبق اختباراتان على دراسة نفس الخصائص النفسية (على سبيل المثال، الاستخبارات، والقدرات اللفظية، الاستنباط، ولكن هذا لا يعني أن هذه الاختبارات هي ما يعادلان وتمتلك نفس القدرات. مقارنة مؤشرات شخصين تم اختباره من خلال اختبارات مختلفة بشكل غير صحيح. الأمر نفسه ينطبق على ملء اختبارات مختلفة مع موضوع واحد. يشير الملاحظة الثالثة إلى افتراض أن خطأ القياس المعياري هو نفسه فيما يتعلق بأي مستوى من القدرات الفردية المقاسة. ومع ذلك، لا يوجد أي تحقق تجريبي لهذا الافتراض. لذلك، على سبيل المثال، لا يوجد أي ضمان تم اختباره مع قدرات رياضية جيدة عند العمل مع اختبار حسابي بسيط نسبيا سيحصل على نقاط عالية. في هذه الحالة، سيكون الشخص ذو القدرات المنخفضة أو المتوسطة موضع تقدير كبير.
في إطار نظرية الاختبارات الحالية أو نظرية التحليل في مهام الاختبار، يتم وصف الوصف في كبير
عدد نماذج الاستجابؤ المحتملة للمستجيبين. تختلف هذه النماذج في افتراضات الأساس، وكذلك متطلبات البيانات التي تم الحصول عليها. غالبا ما يعتبر نموذج راشا مرادفا لنظريات تحليل الاستجابة في مهام الاختبار (1RT). في الواقع، هذه مجرد واحدة من النماذج. الصيغة الممثلة لها لوصف منحنى المهمة المميزة G هي كما يلي:

أين g.- مهمة منفصلة من الاختبار؛ eJR- وظيفة التعرض (الاعتماد غير الخطي)؛ δ (دلتا) - مستوى صعوبة العجين.
مهام أخرى في الاختبار، على سبيل المثال حأيضا الحصول على منحنيات خاصة بهم. شروط الحالة δ h\u003e δ g (gيعني أن حاء- مهمة أكثر صعوبة. وبالتالي، لأية قيمة للمؤشر Θ ("Theta" - الخصائص الكامنة لقدرات اختبار) احتمال المهمة الناجحة حاءأقل. يطلق عليه هذا النموذج صارما لأنه من الواضح أنه بدرجة منخفضة من الشدة، فإن احتمال المهمة قريب من الصفر. في هذا النموذج، لا يوجد مكان للتخمين والافتراضات. للمهام مع الخيارات، ليست هناك حاجة لتحقيق افتراضات حول احتمال النجاح. بالإضافة إلى ذلك، هذا النموذج صارما بمعنى أن جميع مهام الاختبار يجب أن يكون لها نفس القدرة التمييزية (انعكاس تمييزي مرتفع في حزم المنحنى؛ هنا من الممكن بناء مقياس الأمعاء تيم، وفقا لكل منها المنحنى المميز، احتمالية المهمة يتغير من ما يصل إلى 1). ولهذا السبب، لا يمكن تضمين الشروط جميع المهام في الاختبارات التي تم إنشاؤها على أساس نموذج رشا.
هناك العديد من الخيارات لهذا النموذج (على سبيل المثال، بيرنبرا، 1968، راجع اللورد آند نوفيك). يجعل وجود مهام مع تمييز مختلف
قدرة.
طورت مستكشف هولندي Mokken (1971) نماذجين لتحليل الاستجابات في مهام الاختبار، ومتطلباتها ليست صارمة للغاية كما هو الحال في نموذج الاندفاع، وبالتالي قد يكون أكثر واقعية. كما الشرط الرئيسي
يضع Viya Mokken الموقف الذي يجب أن يتبع المنحنى المميز للمهمة رتابة، دون فترات راحة. تهدف جميع مهام الاختبار في نفس الوقت إلى دراسة نفس الخصائص النفسية، والتي يجب قياسها في.يسمح بأي شكل من أشكال هذا الاعتماد حتى توقف. وبالتالي، لا يتم تحديد شكل المنحنى المميز من خلال أي وظيفة محددة. تتيح لك هذه "الحرية" استخدام المزيد من مهام الاختبار، ومستوى التقدير ليس أعلى من المعتاد.
تختلف منهجية نماذج الردود على مهام الاختبار (IRT) عن منهجية معظم دراسات التجريبية والعلاقة. تم تصميم النموذج الرياضي لدراسة الخصائص السلوكية والمعرفية والعاطفية، وكذلك ظواهر التنمية. غالبا ما تقتصر هذه الظواهر قيد النظر على الردود على المهام، والتي سمحت ليل لينبرغ (1990) بالاتصال بنظرية IRT "نظرية مصغرة حول السلوك المصغر". قد يتم تقديم نتائج الدراسة إلى حد ما حيث منحنيات الاتساق، وخاصة في الحالات التي تكون فيها الأفكار النظرية حول الخصائص المدروسة غائبة. حتى الآن، فإن تصرفنا يحتوي على وحدات اختبارات استخباراتية فقط وقدراتها واختبارات شخصية تم إنشاؤها على أساس العديد من نماذج نظرية IRT. غالبا ما تستخدم متغيرات نموذج رشا في تطوير اختبارات الإنجاز (Verhelst، 1993)، ونموذج Mockene مناسب أكثر لظواهر التنمية (انظر أيضا الفصل 6).
يتم اختبار الإجابة في مهمة الاختبار هي الوحدة الرئيسية لنماذج IRT. يتم تحديد نوع الاستجابة بدرجة شدة في البشر درس الخصائص. قد تكون هذه الخصائص، على سبيل المثال، قدرات حسابية أو مكانية. في معظم الحالات، هذا هو جانب واحد أو آخر من الذكاء أو خصائص الإنجازات أو الميزات الشخصية. من المفترض أنه بين موقف هذا الشخص بالذات في مجموعة معينة من المميزة واحتمال التنفيذ الناجح لمهمة واحدة أو مهمة، هناك اعتماد غير خطي. غير الخطية لهذا الاعتماد في إحساس معين هو بديهية. العبارات الشهيرة "أي بداية صعبة" (بطيئة
البداية الخطية) و "أصبحت مقدسة ليس بهذه البساطة"، يعني أن المزيد من التحسن بعد تحقيق مستوى معين أمر صعب. نهج المنحنى ببطء، ولكن لا يصل إلى 100٪ تقريبا من مستوى النجاح.
بعض النماذج تتعارض مع فهمنا بديهي. خذ مثل هذا المثال. يحتوي الشخص الذي لديه مؤشر مميز تعسفي من 1.5 من احتمال نجاح 60 في المائة عند أداء المهمة. هذا يتناقض مع فهمنا البديهي لمثل هذا الموقف، لأنه يمكن أن يتعامل بنجاح في المهمة، أو عدم التعامل معها على الإطلاق. خذ هذا المثال: 100 مرة يحاول الشخص أن يبلغ ارتفاعه 1m 50 سم. يرافقه النجاح 60 مرة، أي لديها احتمال 60 في المئة للنجاح.
لتقييم درجة الشدة، يجب على الخصائص مهامين على الأقل. ينفص نموذج رشا تعريف شدة الخصائص، بغض النظر عن صعوبة المهمة. كما أنه يتعارض مع فهمنا البديهي: لنفترض أن الشخص لديه احتمال 80 في المائة للقفز فوق 1.30 متر. إذا كان الأمر كذلك، فعندئذ، فإنه يتوافق مع احتمال 60 في المائة للقفز فوق 1.50 م و 40 في المئة القفز أعلاه هو 1.70 م. وبالتالي، بغض النظر عن قيمة متغير مستقل (الارتفاع)، يمكنك تقدير قدرة الشخص على القفز في الارتفاع.
هناك حوالي 50 نماذج IRT (Goldstein & Wood، 1989). هناك العديد من الوظائف غير الخطية التي تصف (شرح) احتمال نجاح النجاح في أداء مهمة أو مجموعة من المهام. متطلبات وقيود هذه النماذج مختلفة، ويمكن اكتشاف هذه الاختلافات عند مقارنة نموذج الاندفاع ومقياس الموكن. تتضمن متطلبات هذه النماذج:
1) الحاجة إلى تحديد الخصائص والتقييم المدروسة لموقف الشخص في نطاق هذه الميزة؛
2) تقييم وضع المهام؛
3) تحقق من نماذج محددة. في الطب النفسي، تم تطوير العديد من الإجراءات للتحقق من النموذج.
في بعض الكتيبات المرجعية، تعتبر نظرية IRT نموذج تحليل مهام الاختبار (انظر، على سبيل المثال،
Craker & Algina، J 986). ومع ذلك، فمن الممكن أن تدافع عن وجهة النظر أن نظرية IRT هي "نظرية مصغرة مصغرة". لاحظ أنصار نظرية IRT أنه إذا كانت مفاهيم غير كاملة (نماذج) من المستوى المتوسط، فما الذي يمكن أن يقال عن بنيات أكثر تعقيدا في علم النفس؟
نظرية الاختبار الكلاسيكية والحديثة. لا يستطيع الناس مقارنة الأشياء التي تبدو نفسها تقريبا. (ربما أي ما يعادل كل يوم للطب النفسي وتتكون أساسا في مقارنة الناس خصائص وخيارات ذات مغزى بينهما). كل نظريات مقدمة - ونظرية أخطاء التقييم، والنموذج الرياضي للاستجابات في مهام الاختبار - لديه أنصارها الخاص (Goldstein & Wood، 1986).
لا تؤدي نماذج IRT إلى التمرد في حقيقة أنه "تقييم وفقا للقواعد"، على عكس النظرية الكلاسيكية للاختبارات. يركز نموذج IRT على تحليل الخصائص المقدرة. يتم تقدير خصائص الفرد وخصائص المهام من خلال المقاييس (الترتيفية أو الفاصل). علاوة على ذلك، من الممكن مقارنة أداء الاختبارات المختلفة التي تهدف إلى تعلم خصائص مماثلة. أخيرا، فإن موثوقية غير متكافئة لكل قيمة على النطاق، ومتوسط \u200b\u200bالمؤشرات عادة ما تكون أكثر موثوقية من المؤشرات الموجودة في البداية وفي نهاية المقياس. وبالتالي، فإن نماذج IRT في العلاقات النظرية قابلة للاستبدال. هناك أيضا اختلافات في الاستخدام العملي للنظرية الحديثة للاختبارات والنظرية الكلاسيكية (SIJSTMA، 1992، ص. 127-130). الناحية النظرية الحديثة للاختبارات أكثر تعقيدا مقارنة بالكلاسيكي، لذلك فهي أقل شائعة الاستخدام من قبل غير متخصصين. علاوة على ذلك، يضع IRT متطلبات خاصة للمهام. هذا يعني أنه يجب استبعاد المهام من الاختبار إذا لم تفي بمتطلبات النموذج. تنطبق هذه القاعدة على هذه المهام التي كانت جزءا من الاختبارات المستخدمة على نطاق واسع مبني على مبادئ النظرية الكلاسيكية. يصبح الاختبار أقصر، وبالتالي يتم تقليل الموثوقية.
تقدم IRT نماذج رياضية لدراسة الظواهر الحقيقية. يجب أن تساعدنا النماذج على فهم الجوانب الرئيسية لهذه الظواهر. ومع ذلك، فإن السؤال النظري الرئيسي يكمن هنا. يمكن النظر في النماذج
نهج Watikak لدراسة الواقع المعقد الذي نعيش فيه. لكن النموذج والواقع ليس هو نفسه. وفقا لمظهر متشائم، من الممكن محاكاة أنواع السلوك الوحيدة (والمورانت غير الأكثر إثارة للاهتمام). يمكنك أيضا تلبية البيان الذي لا يخضع فيه الواقع للنماذج على الإطلاق يطيع لا يوجد قانون سببي واحد. في أحسن الأحوال، من الممكن محاكاة الظواهر السلوكية الفردية (المثالية). هناك آخر، أكثر تفاؤلا، انظر إلى إمكانية النمذجة. يمنع الموضع أعلاه إمكانية فهم عميق لطبيعة ظواهر السلوك البشري. إن استخدام نموذج معين يثير بعض الأسئلة الأكثر جوهرية. في رأينا، ليس من المشكوك فيه أن IRT هو مفهوم متفوقة نظريا ومنتقنية على النظرية الكلاسيكية للاختبارات.
الغرض العملي من الاختبارات، لأي أساس نظرية، لم يتم إنشاؤه، هو تحديد معايير كبيرة وإنشاء خصائص بعض البنيات النفسية عليها. هل نموذج IRT لديه مزايا وفي هذا الصدد؟ من المحتمل أن الاختبارات التي تم إنشاؤها على أساس هذا النموذج لا تعطي توقعات أكثر دقة مقارنة بالاختبارات التي تم إنشاؤها على أساس النظرية الكلاسيكية، ومن الممكن أن تكون مساهمتها في تطوير البنيات النفسية ليست أكثر أهمية. تفضل التشخيصات هذه المعايير التي تتعلق مباشرة بالشخص المنفصل أو المعهد أو المجتمع. نموذج، أكثر مثالية في العلاقة العلمية، "IPSO Facto" * لا يحدد معيارا أكثر ملاءمة وهو حد محدود في شرح البنيات العلمية. من الواضح أن تطوير الاختبارات القائمة على النظرية الكلاسيكية سيستمر، ولكن في الوقت نفسه سيتم إنشاء نماذج IRT جديدة، تمتد إلى دراسة عدد أكبر من الظواهر النفسية.
في نظرية الاختبار الكلاسيكية، تتميز مفاهيم "الموثوقية" و "الصلاحية". يجب أن تكون نتائج Teszeshai موثوقة، أي يجب تنسيق نتائج الاختبار الأولي وإعادة الاختبار. وعلاوة على ذلك،
* iPSO بحكم الواقع.(الورنيش) - بحد ذاته (تقريبا. عبر.).
يجب أن تكون النتائج مجانية (قدر الإمكان) من أخطاء التقييم. وجود الصلاحية هو أحد متطلبات النتائج التي تم الحصول عليها. في هذه الحالة، تعتبر الموثوقية ضرورية، ولكن ليس بعد حالة كافية لصلاحية الاختبار.
يفترض مفهوم الصلاحية أن النتائج التي تم الحصول عليها تنتمي إلى أي شيء مهم في العلاقات العملية أو النظرية. يجب أن تكون الاستنتاجات المقدمة على أساس تقديرات الاختبار صالحة. في كثير من الأحيان تحدث عن نوعين من الصلاحية: النذير (المعايير) والهيكلية. هناك أيضا أنواع أخرى من الصلاحية (انظر الفصل 3). بالإضافة إلى ذلك، يمكن تعريف الصلاحية في حالة تجربة شبه (كامبيل، 1976، كوك & شاديش، 1994). ومع ذلك، لا تزال النوع الرئيسي من الصلاحية لا تزال صلاحية النذير، والتي بموجبها من المفهوم أنها القدرة على التنبؤ بشيء كبير حول السلوك في المستقبل، وكذلك إمكانية فهم أعمق لأحد العقارات أو الجودة النفسية أو الجودة.
تتم مناقشة أنواع الصلاحية المقدمة في كل دليل وترافقها وصف لطرائق تحليل صحة الاختبار. يعد تحليل العامل أكثر ملاءمة لتحديد التحقق الهيكلي، وتستخدم معادلات الانحدار الخطي لتحليل صلاحية النذير. يمكن توقع تلك الخصائص أو غيرها من الخصائص (الأداء، وكفاءة العلاج) على أساس مؤشر واحد أو أكثر، نصف العلماء عند العمل مع الاختبارات الفكرية أو الشخصية. مثل هذه التقنيات معالجة البيانات، كترابط، الانحدار، تحليل التشتت، تحليل الارتباطات الجزئية والتشتت، تعمل على تحديد صحة النذير في الاختبار.
يصف أيضا صحة هادفة. من المفترض أن تنتمي جميع المهام والمهام في الاختبار إلى منطقة محددة (الخصائص الذهنية، السلوك، إلخ). يميز مفهوم الصلاحية الموضوعية مراسلات كل مهمة اختبار المنطقة المقاسة. يتم اعتبار الصلاحية الموضوعية في بعض الأحيان كجزء من الموثوقية أو "المعمم" (Cronbach، Gleser، Nanda & راجاراتنام، 1972). ومع ذلك
من المهم أيضا أن يكون اختيار مهام الاختبارات في مجال موضوع معين هو الاهتمام بقواعد المهمة في الاختبار.
في نظرية الاختبار الكلاسيكية، تعتبر الموثوقية والصلاحية مستقلة نسبيا عن بعضها البعض. ولكن هناك فهم آخر نسبة هذه المفاهيم. تعتمد نظرية الاختبار الحديثة على استخدام النماذج. تقدر المعلمات داخل نموذج معين. إذا كانت المهمة لا تفي بمتطلبات النموذج، فعندئذ في إطار هذا النموذج، يتم التعرف على أنه غير صالح. التحقق الهيكلي هو جزء من النموذج تحقق نفسه. يشير هذا التحقق من الصحة أساسا للتحقق من وجود خط كامن بأحد الأبعاد قيد الدراسة مع خصائص المقاييس المعروفة. سوف تستخدم الاختبارات بلا شك لتحديد المعايير المقابلة، ويمكن ارتباطها مع مؤشرات بنيات أخرى لجمع معلومات حول الصلاحية المتقاربة والمتباينة للبناء.
يشبه الألم العصبي اللغة اللغوية الموصوفة بأنها وحدة أربعة مكونات مقدمة على ثلاثة مستويات. المكون الأول، نظرية الاختبارات، على غرار بناء الجملة، قواعد اللغة. توليد (Generative) Grammar هو، من ناحية، نموذج بارع، من ناحية أخرى، النظام الذي يضعه القواعد. باستخدام هذه القواعد، يتم بناء معقدة على أساس مقترحات عاطفية بسيطة. ومع ذلك، في الوقت نفسه، يترك هذا النموذج جانبا وصفا لكيفية تنظيم عملية الاتصالات (التي تنتقل وما ينظر إليها)، ومع أي نوع من الأهداف التي يتم تنفيذها. لفهم هذا يتطلب معرفة إضافية. يمكن قول الشيء نفسه عن نظرية الاختبارات: من الضروري في المخاضرية، لكنه غير قادر على شرح أن psychodiagnoste يفعل وما هو هدفه.
1.3.2. النظريات النفسية والبناء النفسي
PsychodiaCostics هو دائما تشخيص شيء محدد: الخصائص الشخصية والسلوك والتفكير والعواطف. تهدف الاختبارات إلى تقييم الاختلافات الفردية. هناك العديد من المفاهيم
الفروق الفردية، لكل منها ميزاتها المميزة الخاصة بها. إذا تم الاعتراف بأنه لا يقتصر الأمراض المخاضرائية على تقييم الفروق الفردية، فإن نظريات أخرى ضرورية بالنسبة للأشخاص المخاضريين. مثال على تقييم الاختلافات في عمليات التنمية العقلية والاختلافات في البيئة الاجتماعية. على الرغم من أن تقييم الاختلافات الفردية ليس سمة لا غنى عنها من قبل الشباب، فهل هناك تقاليد معينة من البحث في هذا المجال. بدأت PsychodiaStics بتقييم الاختلافات الاستخبارية. كانت المهمة الرئيسية للاختبارات "تحديد انتقال العبقرية الوراثية" (جالون) أو اختيار الأطفال للتدريب (بينيت، سيمون). تلقى قياس معامل الفخذ الفهم الفهم النظري والتطوير العملي في أعمال Spirmend (المملكة المتحدة) والأرصرية (الولايات المتحدة الأمريكية). جعل ريمون B.QUTTEL هذا مشابها لتقييم الخصائص الشخصية. يصبح PsychodiaGnostics مرتبطا بفارتنم نظريات وأفكار حول الفروق الفردية في الإنجازات (تقييم القيود) وأشكال السلوك (مستوى الأداء النموذجي). لا يزال هذا التقليد يظل فعالا اليوم. في مجال التدريس عن الفوائد المخاضرية، فإن الاختلافات في البيئة الاجتماعية أقل تقدما بكثير مقارنة بعظر خصوصيات عمليات التنمية نفسها. لهذا، لا توجد تفسيرات معقولة. من ناحية، لا يقتصر التشخيص على نظريات ومفاهيم معينة. من ناحية أخرى، فإنه يحتاج إلى نظريات، لأنه على وجه التحديد في الحصول على محتوى تشخيصي (I.E. "هذا" يتم تشخيصه). على سبيل المثال، يمكن أيضا اعتبار الذكاء الخصائص العامة، وكقاعدة لمجموعة متنوعة من القدرات المستقلة. إذا أحاول الأطفال المخاضريون "ترك" من نظرية واحدة أو أخرى، فسيصبح أساس عملية التشخيص النفسي أفكار الحس السليم. تستخدم الدراسات طرق مختلفة لتحليل البيانات، ويحدد المنطق العام للأبحاث اختيار نموذج رياضي ويحدد هيكل المفاهيم النفسية المستخدمة. هذه الأساليب للإحصاء الرياضي
كي، كتحليل تشتت، تحليل الانحدار، تحليل العوامل، فإن عد الارتباطات تنطوي على وجود تبعيات خطية. في حالة الاستخدام غير الصحيح لهذه الطرق، فإنهم "إحضار" هيكل البيانات التي تم الحصول عليها والبناء المستخدمة.
الأفكار حول الاختلافات في البيئة الاجتماعية وتطوير الشخصية تقريبا لم تؤثر تقريبا على الشعونات النفسية. في الكتب المدرسية (انظر، على سبيل المثال، Murphy & Davidshofer، 1988)، يتم النظر في نظرية الاختبار الكلاسيكية ويتم مناقشة الأساليب ذات الصلة للمعالجة الإحصائية، ويتم وصف الاختبارات المعروفة، ويتم وصف استخدام الأشنوعات النفسية في الممارسة العملية: في علم النفس الإدارة، في اختيار الموظفين، في تقييم الخصائص النفسية للشخص.
تشبه نظريات الفروق الفردية (وكذلك الأفكار حول الاختلافات بين البيئة الاجتماعية والتنمية العقلية) دراسة دلالات اللغة. هذه هي الدراسة والكيان والمحتوى والقيم. يتم تنظيم القيم بطريقة معينة (مثل البنيات النفسية)، على سبيل المثال، في التشابه أو التباين (التشبيه، التقارب، الاختلاف).
1.3.3. الاختبارات النفسية والوسائل المنهجية الأخرى
المكون الثالث في الدوائر المقترحة - الاختبارات والإجراءات والوسائل المنهجية التي تم جمعها المعلومات حول خصائص الشخصية. Draza و Seitsma (1990، ص 31) إعطاء اختبارات التعريف التالية: "يعتبر الاختبار النفسي كصف وفقا لنظام معين أو كإجراء قياس يسمح لك بإجراء حكم معين حول واحد أو أكثر من مخصص تجريبيا أو أكثر خصائص معقولة من الناحية النظرية لشخص معين من السلوك البشري (لإطارات وضع الاختبار). في الوقت نفسه، يتم النظر في رد فعل المجيبين على عدد معين من الحوافز المختارة بعناية، ويتم مقارنة الردود الواردة مع معايير الاختبار ".
يتطلب التشخيص اختبارات وتقنيات لجمع معلومات موثوقة ودقيقة ومبيدة حول الميزات.
والسمات المميزة للشخص والتفكير والعواطف والسلوك البشري. بالإضافة إلى تطوير إجراءات الاختبار، يتضمن هذا المكون أيضا الأسئلة التالية: كيف يتم إنشاء الاختبارات، وكيفية تحديد الصياغة والمهام، كعائدات عملية الاختبار، ما هي متطلبات شروط الاختبار، لأن أخطاء القياس هي تؤخذ في الاعتبار، يتم احتساب نتائج الاختبار وتفسيرها.
في عملية تطوير الاختبارات، تختلف الاستراتيجيات العقلانية والتجريبية. يبدأ تطبيق استراتيجية عقلانية بتعريف المفاهيم الأساسية (على سبيل المثال، مفهوم الاستخبارات والسحب)، ووفقا لهذه الأفكار، يتم صياغة مهام الاختبار. مثال على هذه الاستراتيجية يمكن أن يكون مفهوم تحليل الجانب (نظرية الوجه) جوتمان (1957، 1968، 1978). أولا، يتم تحديد جوانب مختلفة من البند الرئيسي، ثم يتم تحديد المهام والمهام بطريقة يتم أخذ كل من هذه الجوانب في الاعتبار. الاستراتيجية الثانية هي أن المهام يتم اختيارها على أساس تجريبي. على سبيل المثال، إذا حاول الباحث إنشاء اختبار للمصالح المهنية، والذي سيسمح التمايز بين الأطباء من المهندسين، ثم يجب أن يكون الإجراء هكذا. يجب أن يتم تضمين كلا المجموعتين من المستطلعين لجميع مهام الاختبار، ويتم تضمين هذه العناصر، في الردود التي يتم اكتشاف اختلافات ذات دلالة إحصائية، في الإصدار النهائي من الاختبار. إذا كان هناك، على سبيل المثال، هناك اختلافات بين المجموعات في الردود على الموافقة على "أحب السماح"، ثم يصبح هذا البيان عنصرا في الاختبار. المركز الرئيسي لهذا الكتاب هو أن الاختبار مرتبط بنظرية مفاهيمية أو تصنيفية يحدد هذه الخصائص.
عادة ما يتم تعريف مهمة الاختبار في التعليمات لاستخدامها. يجب أن يكون الاختبار موحدا من أجل جعل من الممكن تقدير الاختلافات بين الأشخاص، وليس بين شروط الاختبار. ومع ذلك، هناك انحرافات من التقييس في الإجراءات المسماة "اختبار حدود الاحتمالات" (اختبار الحدود) واختبارات الاختبارات "الاختبار المحتملة" (تعلم الاختبارات المحتملة). في ظل هذه الظروف، فإن المستفتى هو المساعدة في هذه العملية.
الاختبار ثم تأثير مثل هذا الإجراء للنتيجة هو تقدير. عدد النقاط للحصول على إجابات للمهام هو الهدف، أي. يتم تنفيذها وفقا للإجراء القياسي. يتم تعريف تفسير النتائج التي تم الحصول عليها تماما ويتم تنفيذها على أساس معايير الاختبار.
العنصر الثالث من المخاضرات المخاضرية هو الاختبارات النفسية والأدوات والإجراءات - يحتوي على مهام معينة، وهي أدنى وحدات من المخاضرية وغير هذه الإحساس بالمهمة تشبه اللغات. عدد المجموعات المحتملة من لعبة الهاتف محدودة. يمكن أن تشكل بعض الهياكل الشديدة فقط كلمات ومقترحات لضمان المعلومات للمستمع. أيضا ومهام الاختبار: فقط في مجموعة معينة مع بعضها البعض، يمكن أن تصبح وسيلة فعالة لتقييم البناء المقابل.